Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
5,378 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

I have 4 data flows, that need the same transformation steps from JSON to Parquet.
I get a new dataset for each flow once every hour. Every set contails 8000-13000 rows. These new files land in a "hot" folder. I want to collect these files and add them to the parquet sink in stead of running a full load with "clean the folder" option.
I have successfully done the initial load, and I have had several successful incremental loads, but after a while, the incremental loads stop working intermittently. I get the same error on the failing data flows:
{"message":"Job failed due to reason: at Source 'Flow3JsonSubscriptions': org.apache.spark.sql.AnalysisException: Unable to infer schema for JSON. It must be specified manually.;. Details:org.apache.spark.sql.AnalysisException: Unable to infer schema for JSON. It must be specified manually.;\n\tat org.apache.spark.sql.execution.datasources.DataSource$$anonfun$7.apply(DataSource.scala:198)\n\tat org.apache.spark.sql.execution.datasources.DataSource$$anonfun$7.apply(DataSource.scala:198)\n\tat scala.Option.getOrElse(Option.scala:121)\n\tat org.apache.spark.sql.execution.datasources.DataSource.getOrInferFileFormatSchema(DataSource.scala:197)\n\tat org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:386)\n\tat org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:242)\n\tat org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:231)\n\tat com.microsoft.dataflow.transformers.formats.JSONFileReader$$anonfun$read$2$$anonfun$apply$2$$anonfun$apply$4$$anonfun$apply$5.apply(JSONFileReader.scala:41)\n\tat com.microsoft.dataflow.transformers.formats.JSONFileReader$$anonfun$read$2$$anonfun$apply$2$$anonfun$apply$4$$anonfun$apply$5.apply(JSONFileReader.scala:32)\n\t","failureType":"UserError","target":"Get all subscriptions","errorCode":"DFExecutorUserError"}
I see no differences in schemas between the parquet sink and the Json source, taking the transformations into account. REsetting schemas does not change anything. It still fails intermittently
How can I debug this further?
Looking closer at the logs in Apache Spark applications, where the Dataflow logs seem to reside, I see, that every time I get the error described, another error is in the Apache log shown below.
All Apache Spark applications Dataflows succeed according to the log overview (or at least they are green).
A successful run looks like this:
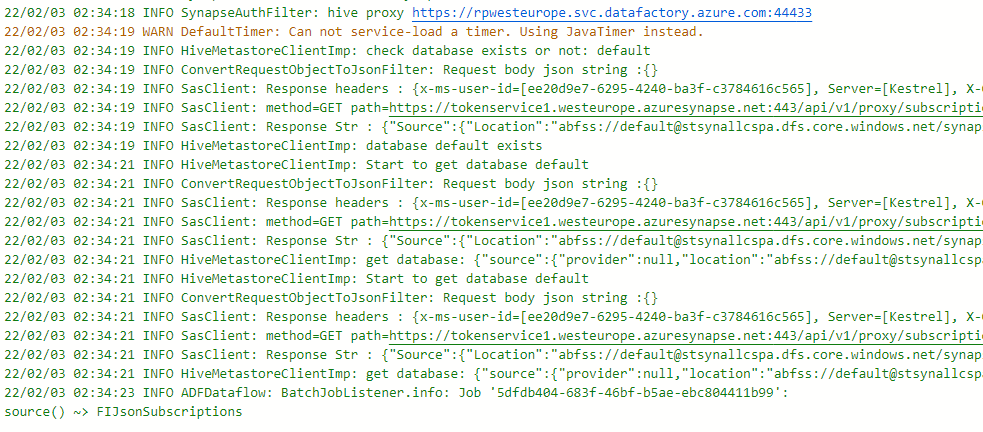
And a failing run looks like this:
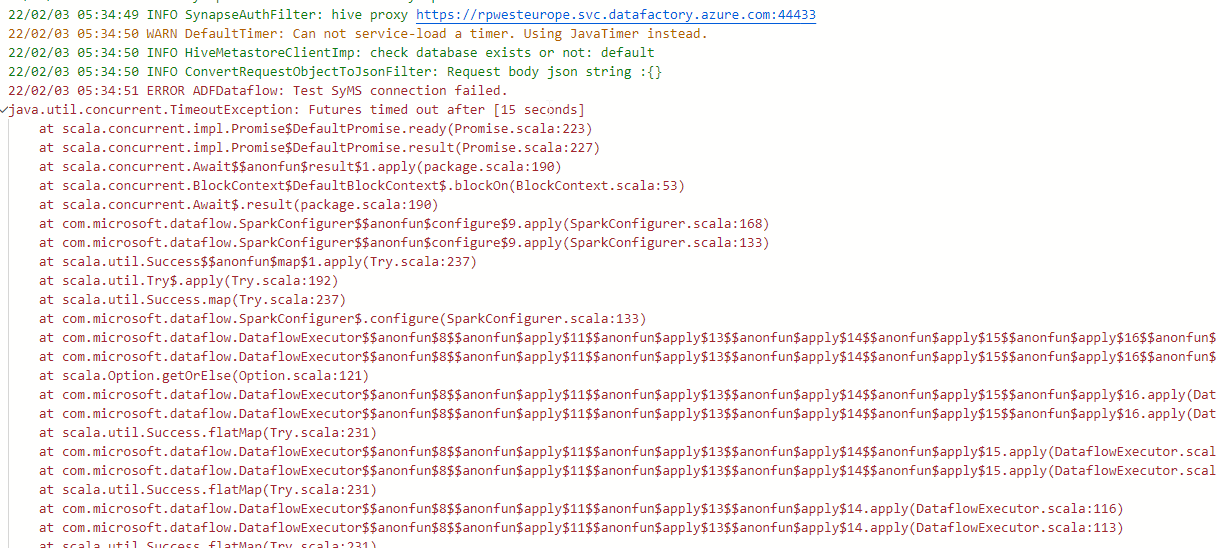
In the failed run, I get the error in the initial question AFTER the error above:
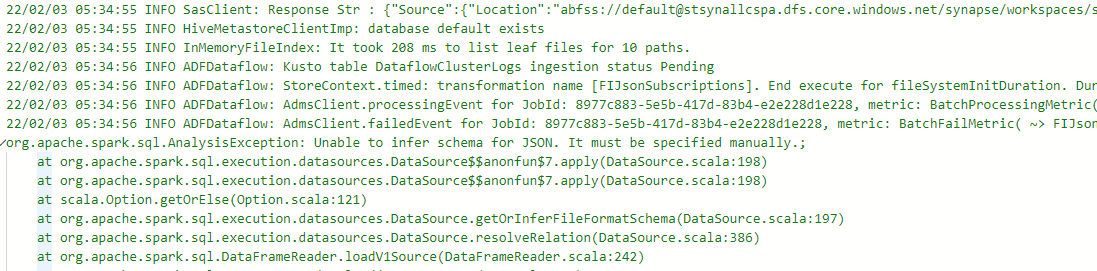
It seems that the first error "Test SyMS connection failed" is causing the second error to occur, but only the second error is surfaced to the user.
Looking a little closer at the logs, it seems that SyMS is emitted by the SasClient connecting to the storage account where the source files reside.

Hi @Axel B Andersen ,
Thank you for posting query in Microsoft Q&A Platform.
Above error usually occurs in below mentioned scenarios.
Could you please check in your case if any one of this happening and try to avoid them to resolve issue.
Hope this helps. If not, kindly share more details on your source location path and file name details. So that we can try to repro same and help.
----------------
Please consider hitting Accept Answer. Accepted answers helps community as well.
Hi Shaink,
Files all start with s, there is content in all files, the files are there and available.
I have a premier support case on the issue now. Further details may be too sensitive for public support.
Thanks,
Yes sharing sensitive information may be harmful. Good that you have created support case. Thank you.