Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
5,373 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ENS%3C/text%3E%3C/svg%3E)
Hi
we have a table in Synapse dedicated pool like
CREATE TABLE [dbo].[tlbInvoiceHeader]
(
[DimInvoiceID] [int] IDENTITY(1,1) NOT NULL,
[InvoiceID] [int] NOT NULL,
[InvoiceNumber] varchar NOT NULL,
[InvoiceDate] datetime2 NULL,
.
.
.
CONSTRAINT [tlbInvoiceHeader_PK] PRIMARY KEY NONCLUSTERED
(
[DimInvoiceID] ASC
) NOT ENFORCED
)
WITH
(
DISTRIBUTION = HASH ( [InvoiceNumber] ),
CLUSTERED COLUMNSTORE INDEX
)
GO
We have had a stored procedure (SP) that inserted data into the table, The developer had used "SET IDENTITY_INSERT" ON and OFF, why? please don't ask me, I know what you are thinking, anyways because of that we have duplicated records in the identity field ([DimInvoiceID]), and I have removed the "SET IDENTITY_INSERT" from the SP
To find and check for the duplicate I used
select [DimInvoiceID], count()
from [dbo].[tlbInvoiceHeader]
group by [DimInvoiceHeaderID]
having count() > 1
order by [DimInvoiceID] desc
the results are empty ? but we know that we have over 100 duplicated records, why doesn't COUNT work? this is a very very simple GROUP BY and COUNT statement
So I to wanted to make sure that I haven't missed anything I used CTE and it worked and showed me the duplicated records
the CTE was something like .....
;WITH CTE
AS (
SELECT [DuplicateCount] = ROW_NUMBER() OVER(PARTITION BY [Field1KeyRelated] ORDER BY [Field1KeyRelated])
, *
FROM [dbo].[tblXYZ]
)
SELECT *
FROM CTE
WHERE [DuplicateCount] > 1
;
it worked, which is fine
Question why is that the COUNT in a simple select statement does not work/display duplicated records, why and how?
Please help me to understand
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESS%3C/text%3E%3C/svg%3E)
Thanks for using Microsoft Q&A !!
I have checked this and I could see the same behavior as yours.
I could see that the “DimInvoiceId 1” here in the below is not getting grouped together, instead showing as individual counts.
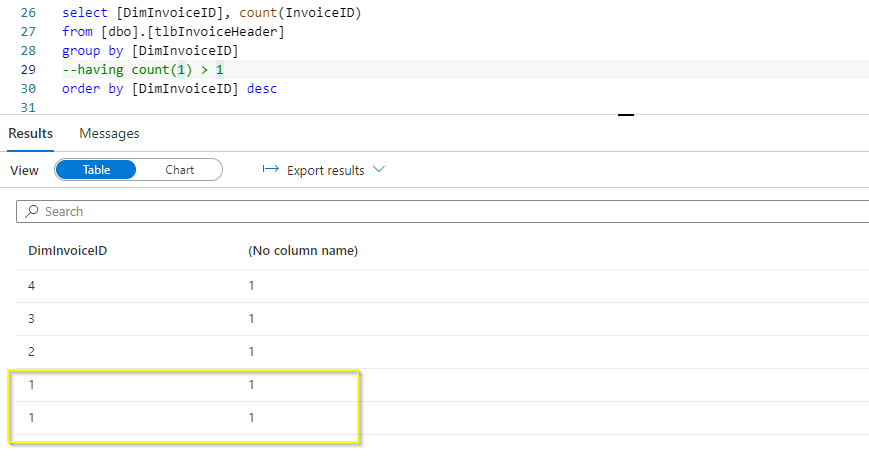
I am checking internally on this issue with the products team and get back to you.
Thanks
Saurabh
Hi , I am still working on it
Nik
Thanks @Nik - Shahriar Nikkhah . Sure. Thanks for letting me know.
Hi @Nik - Shahriar Nikkhah ,
As per internal discussion in your case what’s skewing the operation is the unique constraint "not enforced" declaration in the schema. Since there is really no constraints that can be applied in you schema, you can remove it completely and just declare the necessary indexes for performance requirements. You can try to experiment that and see the results.
Please check Primary, foreign, and unique keys - Azure Synapse Analytics documentation for details.
Please let me know if you have any other questions.
Thanks
Saurabh
We haven't heard back from you. Just wanted to check if you are you still facing the issue? In case If you already found a solution, would you please share it here with the community? Otherwise, let us know and we will continue to engage with you on the issue.
Thanks
Saurabh
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMA%3C/text%3E%3C/svg%3E)
This doesn't seem like a perfect solution. In data marts, we do not want to enforce a PK because the data can get very large; instead we use data integration to ensure only unique records are added. We still prefer having a PK because it signals to users what makes a record unique within the table; your solution means we lose that insight. It seems to me that Microsoft needs to fix this bug - otherwise, what is the use of having "not enforced" as a possible constraint setting?