Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
10,196 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMD%3C/text%3E%3C/svg%3E)
I am facing an error while trying to parse the Json file from Blob Storage using a data set within ADF.
The json file is the list of objects and I have selected the appropriate option in the data flow, and I have even tried with all the three available options, yet don't know the reason behind the issue.
I have tried changing the encoding but it resulted in a change in data.
The json file is created by merging more than one json file with one record in it, using a copy activity as below
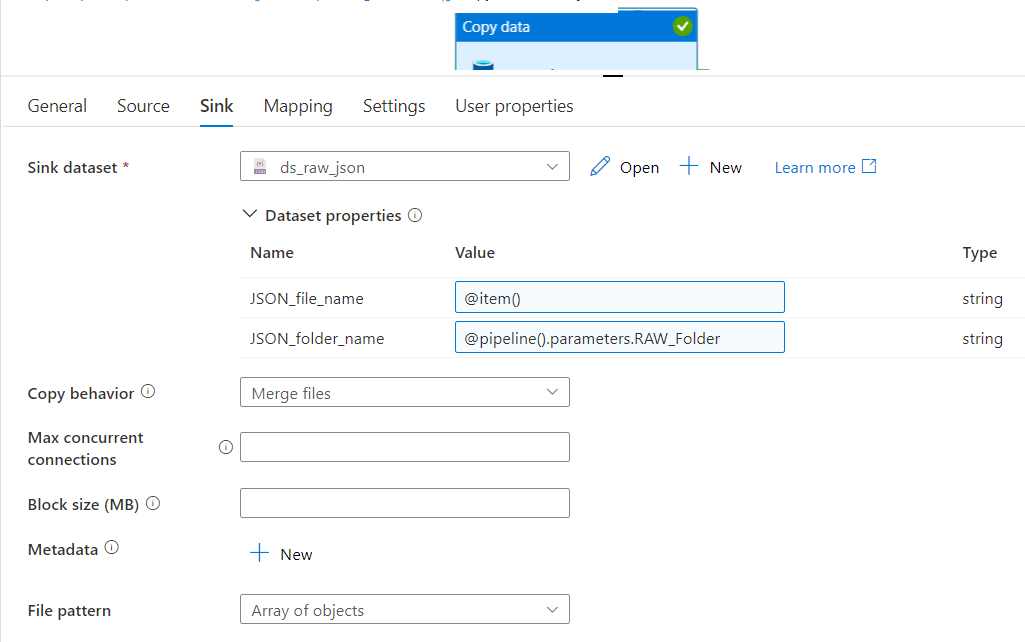
I have verified the output merged json file and it looks appropriate and used the online json viewer to verify the structure of the file, everything looks good.
But when this file is used in dataflow to read the data as shown in the below snip, I am facing an issue with the error message as:
{"StatusCode":"DF-JSON-WrongDocumentForm","Message":"Job failed due to reason: Malformed records are detected in schema inference. Parse Mode: FAILFAST","Details":"org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0, 10.90.0.5, executor 0): org.apache.spark.SparkException: Malformed records are detected in schema inference. Parse Mode: FAILFAST.\n\tat org.apache.spark.sql.catalyst.json.JsonInferSchema$$anonfun$1$$anonfun$apply$1.apply(JsonInferSchema.scala:66)\n\tat org.apache.spark.sql.catalyst.json.JsonInferSchema$$anonfun$1$$anonfun$apply$1.apply(JsonInferSchema.scala:53)\n\tat scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)\n\tat scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)\n\tat scala.collection.Iterator$class.isEmpty(Iterator.scala:331)\n\tat scala.collection.AbstractIterator.isEmpty(Iterator.scala:1334)\n\tat scala.collection.TraversableOnce$class.reduceLeftOption(TraversableOnce.scala:203)\n\tat scala.collection.AbstractIterator.reduceLeftOption(Iterator.scala:1334)\n\tat scala.collection.TraversableOnce$class.reduceOption(TraversableOnce.scal"}
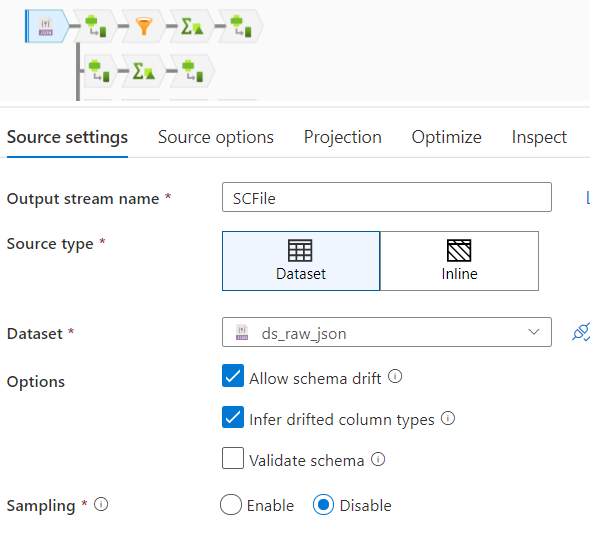
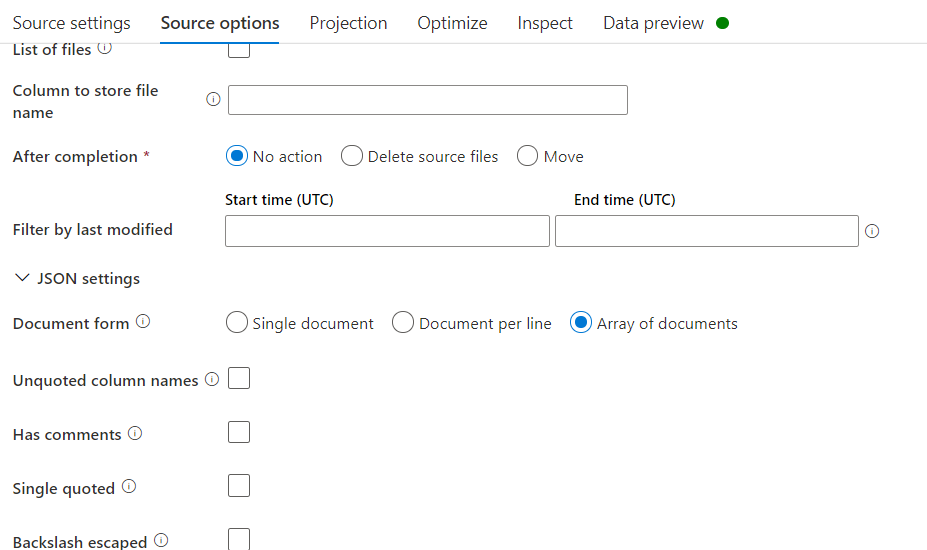
The issue behind this is, by default the copy activity stores the json file as UTF-8 with BOM in the blob, and while reading the file using ADF Data Flow even though it is by default UTF-8, still it is unable to detect the BOM character and raising the issue.
So while creating the file in blob storage, at the sink dataset (in my case) specify the encoding as "UTF-8 without BOM" and it worked.
Note: For some reason, we cant use the dataset which has UTF-8 without BOM encoding in DataFlow, in that case, you can create two datasets one with default UTF-8 encoding (which will be used in DataFlow) and one with UTF-8 without BOM(which will be used in copy activity sink/while creating a file).
Thank you.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EI%3C/text%3E%3C/svg%3E)
Just wasted 2 hours trying different things before stumbling upon your solution! Thank you so much!
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ENJ%3C/text%3E%3C/svg%3E)
The problem is in the Json file being read by the Dataflow.
Try to upload the raw unmodified json file to blobstore manually and try the "Data preview" option in the "Source component" in Dataflow.
I got the same error when I did minor modification in the json file in a text editor and uploaded it back to the blob storage.
Hi Nishil Jain, thanks for your quick response, I have figured out the actual issue behind it and will be replying to this question.