' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)

4,707 questions
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYM%3C/text%3E%3C/svg%3E)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPC%3C/text%3E%3C/svg%3E)
You could use this to track the progress and give you an estimate on the completion time.
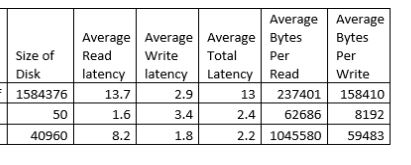
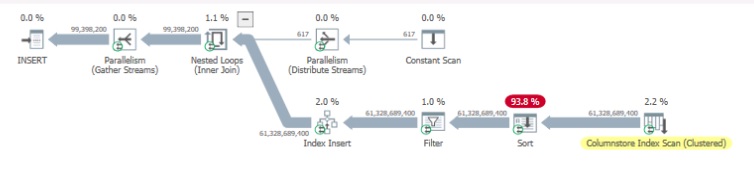
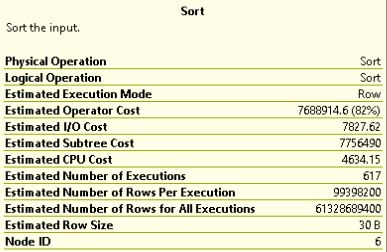
From you plan it looks like the sorting consumes most of the CPU
Also I might be obvious but try to do this when the there is either no or minimal load ...
Basically you check set SET STATISTICS PROFILE ON; in the where you will create run the CREATE INDEX script and note the SPID and enter in in the in the query below in another tab.
This will help you to understand if after 2 hours you were at 99% or still at 10%.
/*
remember to set
SET STATISTICS PROFILE ON;
in index creation script
*/
DECLARE @SPID INT = 64;
;WITH agg AS
(
SELECT SUM(qp.[row_count]) AS [RowsProcessed],
SUM(qp.[estimate_row_count]) AS [TotalRows],
MAX(qp.last_active_time) - MIN(qp.first_active_time) AS [ElapsedMS],
MAX(IIF(qp.[close_time] = 0 AND qp.[first_row_time] > 0,
[physical_operator_name],
N'<Transition>')) AS [CurrentStep]
FROM sys.dm_exec_query_profiles qp
WHERE qp.[physical_operator_name] IN (N'Table Scan', N'Clustered Index Scan', N'Sort')
AND qp.[session_id] = @SPID
), comp AS
(
SELECT *,
([TotalRows] - [RowsProcessed]) AS [RowsLeft],
([ElapsedMS] / 1000.0) AS [ElapsedSeconds]
FROM agg
)
SELECT [CurrentStep],
[TotalRows],
[RowsProcessed],
[RowsLeft],
CONVERT(DECIMAL(5, 2),
(([RowsProcessed] * 1.0) / [TotalRows]) * 100) AS [PercentComplete],
[ElapsedSeconds],
(([ElapsedSeconds] / [RowsProcessed]) * [RowsLeft]) AS [EstimatedSecondsLeft],
DATEADD(SECOND,
(([ElapsedSeconds] / [RowsProcessed]) * [RowsLeft]),
GETUTCDATE()) AS [EstimatedCompletionTime]
FROM comp;
see this for reference:
https://dba.stackexchange.com/questions/139191/sql-server-how-to-track-progress-of-create-index-command