Azure App Service
Azure App Service is a service used to create and deploy scalable, mission-critical web apps.
8,979 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

Everything seems to be just fine in the portal. The app status is Running, no obvious reason to 503s to be seen. I tried restart the app, with no luck resolving the issue.
I also tried to use webssh to check there is any problem, I get 503, too I guess my app are not running in the background at all https://dn42usw.scm.azurewebsites.net/webssh/host --> 503 The service is unavailable.
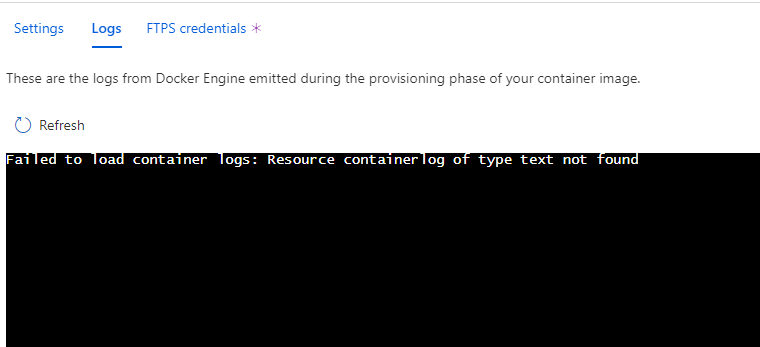
Deployment center:
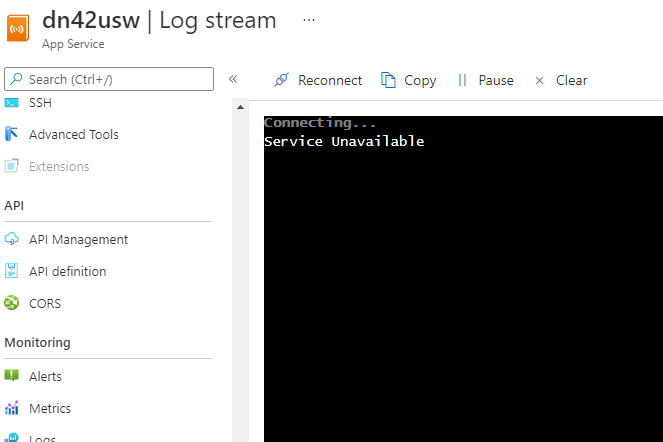
 Log stream
Log stream
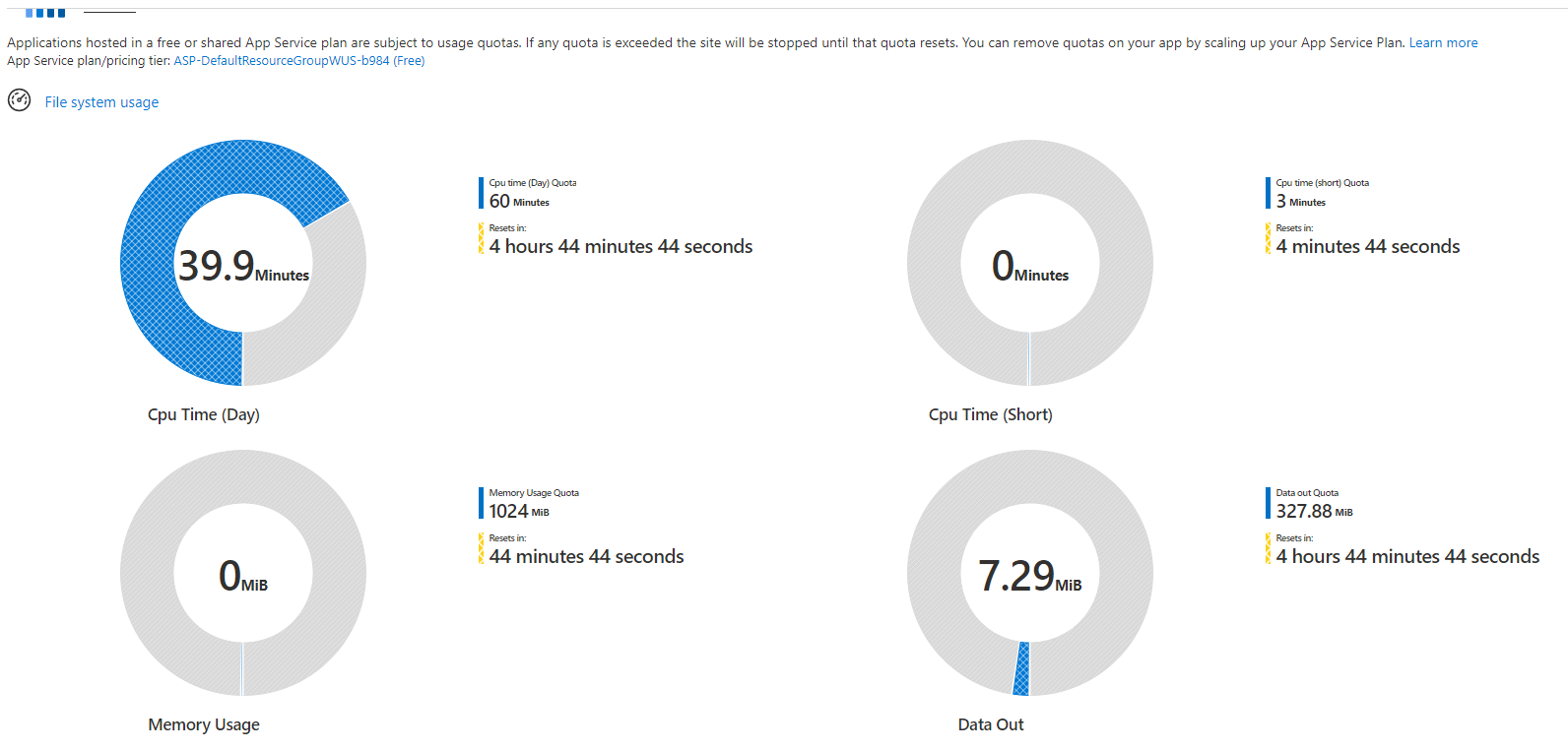
Quotas are not exceeded
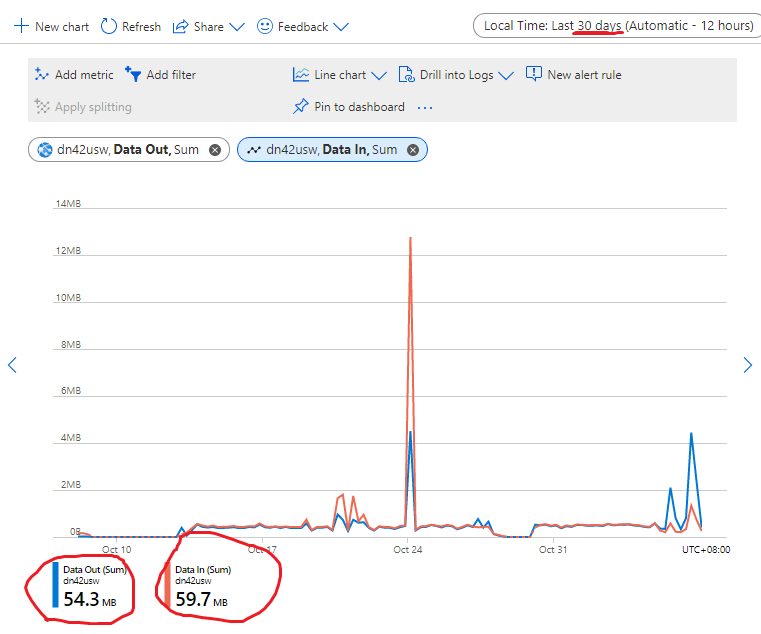
All traffic during last month, 60MB.
Shell not exceed the 5GB/month limit.
The web app works now. But... may I know the reason why it stop working during the past 8 hours?
The service goes down again.
This is 2 identical containers in different location
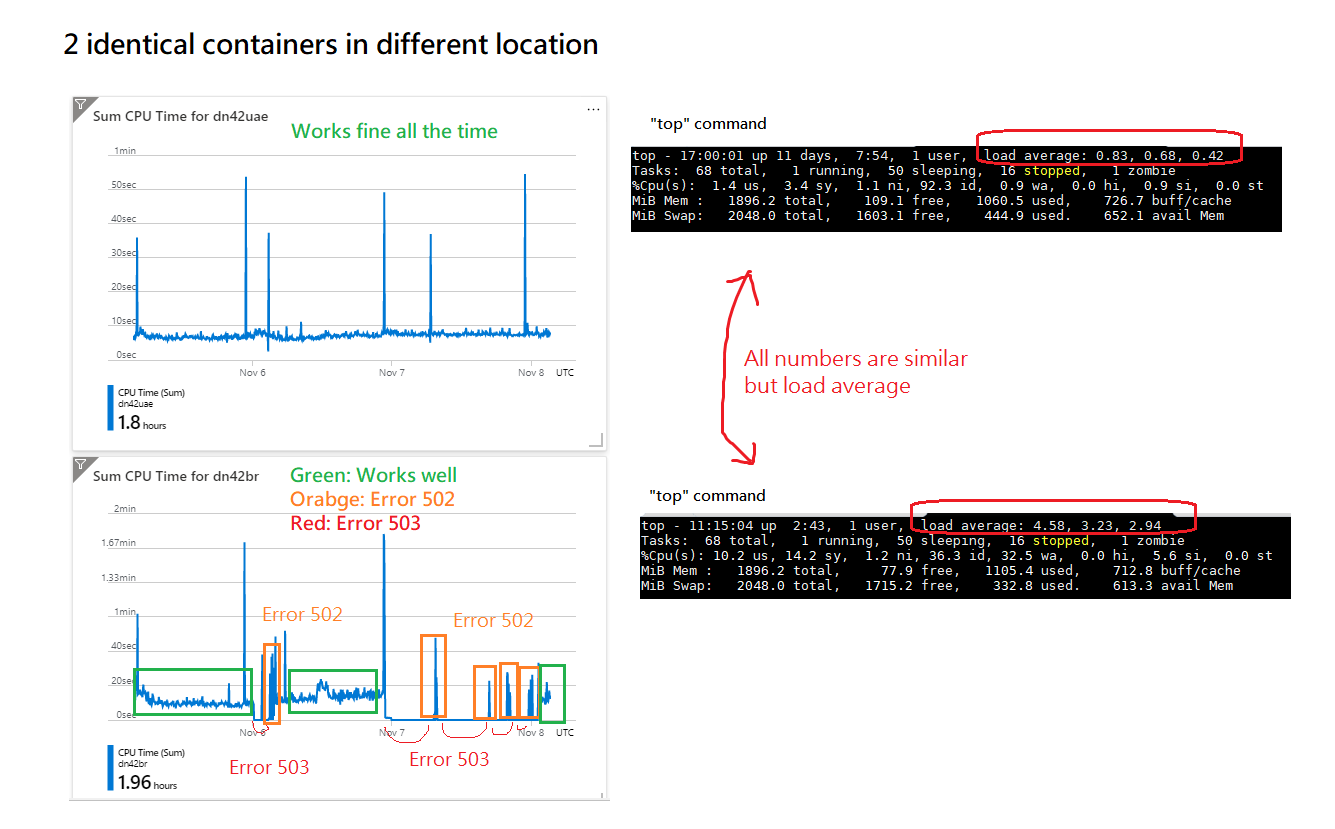
The load average in Brazil node is very high, and it's very unstable. I got error 503 and 502 very often from it.
I'm guessing the reason for this problem is the loading of the host machine is different.
The loading of the physical machine in Brazil is very high, that's why I'm getting very high load average and it's crash so often.
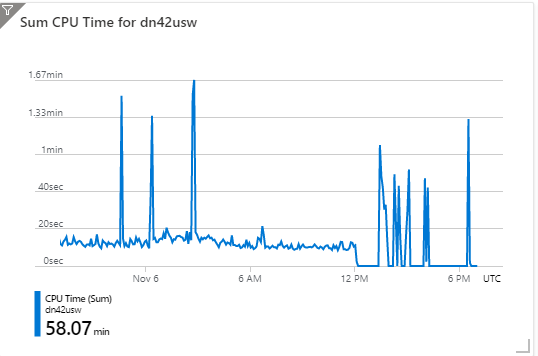
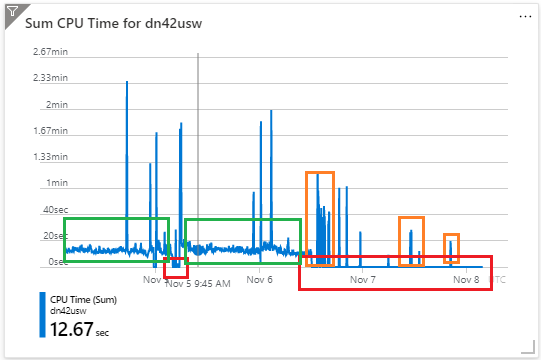
btw: this is the log of us west:
Suddenly all unstable nodes(usw/uk/br) running again

I'm still don't know the true reason for this problem.
Now I'm fully understand the LinuxFree SKU are not stable enough to running a production application. During our email conversation, you gives me two reasons to my problem
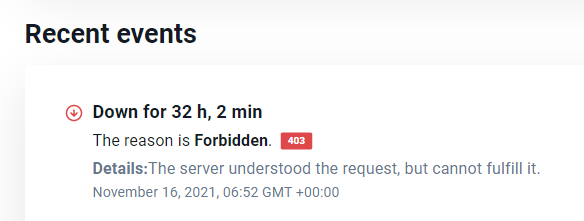
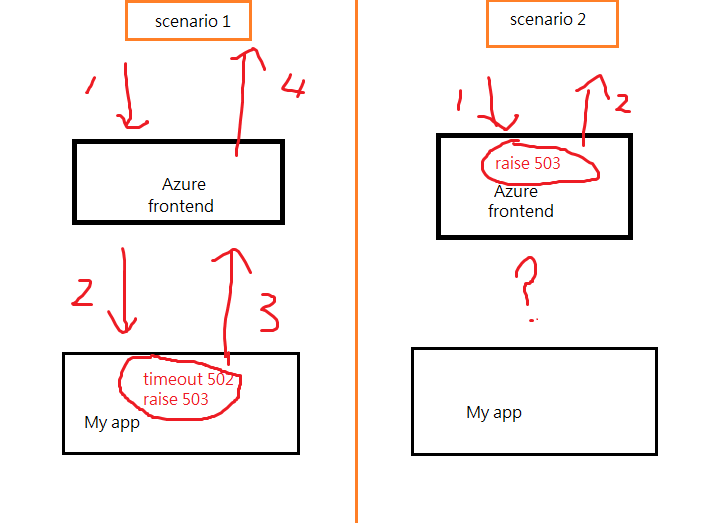
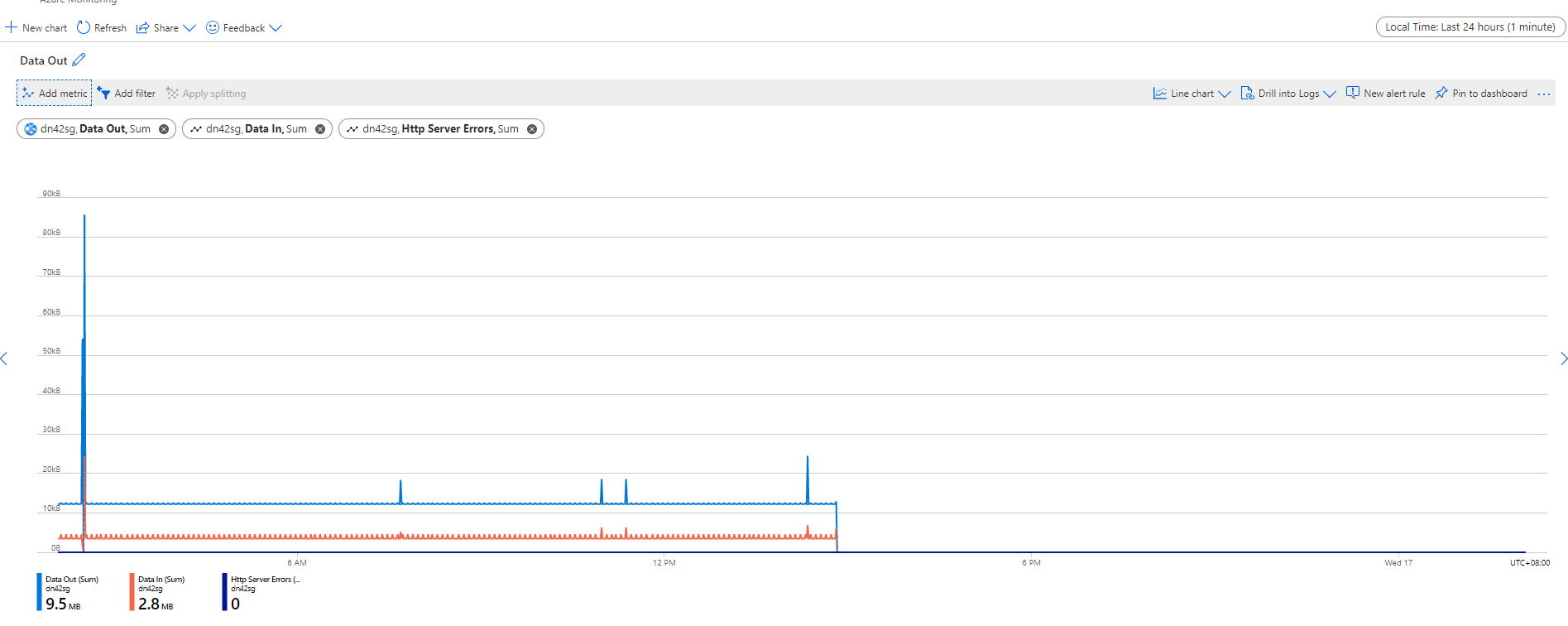
 The data in, data out, cpu time drops to 0, maybe it's my app crashed.
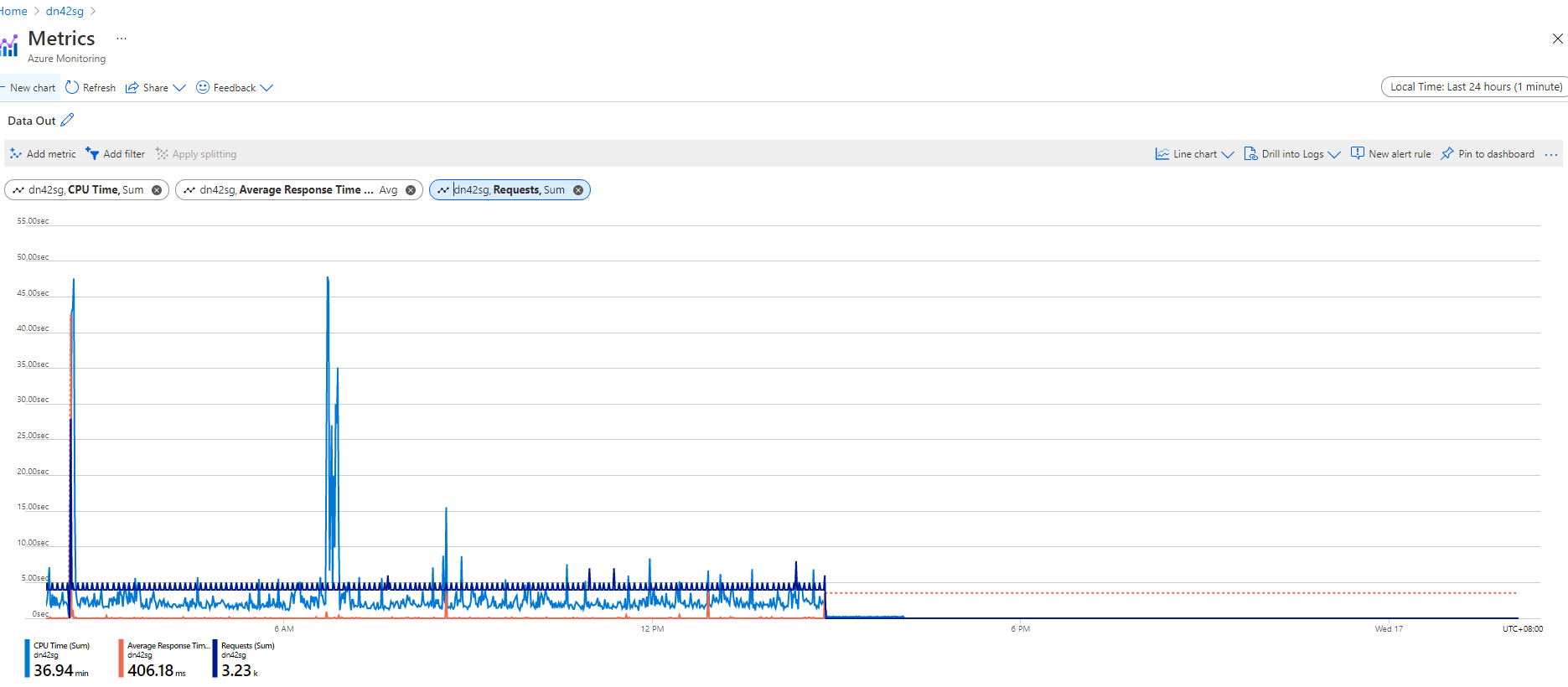
But the requests drop to 0, which means my app didn't receive any requests, which indicates the scenario 2 is only possible reason.
The data in, data out, cpu time drops to 0, maybe it's my app crashed.
But the requests drop to 0, which means my app didn't receive any requests, which indicates the scenario 2 is only possible reason.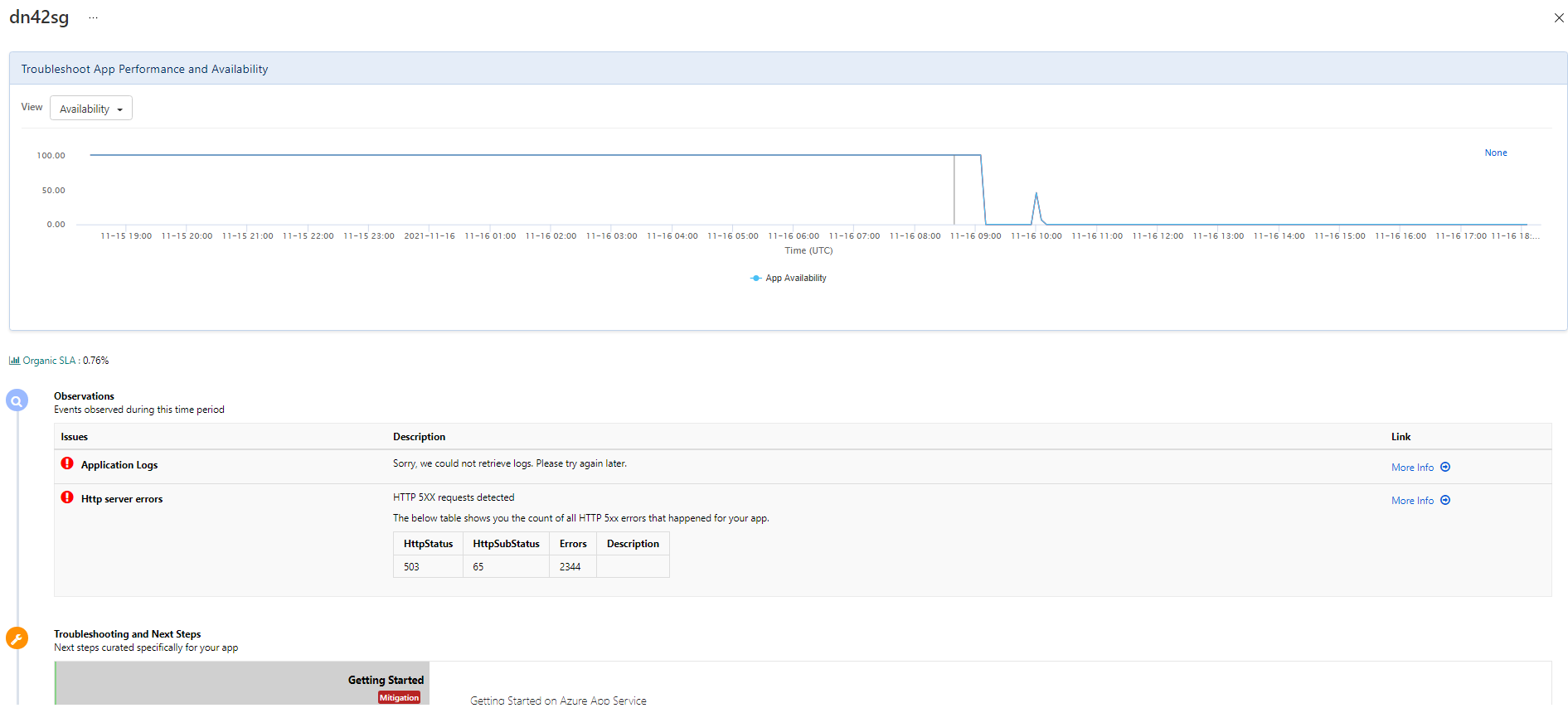
Thanks your help, now I know the HttpStatus:503 and HttpSubStatus:65 means We ran out of workers.
There are too many people uses that node so that there are no space leave for free SKU. But paid SKUs have higher priority so that they will not affact by this issue.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESM%3C/text%3E%3C/svg%3E)
Thanks for asking question! When you browse to the app and it returns a HTTP “502 Bad Gateway” error or a HTTP “503 Service Unavailable” error.
The most common causes for this behavior are:
• Requests taking a long time to execute.
• Application using high memory/CPU.
• Application crashing due to an exception.
For troubleshooting these errors, you can follow the next steps which will be divided in 3 distinct tasks, in sequential order:
Check this link: https://learn.microsoft.com/en-us/azure/app-service/troubleshoot-http-502-http-503#troubleshooting-steps-to-solve-502-bad-gateway-and-503-service-unavailable-errors
Also, its recommended for applications that are accessed infrequently and are sensitive to start-up delay's, please enable AlwaysOn by following the steps below.
Let us know if further query on this.
Thanks for asking question! When you browse to the app and it returns a HTTP “502 Bad Gateway” error or a HTTP “503 Service Unavailable” error.
The most common causes for this behavior are:
• Requests taking a long time to execute.
• Application using high memory/CPU.
• Application crashing due to an exception.For troubleshooting these errors, you can follow the next steps which will be divided in 3 distinct tasks, in sequential order:
1.Observe and monitor application behavior
2.Collect data
3.Mitigate the issue
As I mentioned in my article, the app are not running at all.
I can't even see pull and running logs in the Deployment center log and log stream.
The request doesn't reach to the container.
And the CPU logs also indicates it is not running at all.
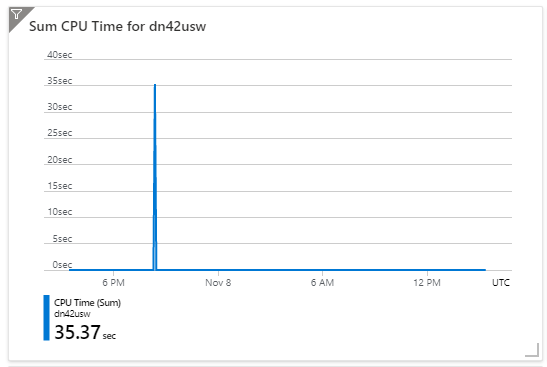
Update: All web app is up and running fine.
Web Apps Current SKU is LinuxFree and Instance Allocations Event was detected.
Consider running a production application on a Standard, Premium, or Isolated App Service Plan for better performance and isolation. These SKUs are best for production workloads.
Azure App Service Plan Pricing Information
It is recommended to follow all practices as described in below article and ensure you are scaled to multiple workers to avoid potential latency for these occurrences.
https://azure.github.io/AppService/2020/05/15/Robust-Apps-for-the-cloud.html
More details: Things You Should Know: Web Apps and Linux
Hope this helps.
Finally I get the true reason, now I know the reason is the backbone ran out of workers.
Thank you for all your assistance, I really appreciate your help in resolving the problem.
Wish there is a hint or a notification for this error instead of just a "503 The service is unavailable".
which makes me confuse
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EGR%3C/text%3E%3C/svg%3E)
Hi, a bit late, but do you remember how you fixed it? Thanks