Azure AI services
A group of Azure services, SDKs, and APIs designed to make apps more intelligent, engaging, and discoverable.
2,645 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESS%3C/text%3E%3C/svg%3E)
We are trying to use Microsoft AI for contract document custom entity extraction. For example when a contract document is uploaded, we have to extract the Party Name, Address , Effective Date , etc. .
Any help in identifying the right API is highly appreciated.
Is there any trained model available for contract document extraction ?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYM%3C/text%3E%3C/svg%3E)
Thanks for reaching out to us. As you mentioned, you want a trained model to extract content directly. I would recommend you to try Form Recognizer or Named Entity Recognition (NER).
For Named Entity Recognition, the difference between it and Custom Entity Extraction is, it uses the default model, you don't need to train it: https://learn.microsoft.com/en-us/azure/cognitive-services/language-service/named-entity-recognition/overview
For Form Recognizer, I recommend general document model, the General document preview model combines powerful Optical Character Recognition (OCR) capabilities with deep learning models to extract key-value pairs and entities from documents. General document is only available with the preview (v3.0) API.
https://learn.microsoft.com/en-us/azure/applied-ai-services/form-recognizer/concept-general-document
If you need better performance, custom NER what you have tried should be a better choice, it enables its users to build custom AI models to extract domain-specific entities from unstructured text, such as contracts or financial documents. By creating a Custom NER project, developers can iteratively tag data, train, evaluate, and improve model performance before making it available for consumption. The quality of the tagged data greatly impacts model performance.
https://learn.microsoft.com/en-us/azure/cognitive-services/language-service/custom-named-entity-recognition/overview
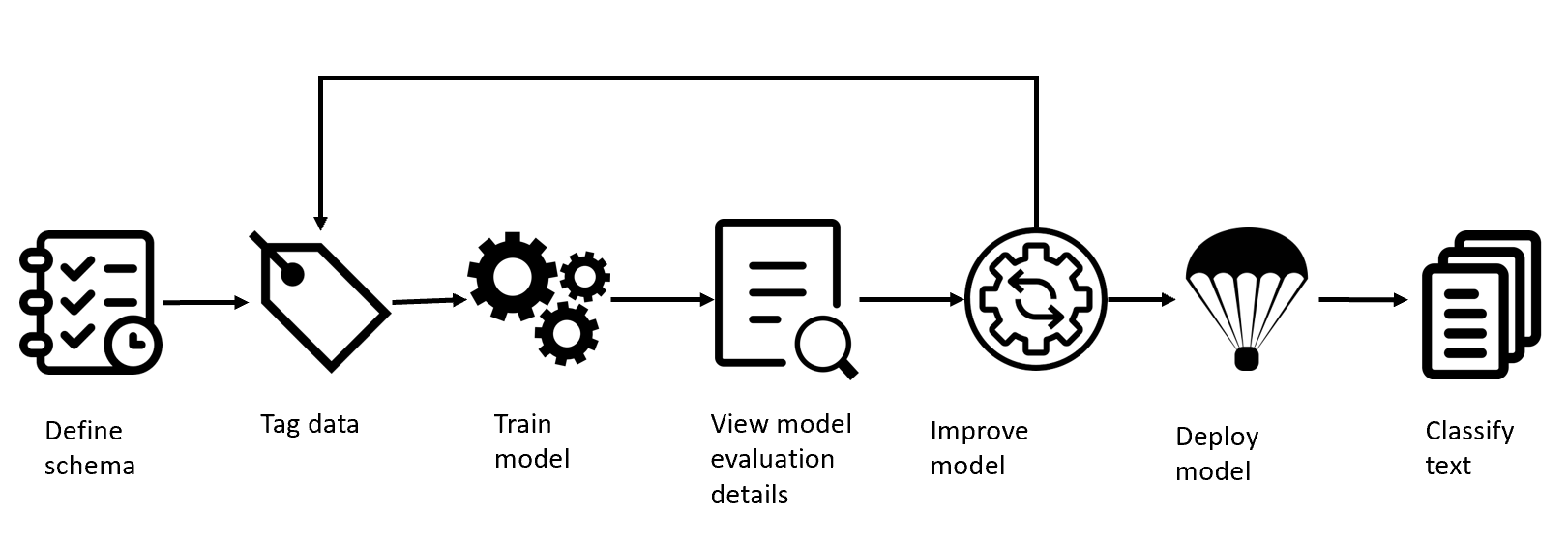
What you need to do is basically tagging your data. Please try above to see which is the best choice for your business.
Hope this helps, please let us know if you need further assistance.
Please kindly accept the answer if you feel helpful, thank you !
Regards,
Yutong
Thanks for the reply
We are using custom NER service for extracting entity from contract agreement, We tagged and trained almost 50 different agreements. Upon analysis of test results it does not look accurate, Any help in improving the result set for custom NER model?
Improve the model is the next step I would recommend you to do, please see this guidance and have a try to review the test set and examine the data distribution.
Hope this helps!
Regards,
Yutong
when we did training with 20 files, we got a success model . While we added more files and tagged , Training have no entity recognition, Is that any internal error? What could be the reason?
Do we need to tag all occurrence of entity in a file?