Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
2,534 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBS%3C/text%3E%3C/svg%3E)
This is the line of code which results in the exception :
resultdf = tempdf.select(*[nested_columns]).distinct()
Exception in Spark 3.2.0 : ClassCastException: org.apache.spark.sql.types.ArrayType cannot be cast to org.apache.spark.sql.types.StructType
stack trace:
java.lang.ClassCastException: org.apache.spark.sql.types.ArrayType cannot be cast to org.apache.spark.sql.types.StructType
at org.apache.spark.sql.catalyst.expressions.GetStructField.childSchema$lzycompute(complexTypeExtractors.scala:107)
at org.apache.spark.sql.catalyst.expressions.GetStructField.childSchema(complexTypeExtractors.scala:107)
at org.apache.spark.sql.catalyst.expressions.GetStructField.$anonfun$extractFieldName$1(complexTypeExtractors.scala:117)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.catalyst.expressions.GetStructField.extractFieldName(complexTypeExtractors.scala:117)
at org.apache.spark.sql.catalyst.optimizer.GeneratorNestedColumnAliasing$$anonfun$1$$anonfun$$nestedInanonfun$applyOrElse$1$1.applyOrElse(NestedColumnAliasing.scala:415)
at org.apache.spark.sql.catalyst.optimizer.GeneratorNestedColumnAliasing$$anonfun$1$$anonfun$$nestedInanonfun$applyOrElse$1$1.applyOrElse(NestedColumnAliasing.scala:411)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformUpWithPruning$4(TreeNode.scala:543)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:86)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformUpWithPruning(TreeNode.scala:543)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:512)
at org.apache.spark.sql.catalyst.optimizer.GeneratorNestedColumnAliasing$$anonfun$1.$anonfun$applyOrElse$1(NestedColumnAliasing.scala:411)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:286)
at scala.collection.immutable.Set$Set1.foreach(Set.scala:141)
at scala.collection.TraversableLike.map(TraversableLike.scala:286)
at scala.collection.TraversableLike.map$(TraversableLike.scala:279)
at scala.collection.AbstractSet.scala$collection$SetLike$$super$map(Set.scala:53)
at scala.collection.SetLike.map(SetLike.scala:105)
at scala.collection.SetLike.map$(SetLike.scala:105)
at scala.collection.AbstractSet.map(Set.scala:53)
at org.apache.spark.sql.catalyst.optimizer.GeneratorNestedColumnAliasing$$anonfun$1.applyOrElse(NestedColumnAliasing.scala:410)
at org.apache.spark.sql.catalyst.optimizer.GeneratorNestedColumnAliasing$$anonfun$1.applyOrElse(NestedColumnAliasing.scala:408)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:485)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:86)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:485)
at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$transformExpressionsDownWithPruning$1(QueryPlan.scala:154)
at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$mapExpressions$1(QueryPlan.scala:195)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:86)
at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpression$1(QueryPlan.scala:195)
at org.apache.spark.sql.catalyst.plans.QueryPlan.recursiveTransform$1(QueryPlan.scala:206)
at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$mapExpressions$4(QueryPlan.scala:216)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:327)
at org.apache.spark.sql.catalyst.plans.QueryPlan.mapExpressions(QueryPlan.scala:216)
at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpressionsDownWithPruning(QueryPlan.scala:154)
at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpressionsWithPruning(QueryPlan.scala:125)
at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpressions(QueryPlan.scala:103)
at org.apache.spark.sql.catalyst.optimizer.GeneratorNestedColumnAliasing$.unapply(NestedColumnAliasing.scala:408)
at org.apache.spark.sql.catalyst.optimizer.ColumnPruning$$anonfun$apply$14.applyOrElse(Optimizer.scala:886)
at org.apache.spark.sql.catalyst.optimizer.ColumnPruning$$anonfun$apply$14.applyOrElse(Optimizer.scala:841)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:485)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:86)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:485)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:268)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:264)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$4(TreeNode.scala:500)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren(TreeNode.scala:1139)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren$(TreeNode.scala:1138)
at org.apache.spark.sql.catalyst.plans.logical.UnaryNode.mapChildren(LogicalPlan.scala:187)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:500)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:268)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:264)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$4(TreeNode.scala:500)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren(TreeNode.scala:1139)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren$(TreeNode.scala:1138)
at org.apache.spark.sql.catalyst.plans.logical.UnaryNode.mapChildren(LogicalPlan.scala:187)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:500)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:268)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:264)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$3(TreeNode.scala:490)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren(TreeNode.scala:1139)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren$(TreeNode.scala:1138)
at org.apache.spark.sql.catalyst.plans.logical.UnaryNode.mapChildren(LogicalPlan.scala:187)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:490)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:268)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:264)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$3(TreeNode.scala:490)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren(TreeNode.scala:1139)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren$(TreeNode.scala:1138)
at org.apache.spark.sql.catalyst.plans.logical.UnaryNode.mapChildren(LogicalPlan.scala:187)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:490)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:268)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:264)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformWithPruning(TreeNode.scala:451)
at org.apache.spark.sql.catalyst.optimizer.ColumnPruning$.apply(Optimizer.scala:841)
at org.apache.spark.sql.catalyst.optimizer.ColumnPruning$.apply(Optimizer.scala:838)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$3(RuleExecutor.scala:216)
at com.databricks.spark.util.FrameProfiler$.record(FrameProfiler.scala:80)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$2(RuleExecutor.scala:216)
at scala.collection.LinearSeqOptimized.foldLeft(LinearSeqOptimized.scala:126)
at scala.collection.LinearSeqOptimized.foldLeft$(LinearSeqOptimized.scala:122)
at scala.collection.immutable.List.foldLeft(List.scala:91)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1(RuleExecutor.scala:213)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1$adapted(RuleExecutor.scala:205)
at scala.collection.immutable.List.foreach(List.scala:431)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:205)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$executeAndTrack$1(RuleExecutor.scala:184)
at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:109)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.executeAndTrack(RuleExecutor.scala:184)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$optimizedPlan$1(QueryExecution.scala:163)
at com.databricks.spark.util.FrameProfiler$.record(FrameProfiler.scala:80)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:134)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$executePhase$1(QueryExecution.scala:232)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:854)
at org.apache.spark.sql.execution.QueryExecution.executePhase(QueryExecution.scala:232)
at org.apache.spark.sql.execution.QueryExecution.optimizedPlan$lzycompute(QueryExecution.scala:159)
at org.apache.spark.sql.execution.QueryExecution.optimizedPlan(QueryExecution.scala:155)
at org.apache.spark.sql.execution.QueryExecution.assertOptimized(QueryExecution.scala:173)
at org.apache.spark.sql.execution.QueryExecution.executedPlan$lzycompute(QueryExecution.scala:192)
at org.apache.spark.sql.execution.QueryExecution.executedPlan(QueryExecution.scala:189)
at org.apache.spark.sql.execution.QueryExecution.simpleString(QueryExecution.scala:265)
at org.apache.spark.sql.execution.QueryExecution.org$apache$spark$sql$execution$QueryExecution$$explainString(QueryExecution.scala:328)
at org.apache.spark.sql.execution.QueryExecution.explainStringLocal(QueryExecution.scala:292)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withCustomExecutionEnv$5(SQLExecution.scala:165)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:319)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withCustomExecutionEnv$1(SQLExecution.scala:146)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:854)
at org.apache.spark.sql.execution.SQLExecution$.withCustomExecutionEnv(SQLExecution.scala:113)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:269)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3898)
at org.apache.spark.sql.Dataset.collectResult(Dataset.scala:3092)
at com.databricks.backend.daemon.driver.OutputAggregator$.withOutputAggregation0(OutputAggregator.scala:268)
at com.databricks.backend.daemon.driver.OutputAggregator$.withOutputAggregation(OutputAggregator.scala:102)
at com.databricks.backend.daemon.driver.PythonDriverLocalBase.generateTableResult(PythonDriverLocalBase.scala:586)
at com.databricks.backend.daemon.driver.PythonDriverLocal.computeListResultsItem(PythonDriverLocal.scala:619)
at com.databricks.backend.daemon.driver.PythonDriverLocalBase.genListResults(PythonDriverLocalBase.scala:493)
at com.databricks.backend.daemon.driver.PythonDriverLocal.$anonfun$getResultBufferInternal$1(PythonDriverLocal.scala:674)
at com.databricks.backend.daemon.driver.PythonDriverLocal.withInterpLock(PythonDriverLocal.scala:555)
at com.databricks.backend.daemon.driver.PythonDriverLocal.getResultBufferInternal(PythonDriverLocal.scala:634)
at com.databricks.backend.daemon.driver.DriverLocal.getResultBuffer(DriverLocal.scala:673)
at com.databricks.backend.daemon.driver.PythonDriverLocal.outputSuccess(PythonDriverLocal.scala:597)
at com.databricks.backend.daemon.driver.PythonDriverLocal.$anonfun$repl$6(PythonDriverLocal.scala:222)
at com.databricks.backend.daemon.driver.PythonDriverLocal.withInterpLock(PythonDriverLocal.scala:555)
at com.databricks.backend.daemon.driver.PythonDriverLocal.repl(PythonDriverLocal.scala:209)
at com.databricks.backend.daemon.driver.DriverLocal.$anonfun$execute$13(DriverLocal.scala:564)
at com.databricks.logging.UsageLogging.$anonfun$withAttributionContext$1(UsageLogging.scala:215)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
at com.databricks.logging.UsageLogging.withAttributionContext(UsageLogging.scala:213)
at com.databricks.logging.UsageLogging.withAttributionContext$(UsageLogging.scala:210)
at com.databricks.backend.daemon.driver.DriverLocal.withAttributionContext(DriverLocal.scala:50)
at com.databricks.logging.UsageLogging.withAttributionTags(UsageLogging.scala:251)
at com.databricks.logging.UsageLogging.withAttributionTags$(UsageLogging.scala:243)
at com.databricks.backend.daemon.driver.DriverLocal.withAttributionTags(DriverLocal.scala:50)
at com.databricks.backend.daemon.driver.DriverLocal.execute(DriverLocal.scala:541)
at com.databricks.backend.daemon.driver.DriverWrapper.$anonfun$tryExecutingCommand$1(DriverWrapper.scala:693)
at scala.util.Try$.apply(Try.scala:213)
at com.databricks.backend.daemon.driver.DriverWrapper.tryExecutingCommand(DriverWrapper.scala:685)
at com.databricks.backend.daemon.driver.DriverWrapper.getCommandOutputAndError(DriverWrapper.scala:526)
at com.databricks.backend.daemon.driver.DriverWrapper.executeCommand(DriverWrapper.scala:638)
at com.databricks.backend.daemon.driver.DriverWrapper.runInnerLoop(DriverWrapper.scala:431)
at com.databricks.backend.daemon.driver.DriverWrapper.runInner(DriverWrapper.scala:374)
at com.databricks.backend.daemon.driver.DriverWrapper.run(DriverWrapper.scala:225)
at java.lang.Thread.run(Thread.java:748)

Hi @Bajaj, Smita ,
Thank you for posting query in Microsoft Q&A Platform.
I created two clusters in Azure data bricks. One with Spark version 3.1.2 and another with spark version 3.2.0.
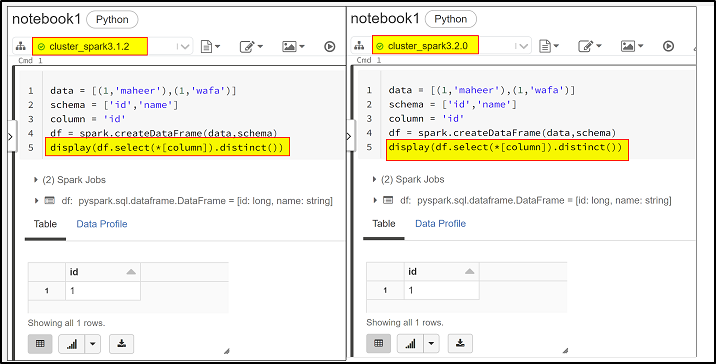
Created a sample notebook with Python as default language and sample code in to to use select() and distinct() functions. I ran my notebook with both clusters with spark version 3.1.2 & spark version 3.2.0. I see everything works good to me. Kindly check below screenshot.
Could you please share your full code if its not the case with your issue. So that i can try same and help.
Hope this helps. Please let us know if any further queries.
---------------
Please consider hitting Accept Answer button. Accepted answers helps community as well.
Hi @Bajaj, Smita ,
Just checking in to see if the below answer helped. If this answers your query, do click  and upvote
and upvote  for the same. And, if you have any further query do let us know.
for the same. And, if you have any further query do let us know.
Following to see if the below answer helped. If this answers your query, do click and upvote for the same. And, if you have any further query do let us know.