Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
2,222 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
I would like to know what happens to my azure databricks notebooks in case of a region outage:
E.g. If my primary zone is CentralUS and this happens to be down: Can I still log in into centralusdatabricks.net and see my notebooks ?
If not, I would like to know a way to keep a back up so I can visualize them.
*I was thinking about linking my azure dev ops account and create a repos for every user registered at my databricks cluster but I don't know if there's any cost $$
Thanks for ur help.

Hello anonymous user,
Welcome to the Microsoft Q&A platform.
If you haven’t configured the disaster recovery for Azure Databricks clusters, you will not able to access the data and visualize, when there is an outage in the region.
If you have configured the disaster recovery for Azure Databricks clusters, you can access the data and visualize using secondary region.
The persisted data is available in your storage account, which can be Azure Blob Storage or Azure Data Lake Storage. Once the cluster is created, you can run jobs via notebooks, REST APIs, ODBC/JDBC endpoints by attaching them to a specific cluster.
The Databricks control plane manages and monitors the Databricks workspace environment. Any management operation such as create cluster will be initiated from the control plane. All metadata, such as scheduled jobs, is stored in an Azure Database with geo-replication for fault tolerance.
One of the advantages of this architecture is that users can connect Azure Databricks to any storage resource in their account. A key benefit is that both compute (Azure Databricks) and storage can be scaled independently of each other.
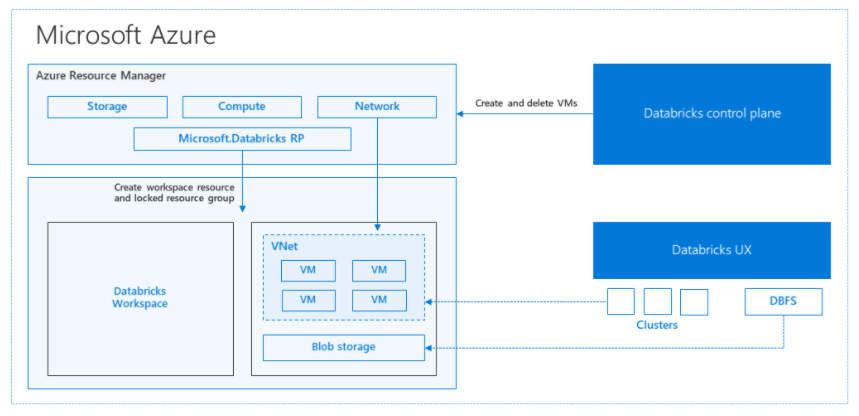
This article describes a disaster recovery architecture useful for Azure Databricks clusters, and the steps to accomplish that design.
Hope this helps. Do let us know if you any further queries.
----------------------------------------------------------------------------------------
Do click on "Accept Answer" and Upvote on the post that helps you, this can be beneficial to other community members.
Hello anonymous user,
Just checking in to see if the above answer helped. If this answers your query, do click “Accept Answer” and Up-Vote for the same. And, if you have any further query do let us know.
Hello anonymous user,
Following up to see if the above suggestion was helpful. And, if you have any further query do let us know.