' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ECD%3C/text%3E%3C/svg%3E)
4,827 questions
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBS%3C/text%3E%3C/svg%3E)
PDF is programing language that draws text and images. the language is a simple stack machine. to help in parsing PDF, tags support was added to help define the document. in postscript the % is the comment character, %% is used to identify a structure tag
sample hello world:
%!PS
/Palatino-Roman 20 selectfont
300 400 moveto
(Hello, World!) show
showpage
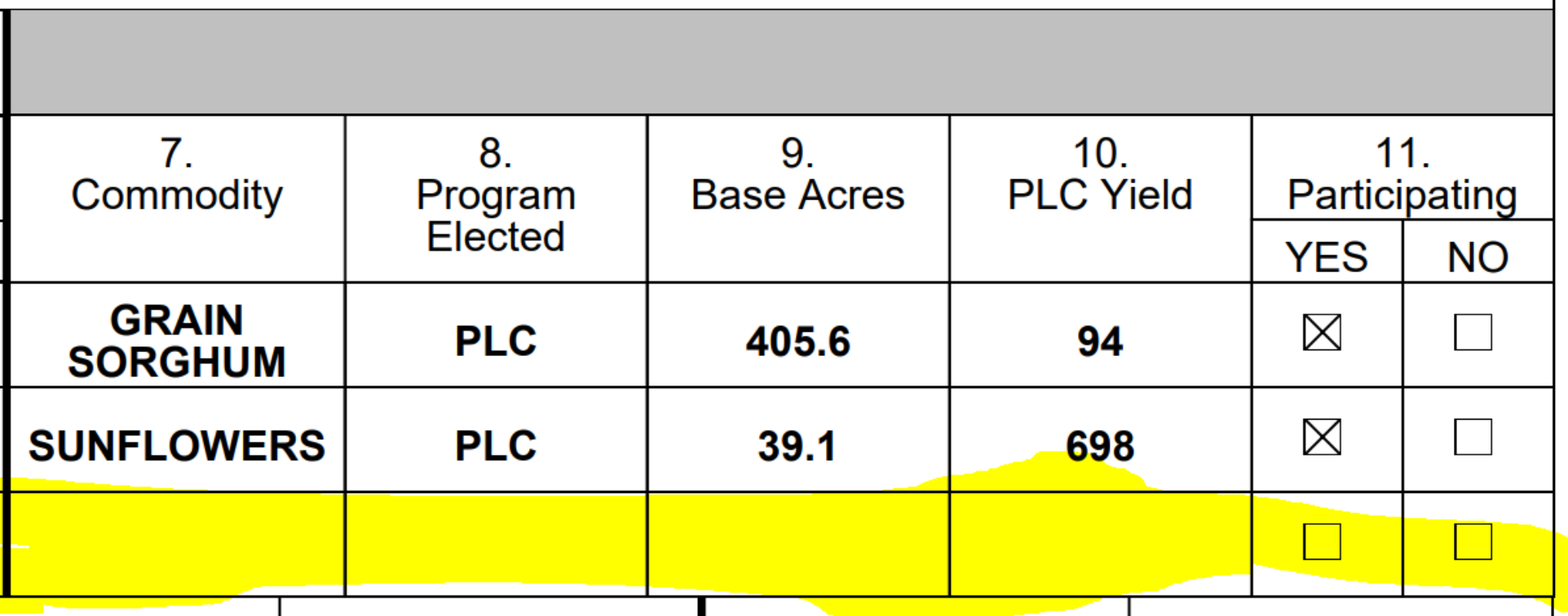
how well a PDF file can be parsed depends on how well the ps program was written, did it follow tag conventions used by the parser. most likely in your sample, the table is a text array, and only has 2 rows of data.
note: postscript supports arrays of arrays, so a text table should follow this structure. the data and the code to draw the borders are seperate.