Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
2,222 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ER%3C/text%3E%3C/svg%3E)
i have a adls gen2 folder with multiple parquet files with same structure. i want to transform all files at once seperately with one script in same notebook and convert each file to csv and write to another folder in adls.
how can achieve this?
let's say 10 files in adls....i want to do this
adls gen 2 folder A ---> read and transform in one db notebook --> write output to folder B in adls
10 parquet files seperately(no merging) in csv format (10 csv files)

Hello @reddy ,
Here are the steps to convert Parquet files to csv format in a notebook:
Parquet files in an Azure Data Lake Gen2 folder name azure:
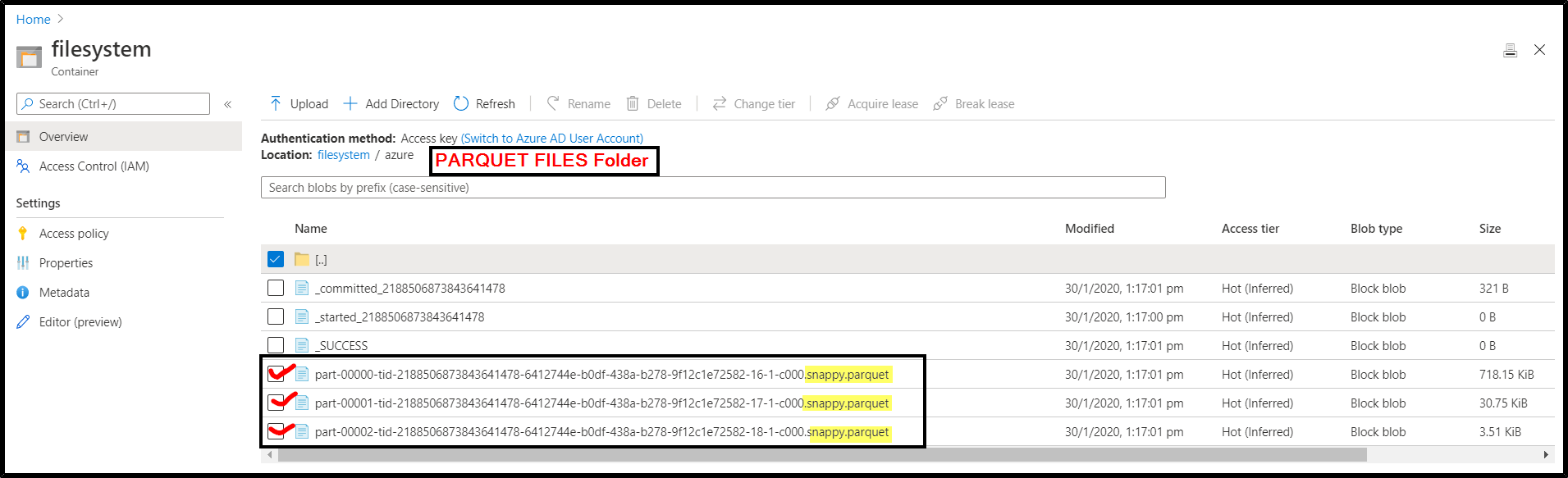
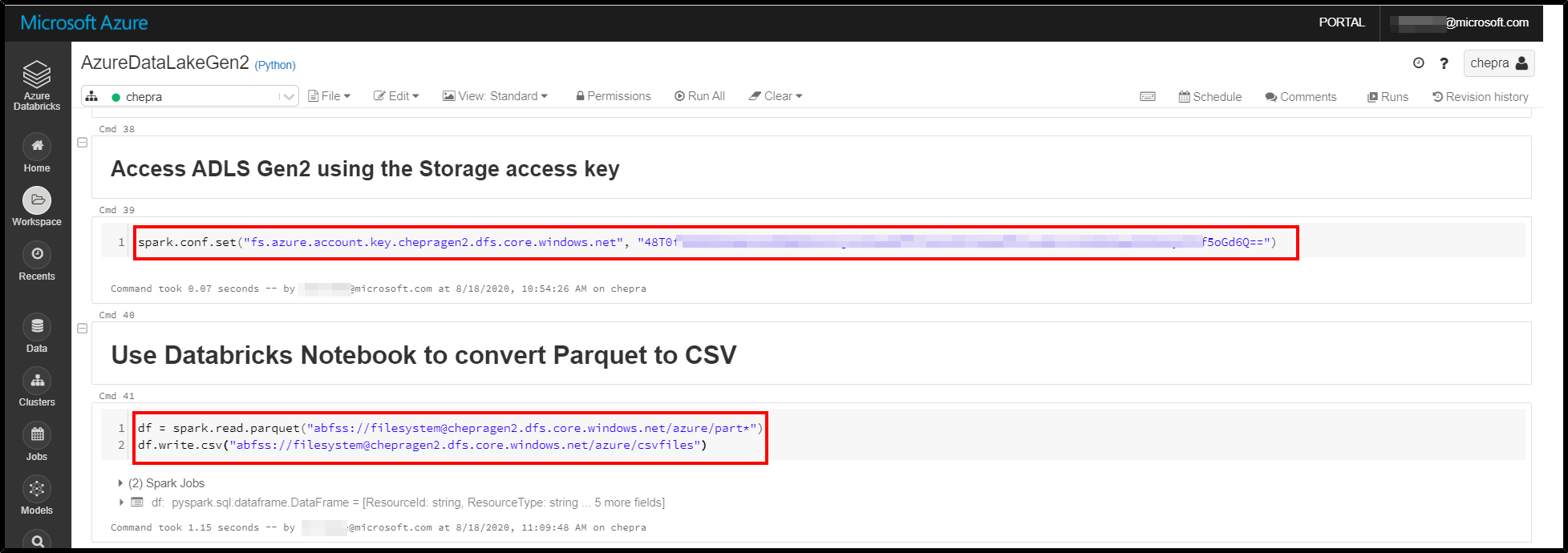
Step1: You can access the Azure Data Lake Gen2 storage account in databricks using any one of the methods from this document.
I’m access ADLS gen2 folder using the storage account access key.
spark.conf.set("fs.azure.account.key.<storage-account-name>.dfs.core.windows.net",” storage-account-access-key-name>"))
Step2: Using Spark, you can convert Parquet files to CSV format as shown below.
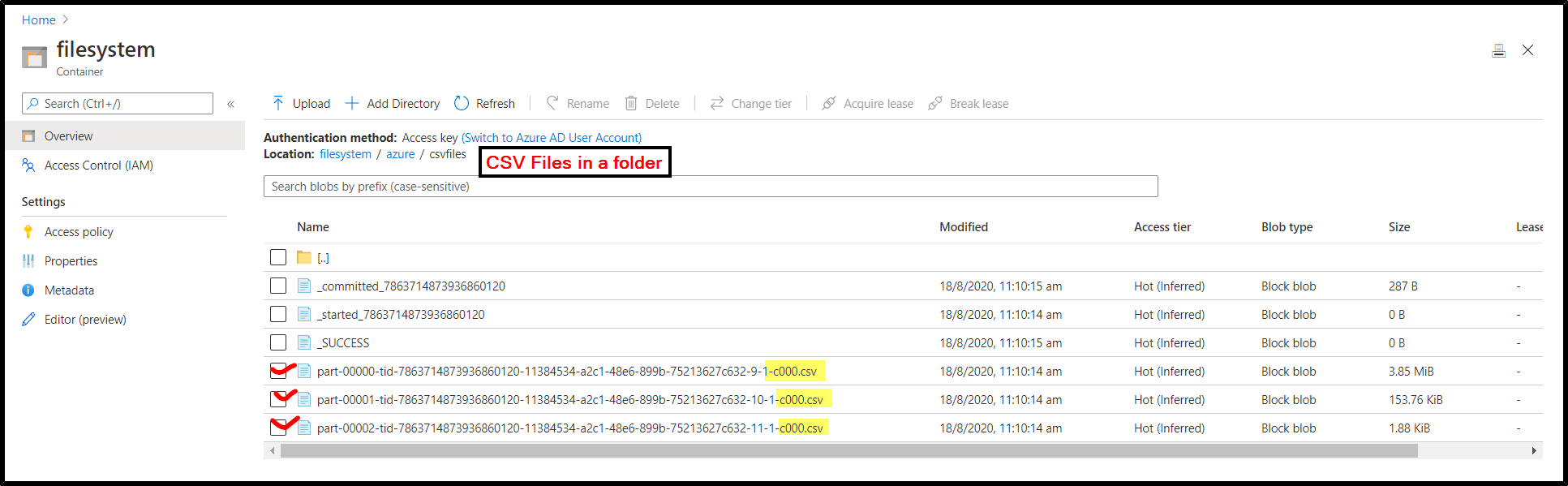
CSV files in an Azure Data Lake Gen2 folder name csv files:
Hope this helps. Do let us know if you any further queries.
----------------------------------------------------------------------------------------
Do click on "Accept Answer" and Upvote on the post that helps you, this can be beneficial to other community members.
Due to platform limitation, I'm unable to add the code to the answer.
Here is the code to convert parquet files to csv files:
df = spark.read.parquet("/path/to/infile.parquet")
df.write.csv("/path/to/outfile.csv")
Hello @reddy ,
Just checking in to see if the above answer helped. If this answers your query, do click “Accept Answer” and Up-Vote for the same. And, if you have any further query do let us know.