Azure Data Lake Storage
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
1,559 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERD%3C/text%3E%3C/svg%3E)
Hi, I am using below code in python to read data from a SQL table and copy results in a dataframe then push the results into a json document and save it in Azure Data Lake Storage Gen2.
https://learn.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-overview
jdbcHostname = "hostname"
jdbcDatabase = "databasename"
jdbcPort = 1413
jdbcUsername = "username"
jdbcPassword = "password"
jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2}".format(jdbcHostname, jdbcPort, jdbcDatabase)
connectionProperties = {
"user" : jdbcUsername,
"password" : jdbcPassword,
"driver" : "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
pushdown_query = "(select * from hr.employee) emp"
df = spark.read.jdbc(url=jdbcUrl, table=pushdown_query, properties=connectionProperties)
display(df)
df.write.mode("overwrite").json("wasbs://<file_system>@<storage-account-name>.blob.core.windows.net/hr/emp")
The above code displays data in dataframe but does not create the folder and the json document. Could you please where I am doing it wrong.
Thank you
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EWM%3C/text%3E%3C/svg%3E)
Hi PRADEEPCHEEKATLA-MSFT, this is almost the same solution I encountered in Data Science from Scratch
org.apache.spark.SparkException: Job aborted.
---------------------------------------------------------------------------
Py4JJavaError Traceback (most recent call last)
<command-2802701877950826> in <module>
9 df=spark.createDataFrame([Row(**i) for i in data])
10 df.show()
---> 11 df.write.mode("overwrite").json("wasbs://<file_system>@<storage-account-name>.blob.core.windows.net/hr/emp")
/databricks/spark/python/pyspark/sql/readwriter.py in json(self, path, mode, compression, dateFormat, timestampFormat, lineSep, encoding)
815 compression=compression, dateFormat=dateFormat, timestampFormat=timestampFormat,
816 lineSep=lineSep, encoding=encoding)
--> 817 self._jwrite.json(path)
818
819 @since(1.4)
/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py in __call__(self, *args)
1255 answer = self.gateway_client.send_command(command)
1256 return_value = get_return_value(
-> 1257 answer, self.gateway_client, self.target_id, self.name)
1258
1259 for temp_arg in temp_args:

Hello @Raj D ,
I'm able to push data from dataframe to json with the same code which you are tried.
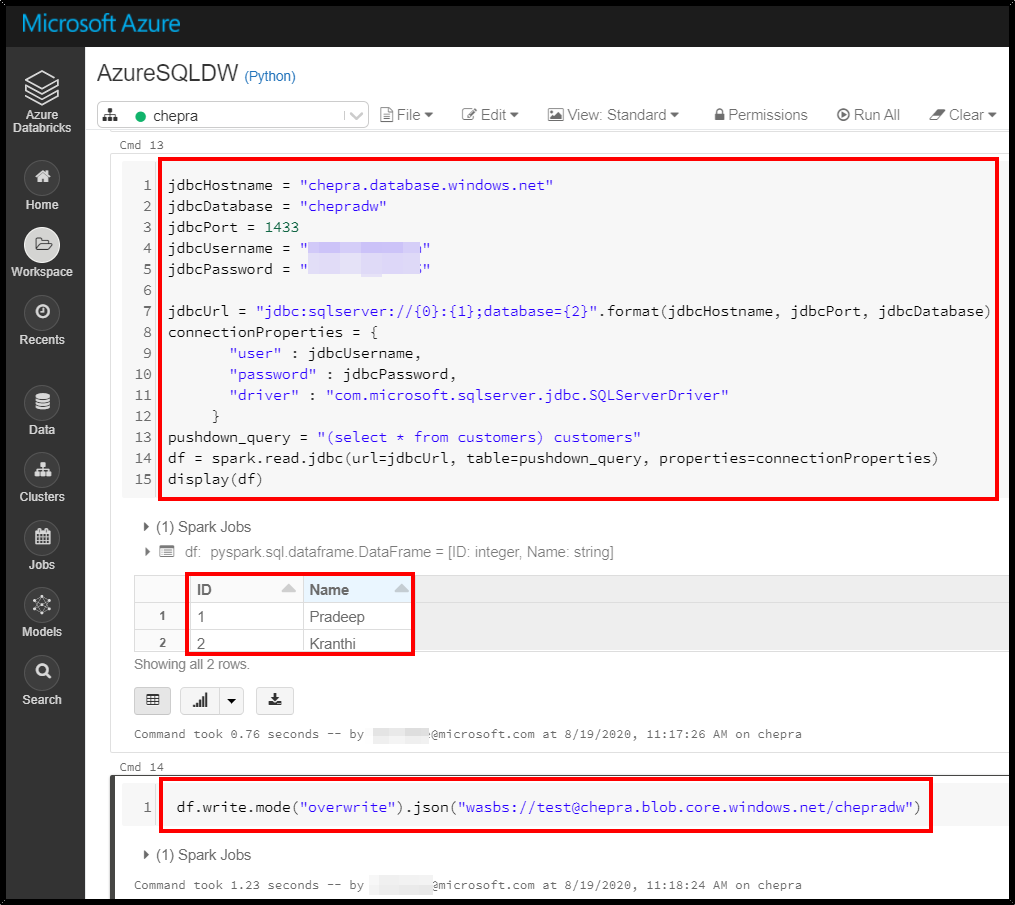
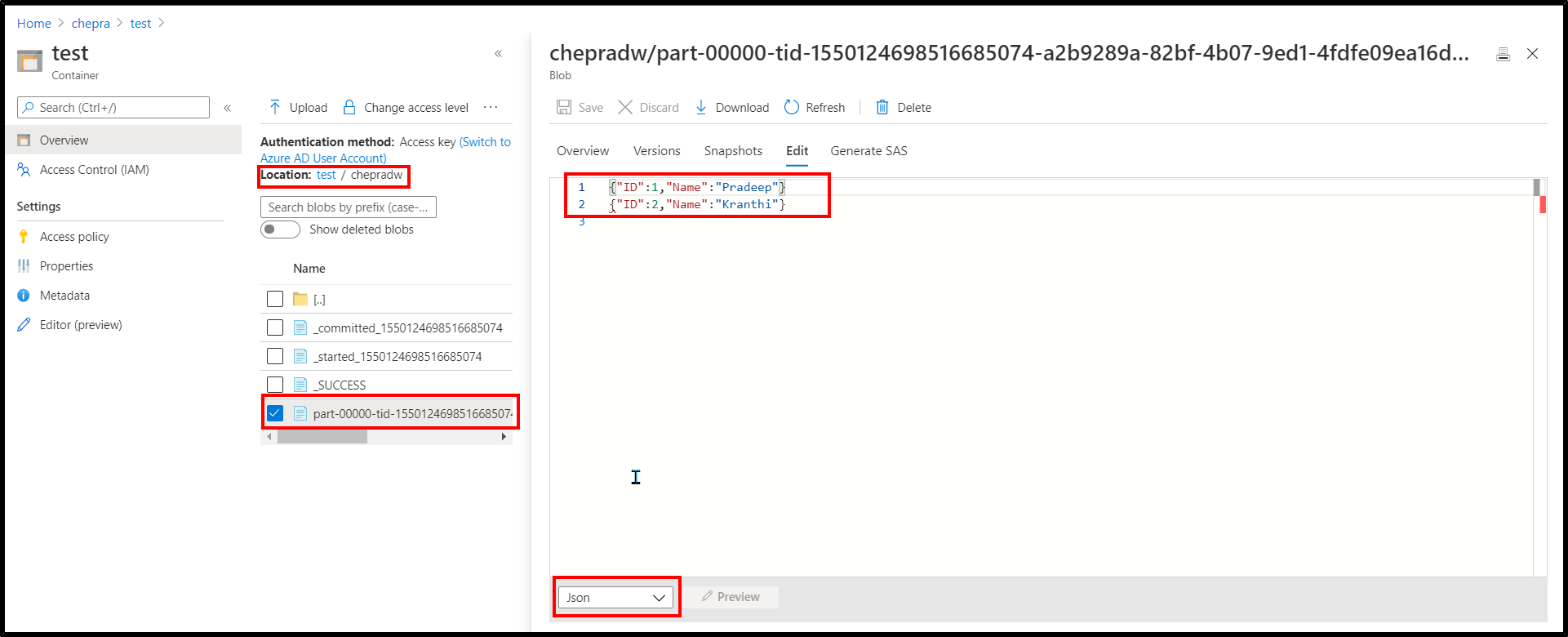
Here is the JSON document which is written to Storage account:
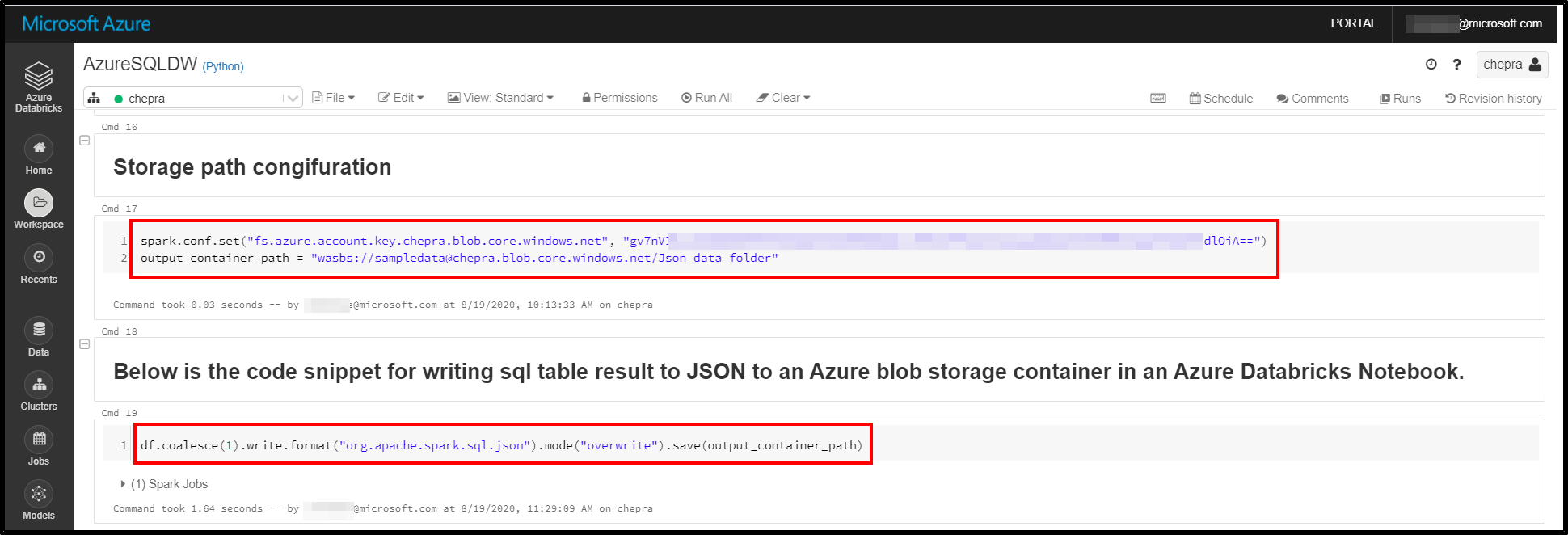
If the above method is not working for you, you can try the below method:
Step1: Configure the storage account path
spark.conf.set("fs.azure.account.key.chepra.blob.core.windows.net", "gvXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXdlOiA==")
output_container_path = "wasbs://******@chepra.blob.core.windows.net/Json_data_folder"
Step2: Use the below code snippet for writing sql table result to JSON document
df.coalesce(1).write.format("org.apache.spark.sql.json").mode("overwrite").save(output_container_path)
Here is the JSON document which is written to Storage account:
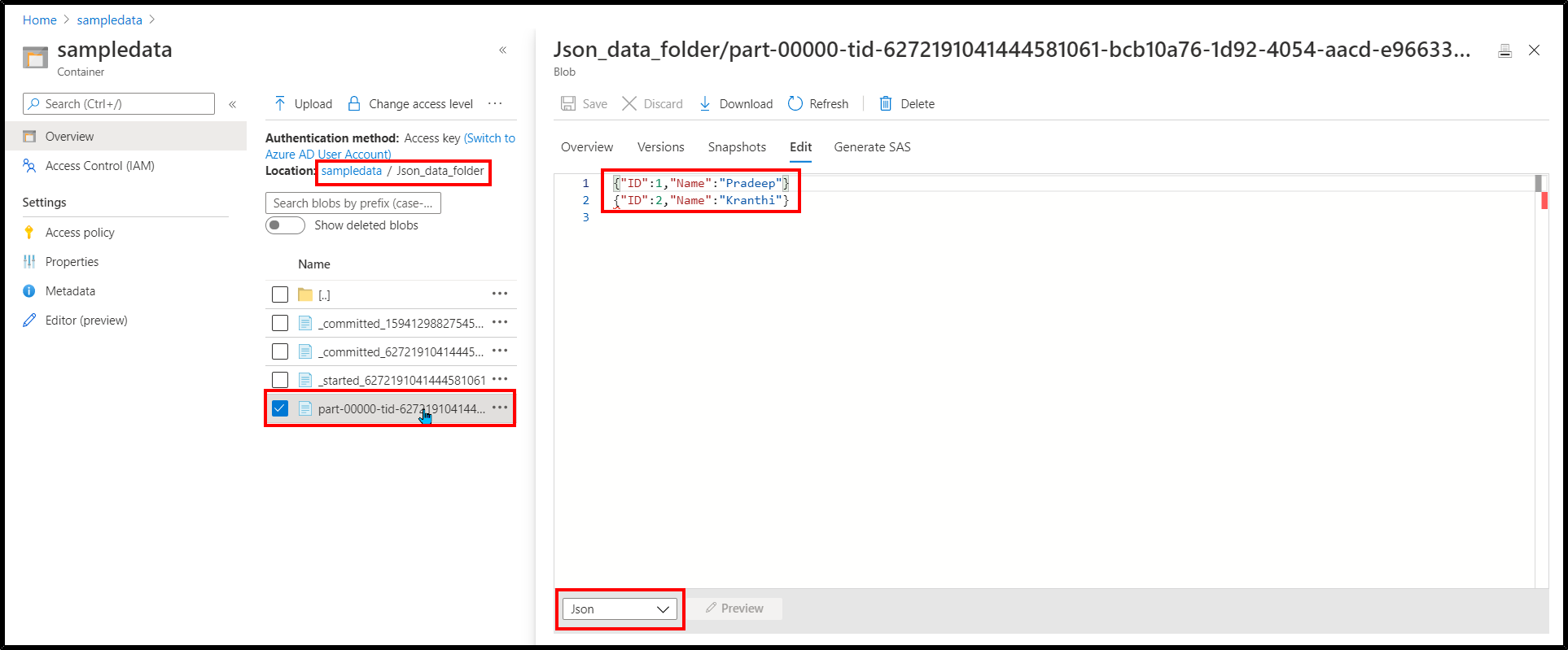
Hope this helps. Do let us know if you any further queries.
----------------------------------------------------------------------------------------
Do click on "Accept Answer" and Upvote on the post that helps you, this can be beneficial to other community members.
Hi PRADEEPCHEEKATLA-MSFT, Thanks very much for your response. The python code works for some reason is working intermittently. The scala code snippet throws error: not found: value df. Also, the table data I am trying to save as a json document has over 25 million + records and when saved to the container is 42 gb when I click on view/edit I see this File size of '42.59GB' exceeds max supported file size of '2.1MB.'
I assume this is just for viewing the raw data in the container but I could still work with the file. Also, is there a best practice where a file could be stored in a container or a file share? Please help me understand.
Regards
org.apache.spark.SparkException: Job aborted.
---------------------------------------------------------------------------
Py4JJavaError Traceback (most recent call last)
<command-2802701877950826> in <module>
9 df=spark.createDataFrame([Row(**i) for i in data])
10 df.show()
---> 11 df.write.mode("overwrite").json("wasbs://<file_system>@<storage-account-name>.blob.core.windows.net/hr/emp")
/databricks/spark/python/pyspark/sql/readwriter.py in json(self, path, mode, compression, dateFormat, timestampFormat, lineSep, encoding)
815 compression=compression, dateFormat=dateFormat, timestampFormat=timestampFormat,
816 lineSep=lineSep, encoding=encoding)
--> 817 self._jwrite.json(path)
818
819 @since(1.4)
Hi PRADEEPCHEEKATLA-MSFT, I apologize unable to post comments or reply correctly.
Thank you
Hello @Raj D ,
The above is python code snippet.
There is a limit of editing file in Azure portal. You can just edit a file in portal which size is under 2.05MB. If the file size is above you will receive this error message "
exceeds max supported file size of '2.1MB.'".
Always best practice to store the data in containers.
Could you please share the complete stack trace of the error message which you are experiencing?
Hello @Raj D ,
Yes, there is a known issue on Microsoft Q&A site to post comment below 1000 characters. This will be fixed soon.
Could you please share the complete stack trace of the error message which you are experiencing (try to post it by edit the answer below)?
Hi PRADEEPCHEEKATLA-MSFT, Thanks very much for your response. Please find the job aborted complete stack posted as an answer below. org.apache.spark.SparkException: Job aborted.
Hello @Raj D ,
This is not the complete stack trace of the error message, if you scroll down to the error message you will find something called as "Caused by".
To know exact reason, I would request you to check out the complete stack trace and try to find Caused by.
Hello @Raj D ,
Just checking in if you have had a chance to see the previous response. We need the following information to understand/investigate this issue further.
Hi PRADEEPCHEEKATLA-MSFT, For some reason run into error every once in a while. org.apache.spark.SparkException: Job aborted.
org.apache.spark.SparkException: Job aborted.
---------------------------------------------------------------------------
Py4JJavaError Traceback (most recent call last)
<command-2802701877950826> in <module>
9 df=spark.createDataFrame([Row(**i) for i in data])
10 df.show()
---> 11 df.write.mode("overwrite").json("wasbs://<file_system>@<storage-account-name>.blob.core.windows.net/hr/emp")
/databricks/spark/python/pyspark/sql/readwriter.py in json(self, path, mode, compression, dateFormat, timestampFormat, lineSep, encoding)
815 compression=compression, dateFormat=dateFormat, timestampFormat=timestampFormat,
816 lineSep=lineSep, encoding=encoding)
--> 817 self._jwrite.json(path)
818
819 @since(1.4)
/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py in __call__(self, *args)
1255 answer = self.gateway_client.send_command(command)
1256 return_value = get_return_value(
-> 1257 answer, self.gateway_client, self.target_id, self.name)
1258
1259 for temp_arg in temp_args: