Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
10,587 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
This is a clearly reproducible bug.
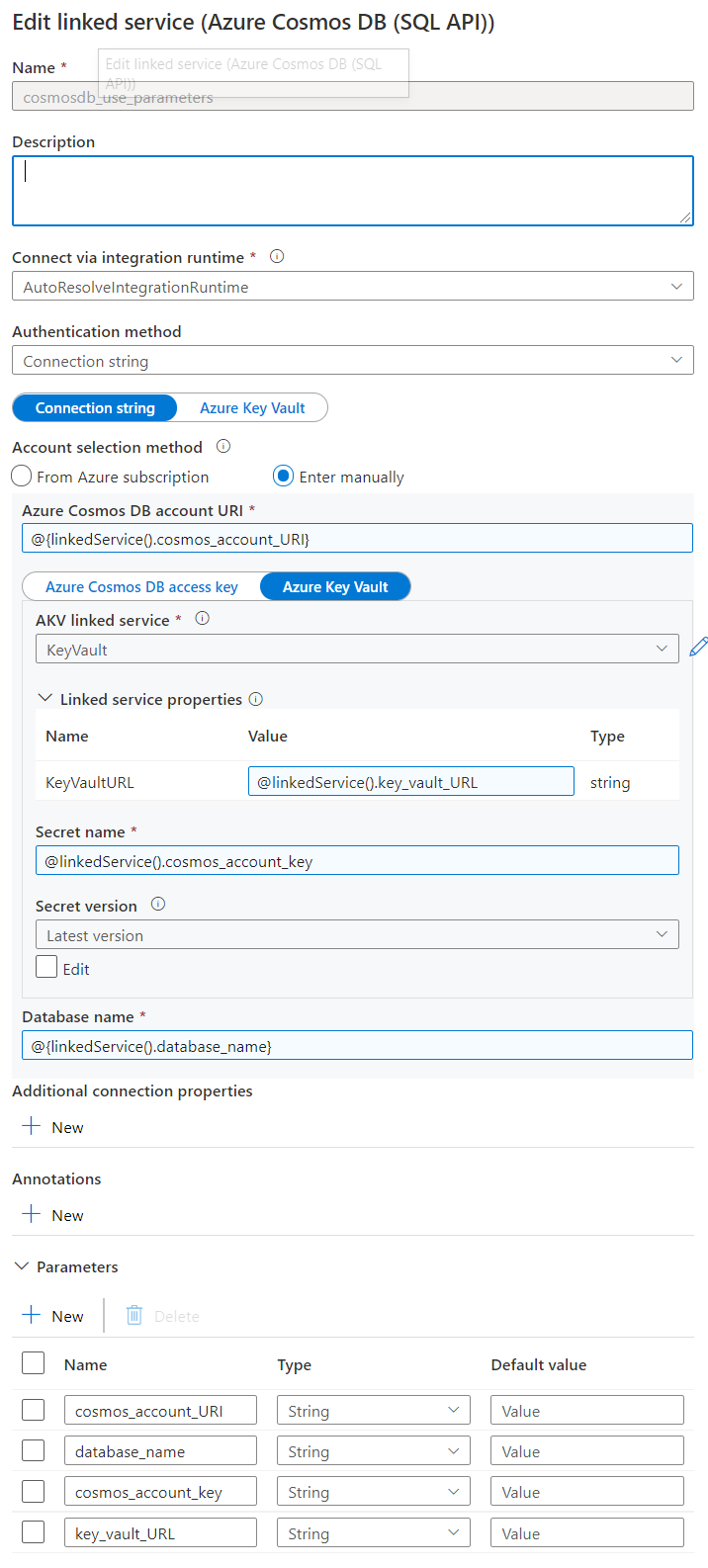
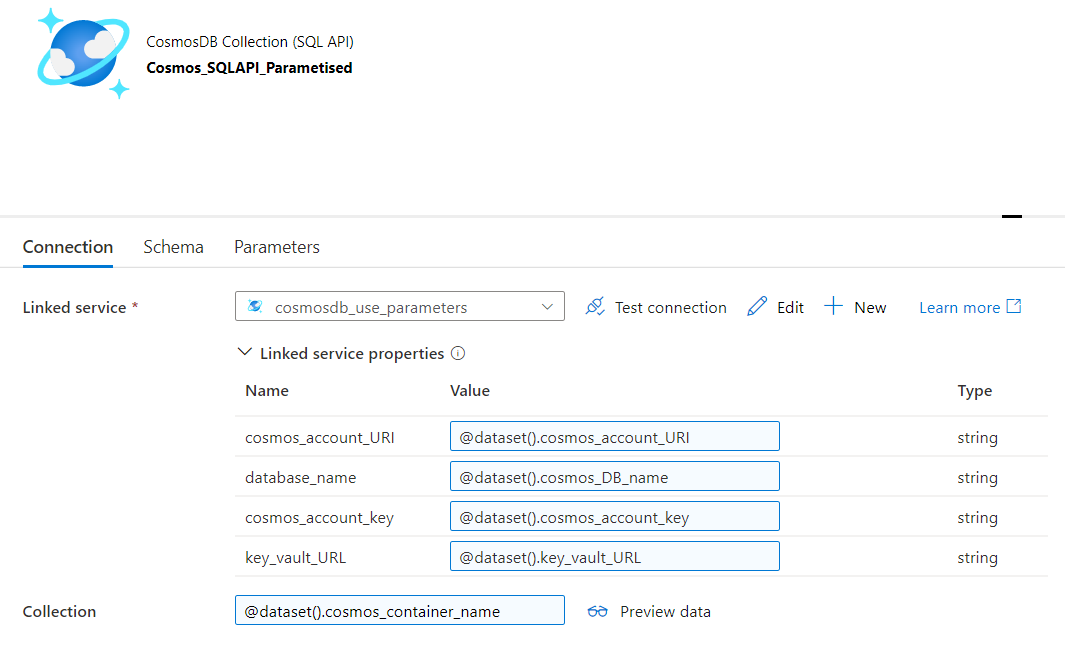
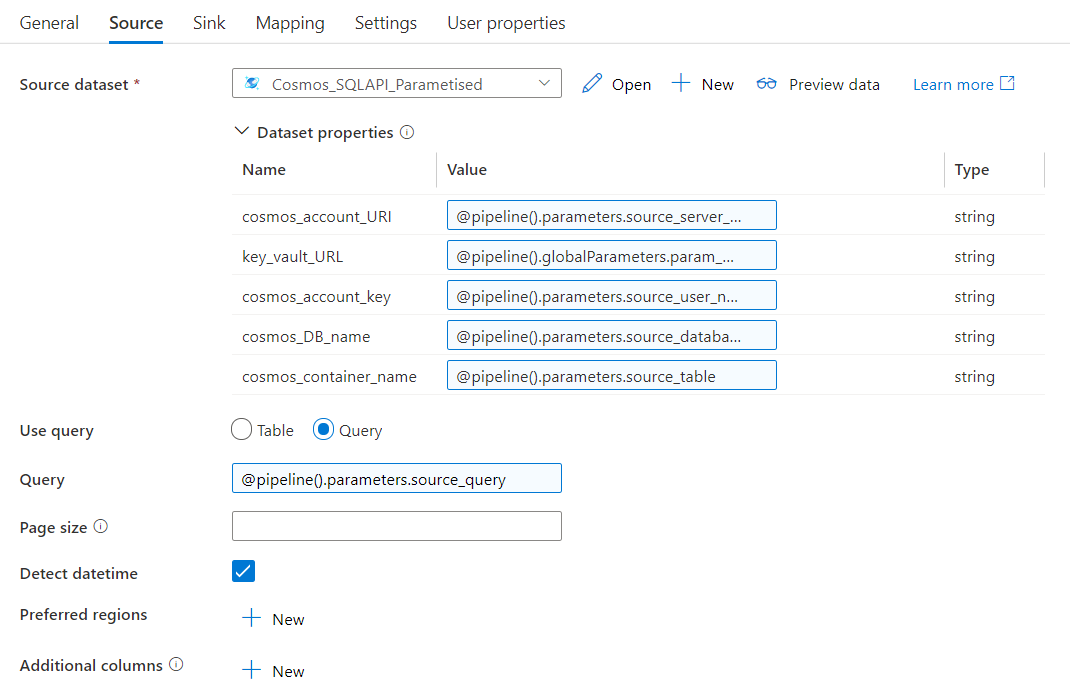
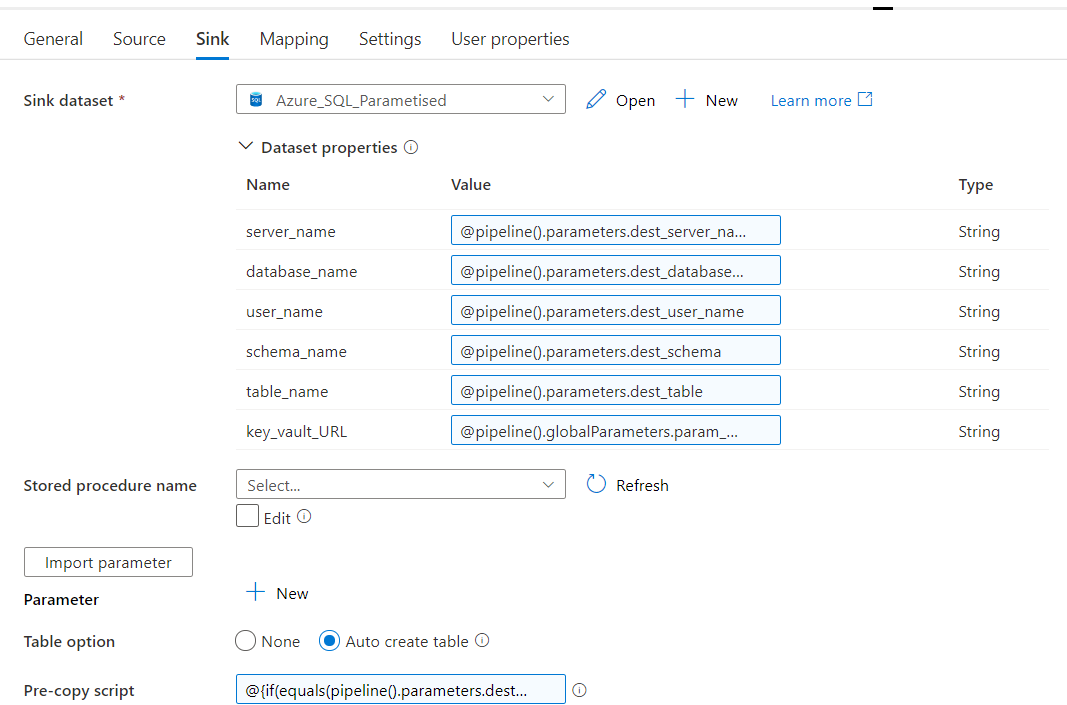
Verify this is a bug by:

The bug is that the the Copy Data activity or the Cosmos Dataset (most likely) is remembering schema and refusing to map even if no mappings are set. Anyone think of a work around?

Hi @Anonymous ,
Thank you for posting query in Microsoft Q&A Platform.
Thank you for question with all detailed images and also for sharing your workaround as well. I would escalate this internally to Product team to have a look on it. Before that could you please confirm, what you mean when you say rerun pipeline? You mean running pipeline again freshly (fresh run)? Or re-running previous execution instance?
Oh, I mean rerunning the pipeline fresh, with the same settings. Running it fresh should drop the table, then recreate, so it's a fully re-runnable process that works every time, ignoring schema changes in source or destination.
Oh also - I am running an identical process for SQL to SQL processes, which works fine even if there are schema changes in source or destination. I cloned the above pipeline from the SQL to SQL to create the Cosmos to SQL pipeline, just changing the source on the Copy data activity. So it seems it is a problem with the Cosmos source side.
OK, I actually figured out a workaround. Drop the destination table before running the Copy Data activity (which it should do anyway, but obviously doesn't). So I create a Lookup activity, set the dynamic values to the destination server, then run a query with some dynamic settings, the Dynamic Query value looks like:
@{concat('DROP TABLE IF EXISTS [',pipeline().parameters.dest_schema,'].[',pipeline().parameters.dest_table,']; SELECT 1 as Col')}
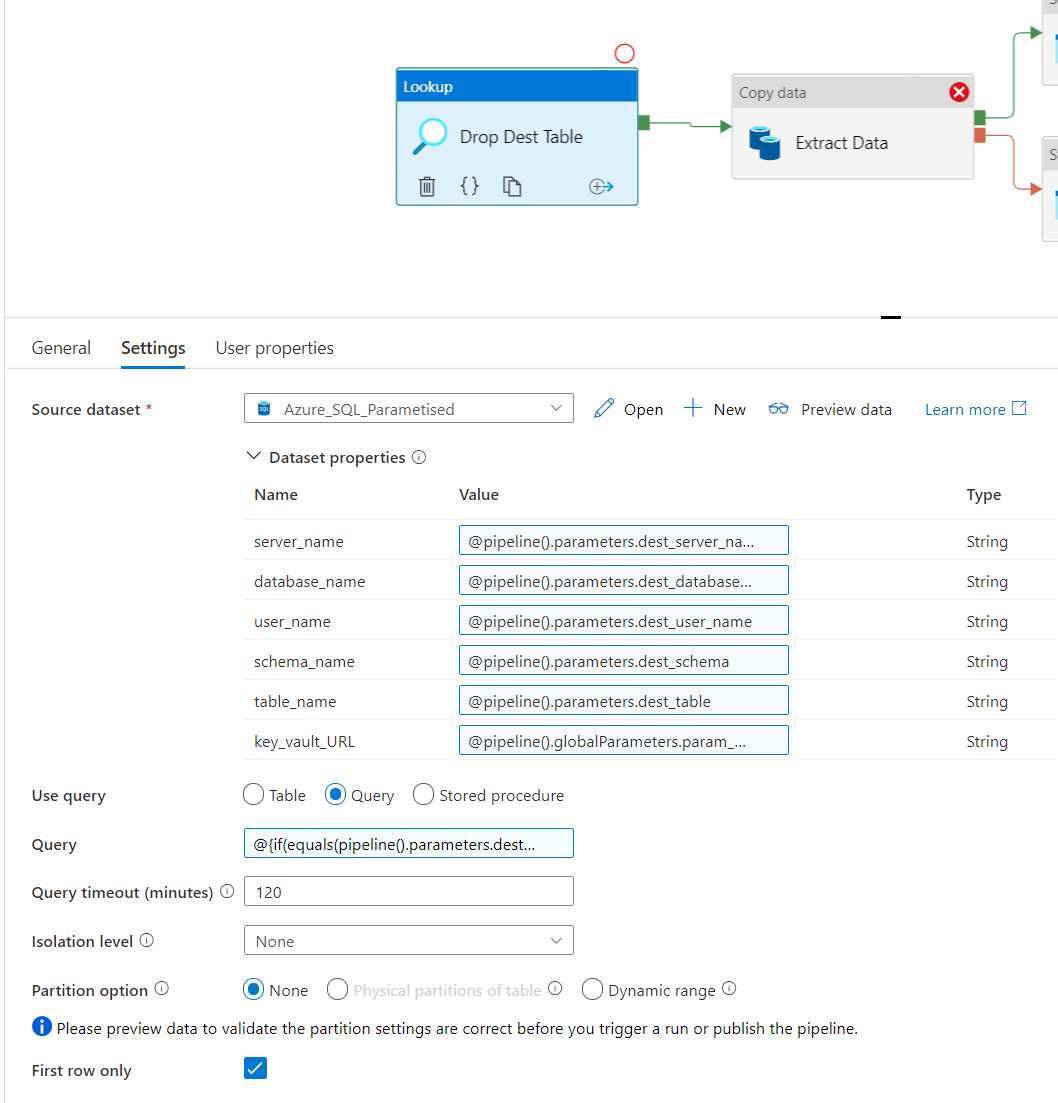
Would much rather this extra step doesn't need to be done, anyone on the Data Factory team confirm this is a bug and will be fixed?