Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,624 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJ%3C/text%3E%3C/svg%3E)
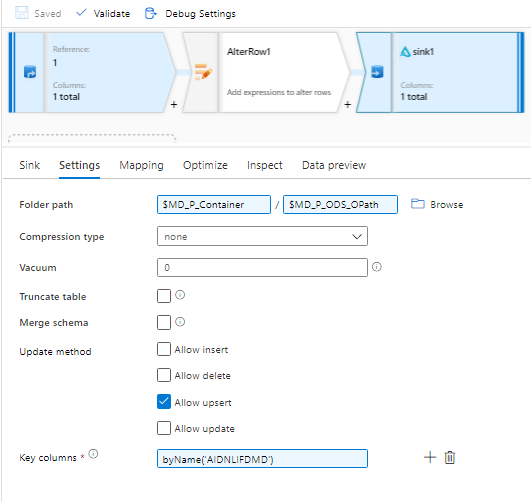
I'm getting the error for the ADF data flow - Delta Sink on key column, but I did the schema import and the column exists:
"Key column 'undefined' does not exist in mapped columns."
Some clue about the problem, looks like a bug, I know the Delta Sink is on preview


Would you mind replying here with the data flow script behind this data flow? Copy and paste the script from the Script button in the data flow designer.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHM%3C/text%3E%3C/svg%3E)
Hi @jmarciogsousa ,
Are you still facing the issue? If your query is addressed, request you to mark the answer that helped you as “Mark as Answer” and "Up-Vote" so that other forum members can benefit from it. If you need any further help do let us know.
Hi @MarkKromer-8019 thank you for your feedback, I attached as requested18305-script.txt the script.
I changed the column to "HashId" and it's also on the mapped tab.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJM%3C/text%3E%3C/svg%3E)
Hi @jmarciogsousa @Wesley Tremayne ,
Thanks for reporting this issue! It’s a bug on our UX tool, it complains the key column as “undefined” because the schema of sink is not published so that the UX tool can’t recognize it properly. We will create a work item for it and fix this issue soon.
Meanwhile as a workaround, you can try:
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EWT%3C/text%3E%3C/svg%3E)
@Jack Ma @Kiran-MSFT That worked! Thanks for the quick responses!
I get it working with the procedure
Hi @jmarciogsousa ,
Glad that you found a resolution.
Please do consider to click on "Accept Answer" and "Up-vote" on your post, as it can be beneficial to other community members
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EC%3C/text%3E%3C/svg%3E)
I'm seeing the same issue, but following the steps from @jmarciogsousa does not resolve the issue for me. I have tried the following:
I'm attaching the code in text format as well.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKM%3C/text%3E%3C/svg%3E)
Click on the script button which has the real details of the dataflow. It is the first button shaped like a scroll next to the code button.
Here is the script
@Chris try to refresh the page after publish
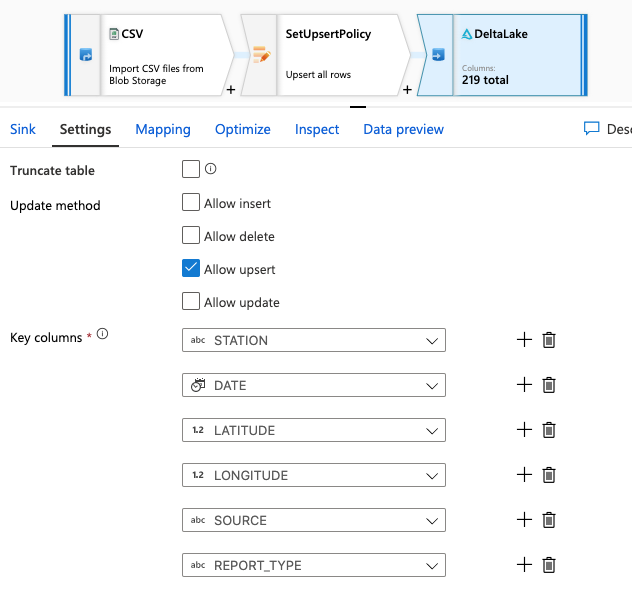
Check to make sure you have mapped "prrowid" column in the mapping tab. It is most likely left unmapped.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBM%3C/text%3E%3C/svg%3E)
Hello Everyone,
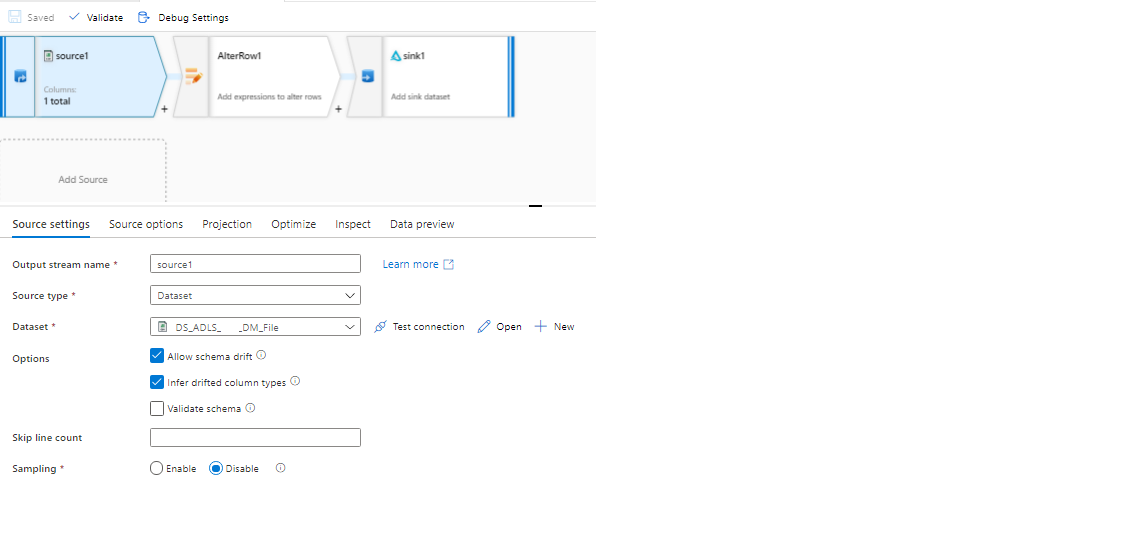
I am facing the same issue. My requirement is to build metadata driven mapping data flow (All Parameterized way).
I have to read multiple CSV files (All are different files having differing schema) from raw_zone and do SCD 1 or 2 based on the parameterized key columns. I have enabled Azure-DevOps in my ADF. Working on feature branch and I could not publish from feature branch.
Key Points to Note:
 28170-dataflow-script.txt
28170-dataflow-script.txt Could you please help me for the solution ? @jmarciogsousa
@Balan Murugan , you can try refresh the page if not stop-start debug mode
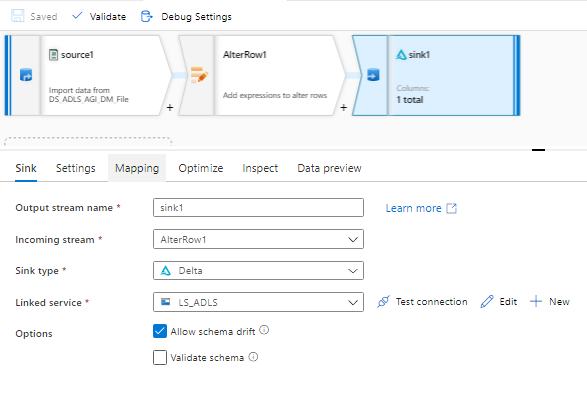
@jmarciogsousa Tried it multiple times. But still, no luck. When adding another sink as Azure SQL DB it does not throw this error. It is erroring out ONLY when the sink is in DELTA forma.
In the attached screen shot, sink1 is for delta format. sink2 is for Azure SQL DB.
I believe, since delta format is in public preview, this particular feature is not yet available I guess for the parameterization.