Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERD%3C/text%3E%3C/svg%3E)
Hi, I am working on a data transformation of sql table results to a json string and save them as json documents. Stuck with how to proceed from here. I can query sale but not being able to create a json string of the table data and eventually save as a json document.
%scala
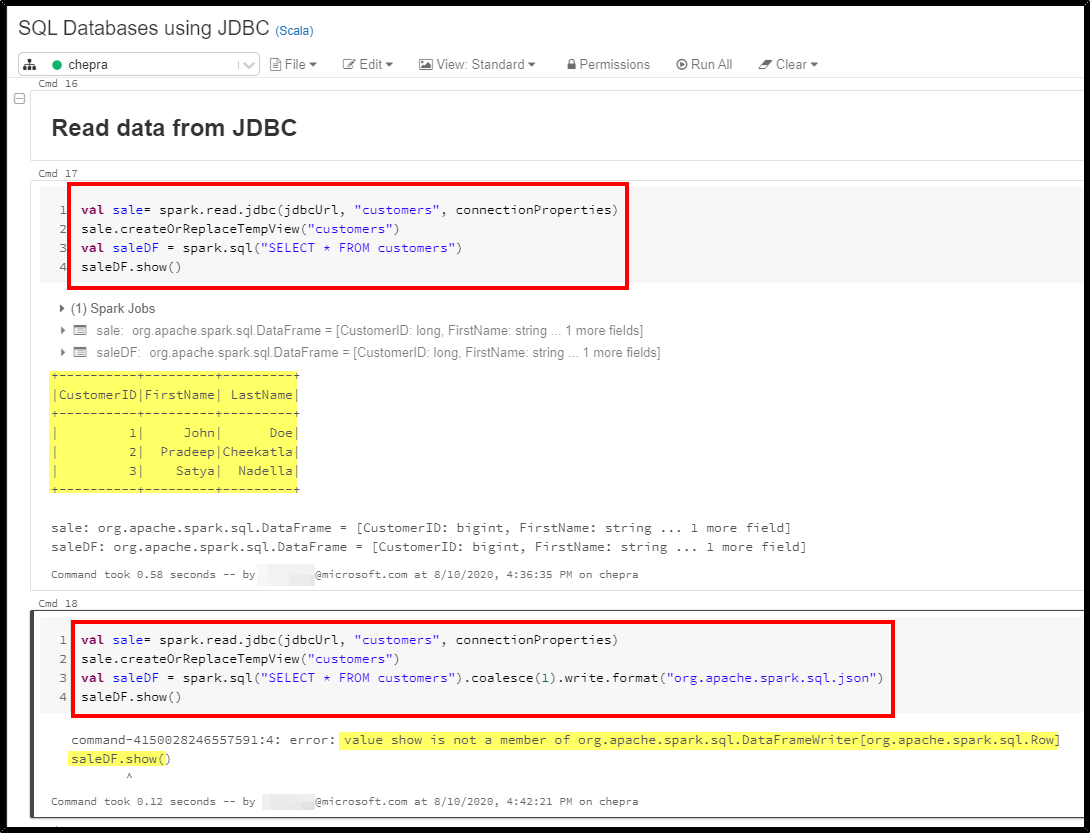
val sale= spark.read.jdbc(jdbcUrl, "sales.Transaction", connectionProperties)
sale.createOrReplaceTempView("sale")
saleDF = spark.sql("SELECT * FROM sale LIMIT 10").coalesce(1).write.format("org.apache.spark.sql.json")
saleDF.show() // dispaly json string throws error: value show is not a member of org.apache.spark.sql.DataFrameWriter[org.apache.spark.sql.Row]
spark.sql("SELECT * FROM sale LIMIT 10").coalesce(1).write.format("org.apache.spark.sql.json").mode("overwrite").save(<Blob Path1/ ADLS Path1/sale.json>) // to save json document to ADLS error: unclosed block
Thank you

Hello @Raj D ,
You will experience this error message when your Storage account Firewalls and virtual networks are set to "selected networks".
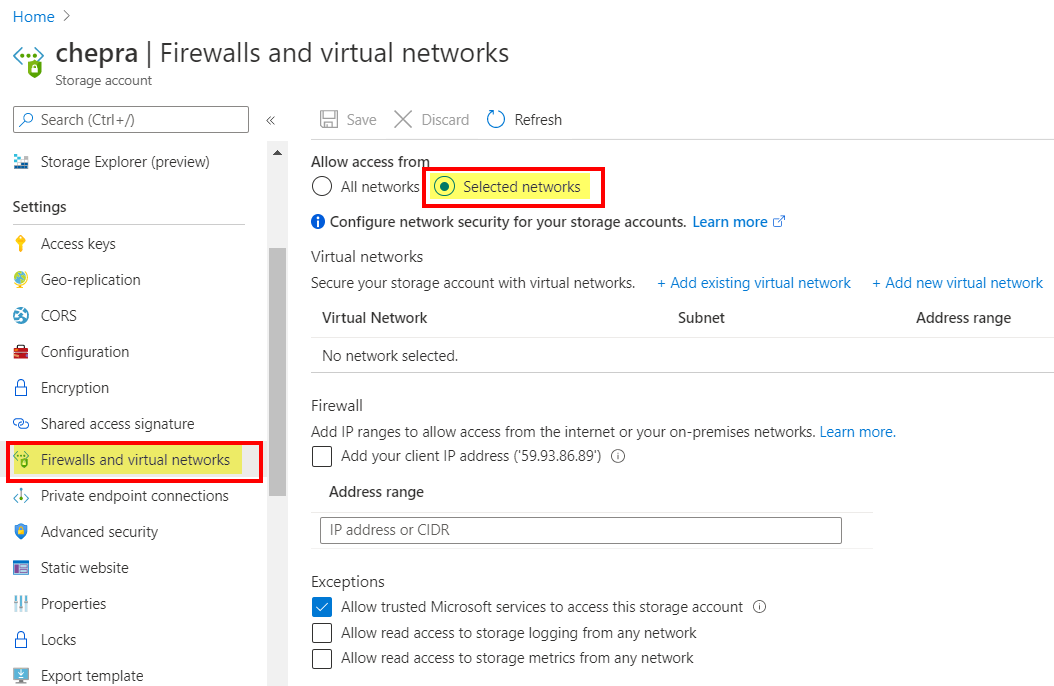
Error: Which you are experiencing
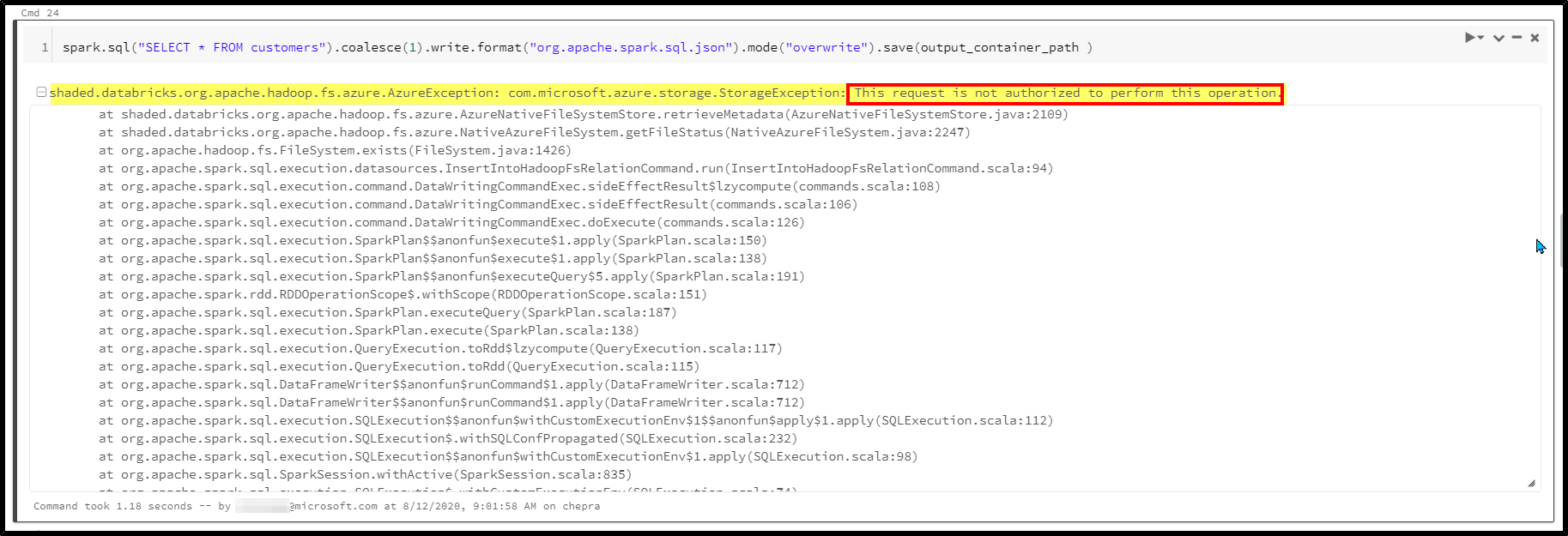
To resolve this issue: There are couple of solutions
Try to change the storage account => Firewalls and virtual networks to "All networks".
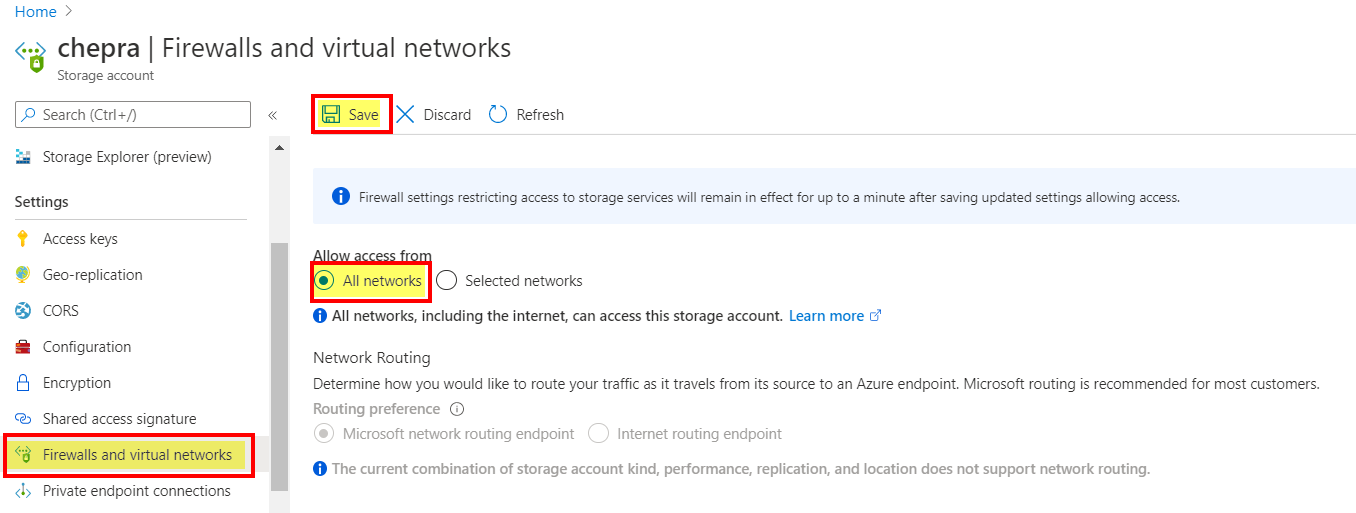
Successful: After changes the firewall rules it started working.
OR
Since, Azure Databricks does not count as a trusted Microsoft service, you could see the supported trusted Microsoft services with the storage account firewall.
You need to Deploy Azure Databricks in your Azure virtual network (VNet injection).
Hope this helps. Do let us know if you any further queries.
----------------------------------------------------------------------------------------
Do click on "Accept Answer" and Upvote on the post that helps you, this can be beneficial to other community members.
Hi PRADEEPCHEEKATLA-MSFT, Thanks very much.
Hello @Raj D ,
Welcome to the Microsoft Q&A platform.
You are experiencing this error message “value show is not a member of org.apache.spark.sql.DataFrameWriter[org.apache.spark.sql.Row] saleDF.show()”, because it expecting the path of the json file to read the data from.
You don't create a JSON string before you save; Spark takes care of writing it out to JSON at the point of saving. Until such time as you actually write it to storage, the DataFrame is a logical construction without a public physical representation.
The write property returns a DataFrameWriter, not a DataFrame. (and a writer doesn't have the show method, only an actual DF does)
Also also, the terminal methods of a DataFrameWriter chain (e.g. json) don't return anything. Their purpose is to have the side effect of performing the actual write operation to storage, not to return a new DataFrame.
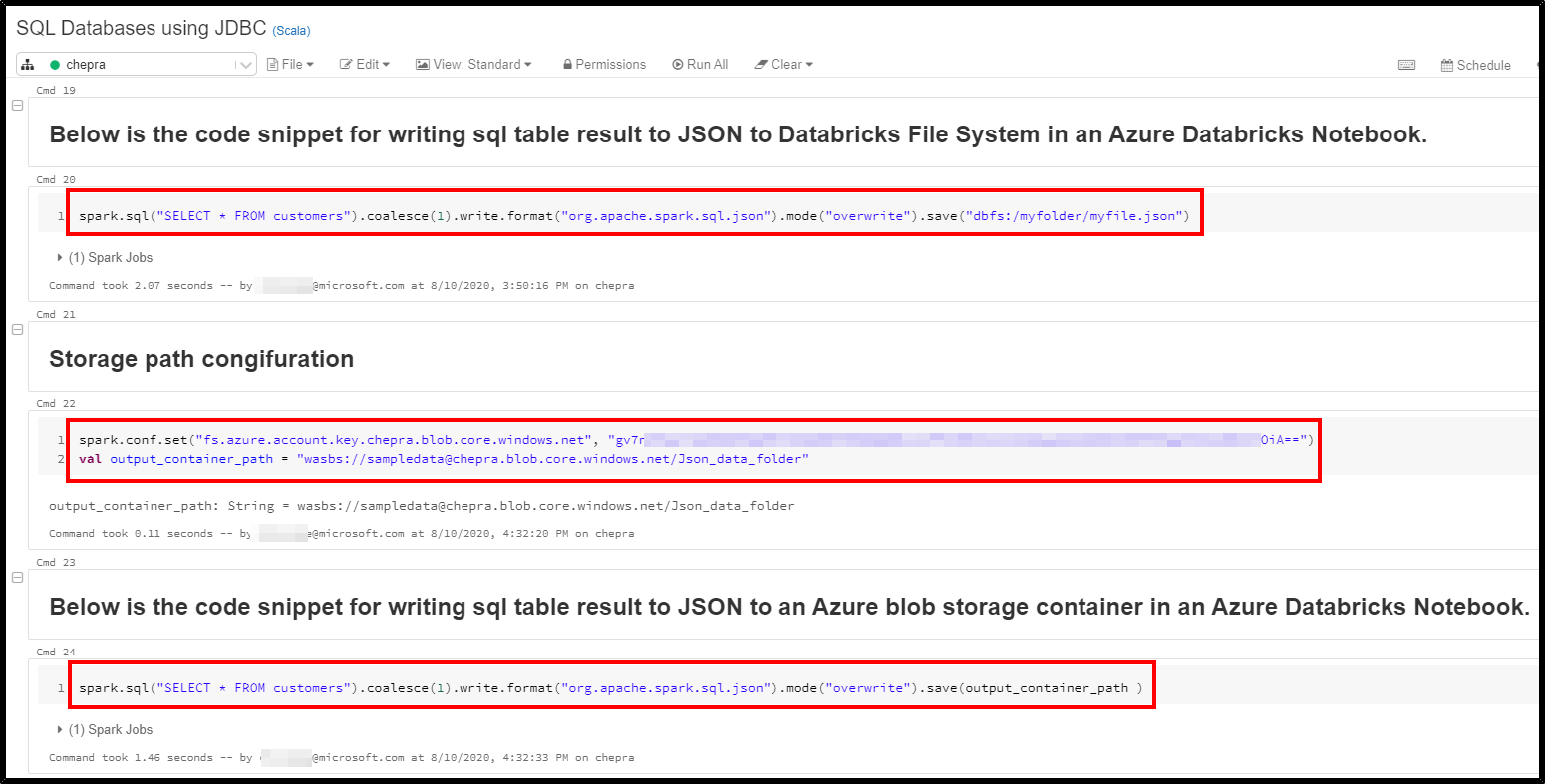
Below is the code snippet for writing sql table result to JSON to Databricks File System in an Azure Databricks Notebook.
spark.sql("SELECT * FROM customers").coalesce(1).write.format("org.apache.spark.sql.json").mode("overwrite").save("dbfs:/myfolder/myfile.json")
For Blob Storage: You need to configure the Storage path.
spark.conf.set("fs.azure.account.key.chepra.blob.core.windows.net", "gv7nVxxxxxxxxxxxxxxxxxxxxxOiA==")
val output_container_path = "wasbs://******@chepra.blob.core.windows.net/Json_data_folder"
Below is the code snippet for writing sql table result to JSON to an Azure blob storage container in an Azure Databricks Notebook.
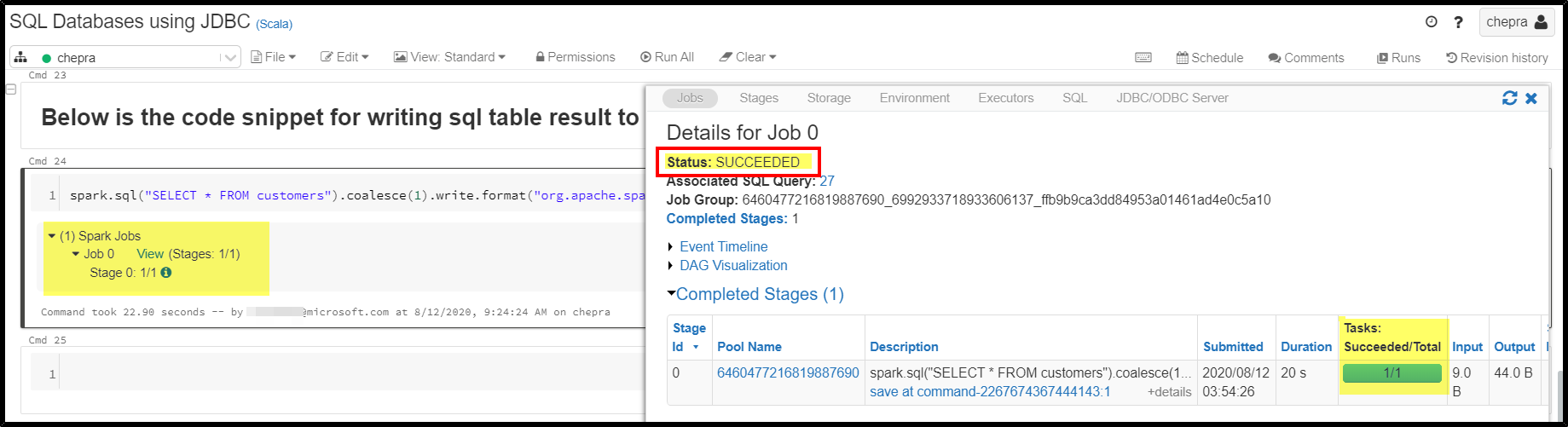
spark.sql("SELECT * FROM customers").coalesce(1).write.format("org.apache.spark.sql.json").mode("overwrite").save(output_container_path )
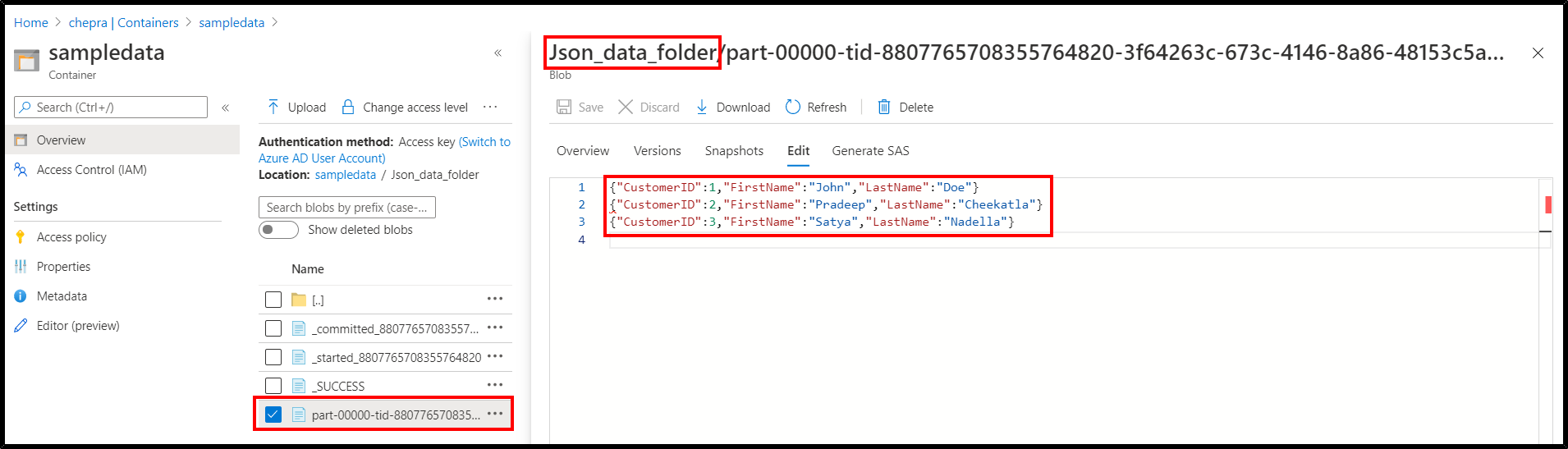
Successfully transformed table results to json in azure databricks.
Hope this helps. Do let us know if you any further queries.
----------------------------------------------------------------------------------------
Do click on "Accept Answer" and Upvote on the post that helps you, this can be beneficial to other community members.
Hi PRADEEPCHEEKATLA-MSFT, Thanks very much for your response. I configured the storage path and if I run the below code I get the following error. The configuration step worked fine.
spark.sql("SELECT * FROM sale").coalesce(1).write.format("org.apache.spark.sql.json").mode("overwrite").save(sale_container_path)
Error: shaded.databricks.org.apache.hadoop.fs.azure.AzureException: com.microsoft.azure.storage.StorageException: This request is not authorized to perform this operation.
Hello @Raj D ,
Could you please add the stack trace of the error message which you are experiencing?
Note: Make sure you have correct permissions on the Storage account.
Hi PRADEEPCHEEKATLA-MSFT, Thanks very much. Please find the stack trace below. The container public access level is set to Container.
shaded.databricks.org.apache.hadoop.fs.azure.AzureException: com.microsoft.azure.storage.StorageException: This request is not authorized to perform this operation.
at shaded.databricks.org.apache.hadoop.fs.azure.AzureNativeFileSystemStore.retrieveMetadata(AzureNativeFileSystemStore.java:2109)
at shaded.databricks.org.apache.hadoop.fs.azure.NativeAzureFileSystem.getFileStatus(NativeAzureFileSystem.java:2164)
at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1426)
at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelationCommand.scala:94)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:108)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:106)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.doExecute(commands.scala:126)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:150)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:138)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$5.apply(SparkPlan.scala:191)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:187)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:138)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:117)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:115)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:711)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:711)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withCustomExecutionEnv$1$$anonfun$apply$1.apply(SQLExecution.scala:112)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:232)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withCustomExecutionEnv$1.apply(SQLExecution.scala:98)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:835)
Hello @Raj D ,
Thanks for sharing the error message. You are experiencing this error message due to firewall configuration on the Storage account. To resolve this issue, I would request you to checkout the answer posted below.
If the post helps, please do remember to "Accept Answer" and "Upvote".