I've been looking at the deadlocks occurring, and I will have to admit that I cannot exactly pinpoint why they are happening. Then again, the analysis may be different for your actual case.
At first, just like Ronen, I was not able to repro the deadlocks at all. However, once I fired up Profiler and had the RPC:Completed event, I could get deadlocks. Profiler here serves as a go-slower button.
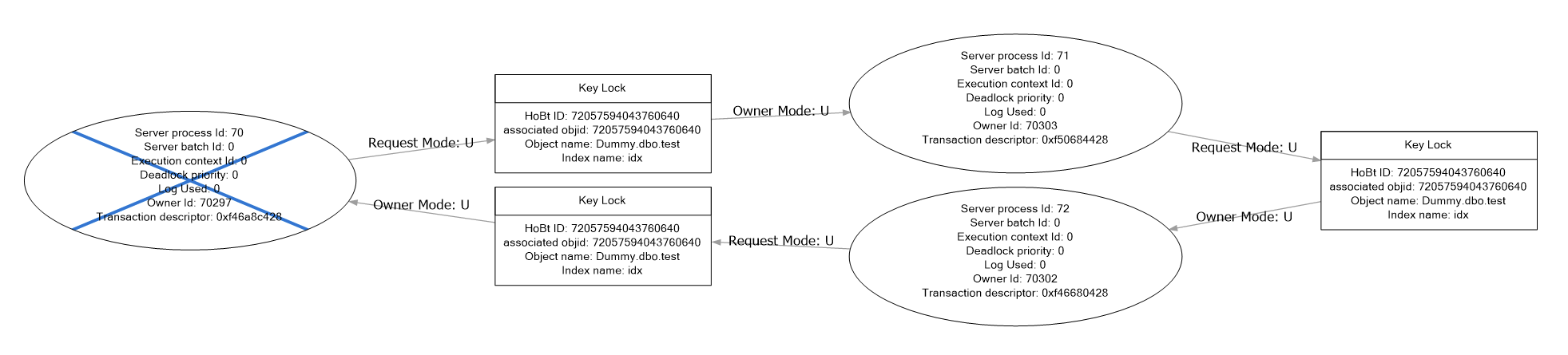
The deadlock often involve more than two processes, but here is a two process deadlock:
<resource-list>
<keylock hobtid="576460752593485824" dbid="2" objectname="tempdb.dbo.test" indexname="idx" id="lock18dc6fb0980" mode="U" associatedObjectId="576460752593485824">
<owner-list>
<owner id="process18dbf830ca8" mode="U"/>
</owner-list>
<waiter-list>
<waiter id="process18dc25664e8" mode="U" requestType="wait"/>
</waiter-list>
</keylock>
<keylock hobtid="576460752593485824" dbid="2" objectname="tempdb.dbo.test" indexname="idx" id="lock18dc6fac480" mode="U" associatedObjectId="576460752593485824">
<owner-list>
<owner id="process18dc25664e8" mode="U"/>
</owner-list>
<waiter-list>
<waiter id="process18dbf830ca8" mode="U" requestType="wait"/>
</waiter-list>
</keylock>
So my theory about page locks was wrong. It is all about U locks on key level. All processes are scanning the table, so each process will take a U lock on a row, release it, take the next lock etc. However, once it gets a match on Id, it will retain the U lock on that row. But it will continue scanning and attempt to acquire/release locks on the remaining rows as well.
If all processes would scan the rows in the same order, starting on the same point, there cannot be any deadlocks. The first process that finds an Id, will block all other processes that point.
And naïvely, I though that this how it works. But if that assumption are wrong, and the access order or the starting point is different, there can be deadlocks, because two processes each find a row and then they meet each other, not being able to move on.
Why would order or starting point be different? Starting points could be different due to merry-go-around scans, that is, a process piggybacks on an existing scan. But maybe there are other possible reasons.
I only tried this under READ COMMITTED LOCK. But I can't see that this would be any different under SNAPSHOT isolation. If you don't see this under SNAPSHOT, that could due to a timing issue. So if the deadlocks you are actually having problem with are like this one, snapshot is not the solution.
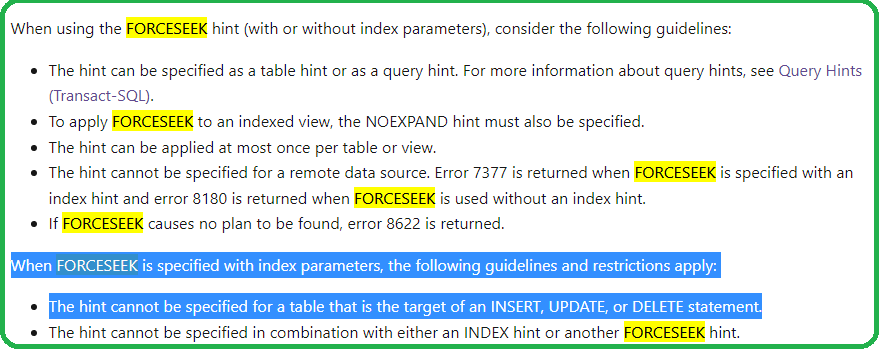
On the other hand, the FORCESEEK hint seems like a valid solution to me. You say:
This can be used for updates only, deletes and (bulk)inserts does not accept this hint.
No problem with DELETE:
DELETE test FROM test WITH(FORCESEEK) WHERE id = 99
But you need to use the FROM clause.
On an INSERT it is of course more difficult to apply this hint, but I don't see why it would be needed.
To reiterate, I would not be surprised that the deadlocks you see in your actual environment are different, so I would encourage you to share the deadlock XML for this. That is, the graph you posted above is useless; it hides a lot of information.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EFN%3C/text%3E%3C/svg%3E)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAM%3C/text%3E%3C/svg%3E)