Azure AI Speech
An Azure service that integrates speech processing into apps and services.
2,074 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ES%3C/text%3E%3C/svg%3E)
The "Real-Time Speech-To-Text" service really uses my Speech Service, and its model that I made with uploaded data. (accessing with my subscription key, region).
It is the question:
Does the "Multi-device Conversation" function use my model (made in Speech Studio) of Speech Service or Speech Services itself?
I ask it because I gave same subscription key, region and the endpoint of my model on both functions, and "Real-Time Speech-To-Text" gives BETTER results than "Multi-device conversation". (My language is Hungarian, and the S2T for deafs)
Real-Time Speech-To-Text: https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/speech-to-text
Multi-device conversation: https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/multi-device-conversation
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYM%3C/text%3E%3C/svg%3E)
Hello, thank you for reaching out to us here.
I think you are mentioning two scenarios:
Please correct me if I misunderstood since the first link you share is the document of general Speech to Text service.
For the Multi-device conversation feature, everyone use it's conversation ID to join, this feature uses Speech Service default model.
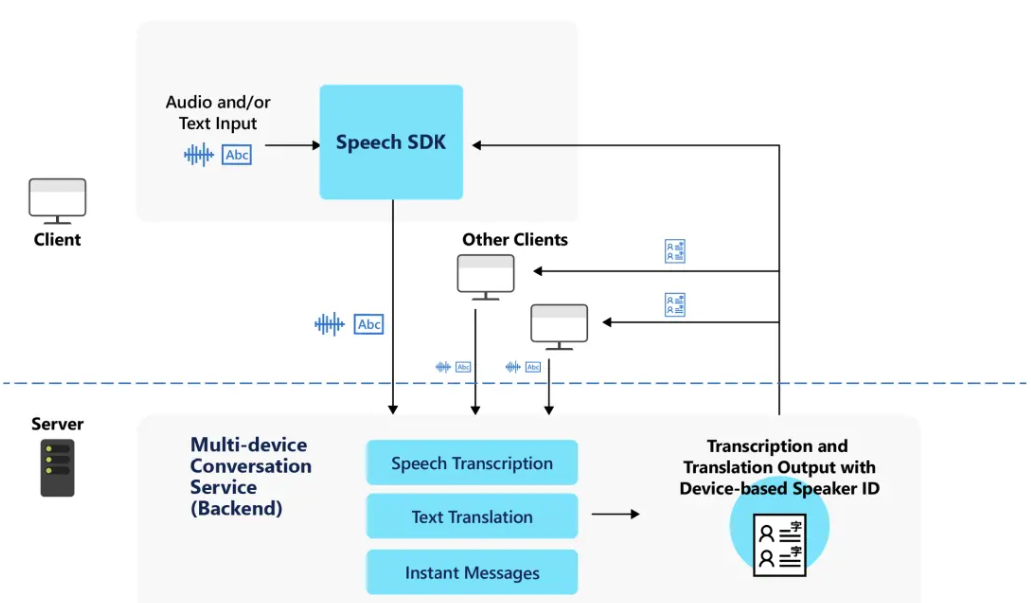
For the Real time conversation transcription, it creates voice signatures for the conversation participants so that they can be identified as unique speakers, but this is not necessary if you don't want to pre-enroll users.
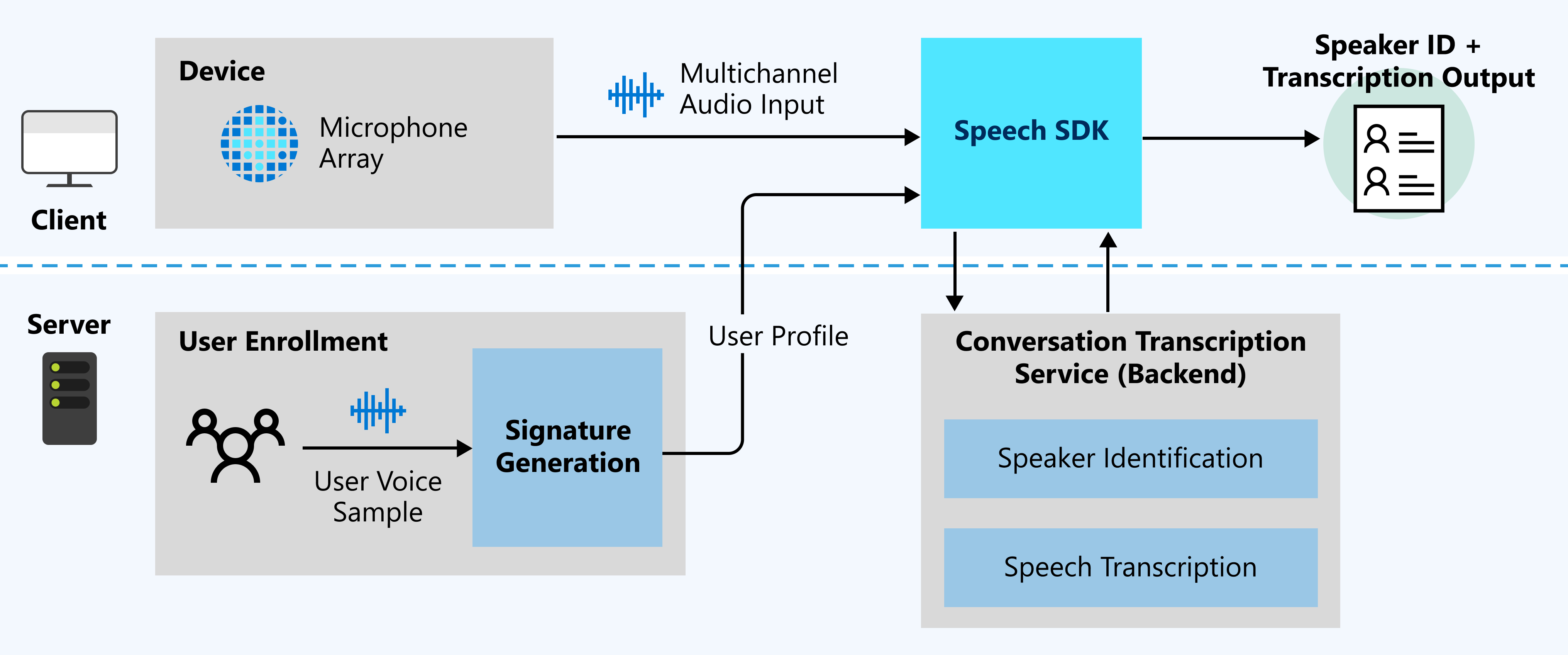
Both of them use Speech SDK default models, but Real time conversation transcription has a improvement feature which may make the result better.
If you want to train model by your own data set, I think you are mentioning Custom Speech. By using Custom Speech, you can train and deploy your own model with you data set.
https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/custom-speech-overview
Hope this helps! Please let us know if you have more questions.
Please kindly accept the answer if you feel helpful, thank you.
Regards,
Yutong
Hi!
Thank you for the answering.
Does the "Multi-device conversation" have any improvement features?
Regards,
Benedek.
For now, there is no improvement features for Multi-device conversation, please let us know your requirement so that we can look into it.
Thank you!
-Please kindly accept the answer if you feel helpful, thank you!
Regards,
Yutong
My first requirement is the Speech can recognize the English words (for example IT words, Jira, Confluence, Azure, etc.) in Hungarian context, main language (for example Hungarian language).
Second is that I can use "Speech Studio" on"multi-device" scenario, too as host, too as participant (i mean, they can access to the actual model of Speech Studio instead of default, for better results (it would be easier for deafs to understand the situations).
Thank you.