Azure Cosmos DB
An Azure NoSQL database service for app development.
1,906 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJ%3C/text%3E%3C/svg%3E)
First pipeline in ADF is call external REST API to get the json file store in blob storage and then use the second pipeline to push the json into cosmosDB from blob.
Overall process is smooth but we found that cosmosDB will always create a new json file in document collecter with different "ObjectID" even it is same json in blob, it will create a lot of json when second pipeline auto trigger the schedule jobs for push json. Second pipeline we are using upsert for write behaviour alredy
Just want to not duplicate more same json file in cosmosDB, keep in one
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Jack and welcome to Microsoft Q&A.
It sounds like you are having trouble with making your upsert operation into Cosmos behave like an upsert rather than an insert.
To update an object instead of creating a new one, you must specify the ObjectID. Otherwise the ObjectID is auto-generated and new item is inserted.
If your source JSON have a property you would like to use as an ID, leverage that in the mapping section of your copy activity like below picture.
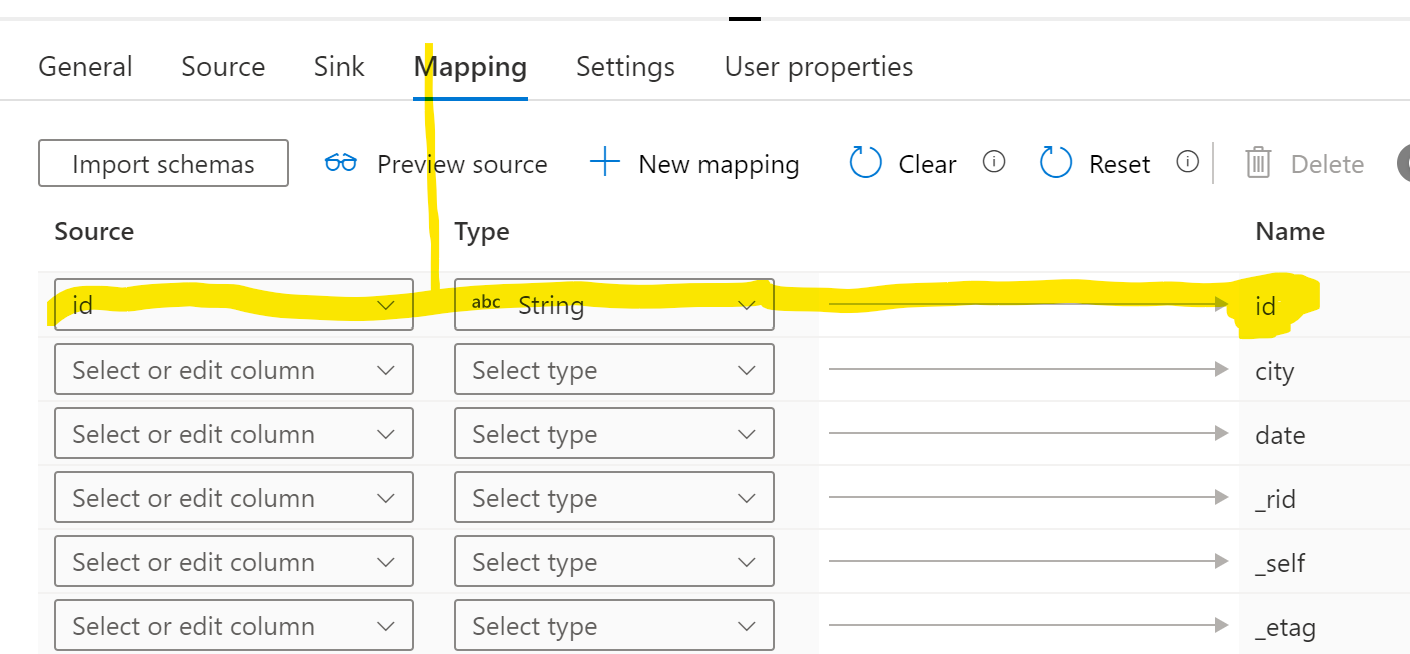
In connector-azure-cosmos-db: Cosmos as Sink, this is called out:
Describes how to write data to Azure Cosmos DB. Allowed values: insert and upsert.
The behavior of upsert is to replace the document if a document with the same ID already exists; otherwise, insert the document.
Note: The service automatically generates an ID for a document if an ID isn't specified either in the original document or by column mapping. This means that you must ensure that, for upsert to work as expected, your document has an ID.
Oh, I think it's troublesome and haven't do the data mapping.
It's work to keep in one after data mapping, thanks