Azure Data Lake Storage
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
1,426 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

Hi we have been experiencing some peculiarities in reading files from within the connected storage of Synapse Analytics over the last few days. These have been experienced while using pyspark in Notebooks.
Our initial issue started using the pandas method read_excel. We used this method to read an excel sheet using this code which worked on Monday 2022-02-21.
import pandas as pd
adslpath ='abfss://STORAGEACCOUNT.dfs.core.windows.net/CONTAINER/AssetManagement/Bronze/Raw/NOJV/FILE.xlsx'
pdf = pd.read_excel(adslpath, sheet_name='Page1', nrows=60,usecols='A:T')
This stopped working on Wednesday (2022-02-23) giving the error:
FileNotFoundError: [Errno 2] No such file or directory: 'abfss://STORAGEACCOUNT@MetContainer .dfs.core.windows.net/AssetManagement/Bronze/Raw/NOJV/FILE.xlsx'
We found we could connect to this with an Https link to the same source e.g.,
pdf = pd.read_excel(
r'https://CONTAINER.dfs.core.windows.net/dafdlfsd01/AssetManagement/Bronze/Raw/NOJV//FILE.xlsx?sv=2020-08-04&ss=bfqt&srt=sco&sp=rwdlacupx&se=2024-12-01T17:44:05Z&st=2022-02-24T09:44:05Z&spr=https&sig=NnT1Qv8uXMkgh3RQKBOvJ%2Bch%2BVtI6GF7r4ZSdTMEOg8%3D', sheet_name='Page1', nrows=60,usecols='A:T')
Note the use of a Shared Access Signature which does add complexity as this will need to be refreshed periodically.
While content that we have an approach that would work we continued our development which gets the files we want to read using a loop of files utilizing the method mssparkutils.fs.ls("Your directory path") as of yesterday - 2022-02-24 - we started experiencing issues with this method. It turns out this stopped accepting URL but would accept abfss links.
from notebookutils import mssparkutils
adslpath ='abfss://CONTAINER.dfs.core.windows.net/STORAGEACCOUNT/AssetManagement/Bronze/Raw/NOJV//'
# abfsspath = [file for file in mssparkutils.fs.ls(adslpath)]
# folder = [file for file in mssparkutils.fs.ls('https://CONTAINER.dfs.core.windows.net/STORAGEACCOUNT/AssetManagement/Bronze/Raw/NOJV//')]
folder = [file for file in mssparkutils.fs.ls('https://CONTAINER.blob.core.windows.net/STORAGEACCOUNT/AssetManagement/Bronze/Raw/NOJV//')]
Since this morning we now find each implementation of this method fails.
We have also noticed some changes to the nature of the display within synapse of the file explorer - though only for some users.
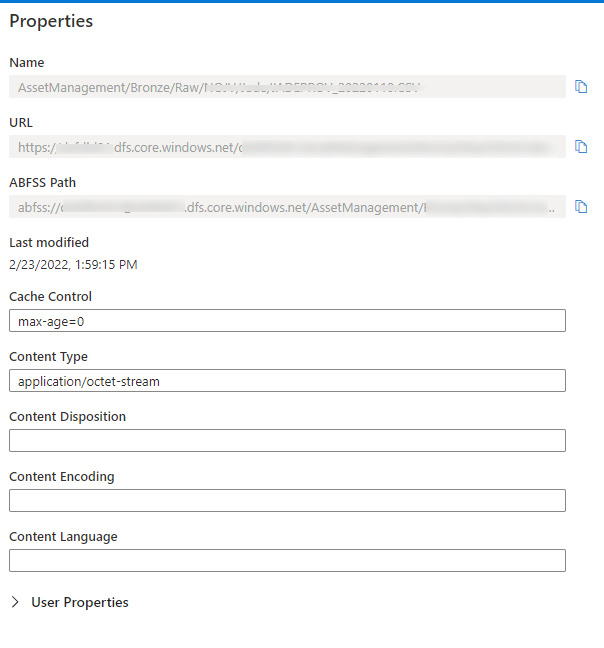
This has been replaced by this:
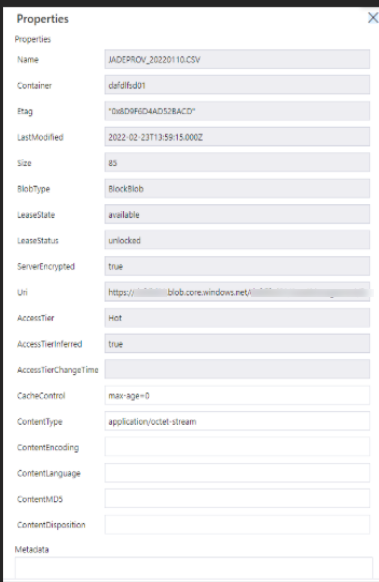
The big change here seems to be the introduction of the URI and the loss of the ABFSS Path and URL. This points to a shift to this from the older approach to the new approach.
We have a implementation with a range of clients which may now be in the process of breaking and have not see any indication of changes coming to this. The loss of the functionality in Microsoft Spark Utilities in particular is troubling. I have a number of questions.
Many thanks.
Stephen Connell.
Quick update on the notebookutils list method.
for URI and URL I get the error
Py4JJavaError: An error occurred while calling z:mssparkutils.fs.ls.
: java.lang.UnsupportedOperationException
However for ABFSS I get a different error
Py4JJavaError: An error occurred while calling z:mssparkutils.fs.ls.
: abfss://STORAGEACCOUNT.dfs.core.windows.net has invalid authority.
Just for completenesss

Hi @Stephen Connell ,
Thank you for posting query in Microsoft Q&A Platform.
As I understand ask here pandas read excel and MS spark file system utilities are not working as expected. When you used abfss path then you see pandas is not working and for MS spark file system utilities also throwing errors. Please correct me if my understanding is incorrect.
I tried to reproduce the scenarios and in my case all working fine. Please check below details and screenshots.
I have used spark version 3.1 and i could see it has pandas version of 1.2.3 in it.
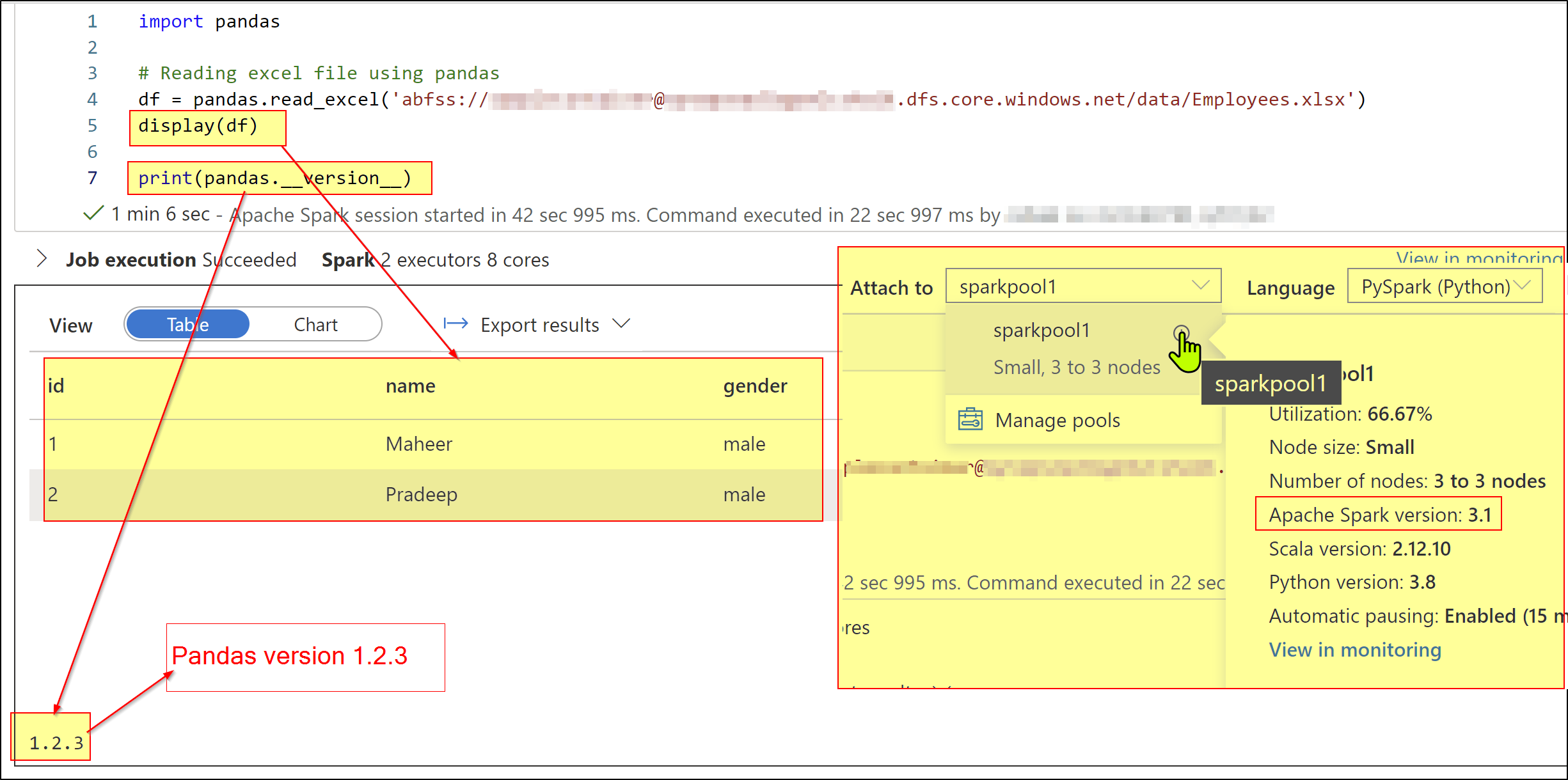
I also tried MS spark file system utilities and it also worked fine for me.

Below are the errors which you have mentioned. Please check my comments or thoughts on them below.
Error: FileNotFoundError: [Errno 2] No such file or directory: 'abfss://STORAGEACCOUNT@CONTAINER.dfs.core.windows.net/AssetManagement/Bronze/Raw/NOJV/FILE.xlsx'
From the error message it seems you are trying to access file, may be that file or directory not available. Kindly re-check once.
Error: Py4JJavaError: An error occurred while calling z:mssparkutils.fs.ls. : abfss://STORAGEACCOUNT.dfs.core.windows.net has invalid authority.
From above message it seems like we are missing permissions here. Could you please make sure synapse MSI and the AAD account which connected to Synapse workspace has Storage Blob data contributor role on the storage account.
Please note, below is the format of abfss path to use.
abfss://<containerName>@<storageAccount Name>.dfs.core.windows.net/<file path>
Hope this helps. Kindly let me know how it goes. If its not helpful kindly share details about your spark pool version so that I can try to use same and see if that helps to repro. Thank you.
Hi Shaik. You have understood correctly.
Since posting we have found that we can get the abfss to list the files using mssparkutils.fs.ls we cannot use https methods. Is this intended to be possible, you can see from my earlier examples the link I was using were folders not files.
folder = [file for file in mssparkutils.fs.ls('https://CONTAINER.dfs.core.windows.net/STORAGEACCOUNT/AssetManagement/Bronze/Raw/NOJV/')]
folder = [file for file in mssparkutils.fs.ls('https://CONTAINER.blob.core.windows.net/STORAGEACCOUNT/AssetManagement/Bronze/Raw/NOJV/')]
We still cannot get abfss to be used by the panda read_excel method although you correctly understand that this did work but suddenly stopped.
We currently have a method that loops the files using abfss then we need to take the file name which is appended to an https link and prepended with a SAS. It would obviously be more ideal to use one method rather than a mixture. These are the pool settings we are using.
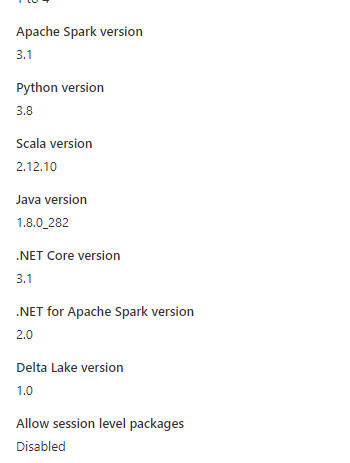
This is a quick run to illustrate on that pool

I wonder if there is a setting on the storage that may be misaligned given this error?
I note that this in not the error I was getting on Friday.
I have checked the pandas version which matched your spec of 1.2.3
Hi @Stephen Connell ,
mssparkutils will work with ADLS gen2 and Azure blob storage. If its ADFS gen2 then we should use abfss path only and https will not work here. Click here for more details about File system utilities form documentation.
Regarding second ask where abfss path still not working for pandas. Unfortunately still I am unable to repro the scenario. As mentioned earlier its working fine at my end. I have escalated this case internally to see if any help from there on this. I will keep you posted updates. Thank you.
Between, If its okay to create a new spark pool and try that, then please feel free to do same and share updates. Thank you.
Hi @Stephen Connell ,
Thanks for sharing requested details. Got update from internal team that
this is the issue where azure.core.credentials is unable to load and adding “azure-core==1.22.1" in the requirements.txt of the pool and restarting the session works out.
RCA for this issue is on-going internally. I will share updates on this thread once its done.
Hope this helps. Please let us know if any further queries.
------
Please consider hitting Accept Answer. Accepted answers helps community as well.
Requesting to consider taking survey/re-survey and share your feedback. That helps to get pulse. Thank you.
Hi @Stephen Connell ,
It seems some older build of fsspec that could be causing this issue.
Hope this helps. Please let us know if any further queries.
----------
Please consider hitting Accept Answer button. Accepted answers helps community as well.
Requesting to consider taking survey/re-survey and share your feedback. That helps to get pulse. Thank you.