Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERD%3C/text%3E%3C/svg%3E)
Hello, I am working on inserting data into a SQL Server table dbo.Employee when I use the below pyspark code run into error: org.apache.spark.sql.AnalysisException: Table or view not found: dbo.Employee;.
The table exists but not being able to insert data into it.
pyspark code:
df.write.format("jdbc").option("driver", "com.microsoft.sqlserver.jdbc.SQLServerDriver").option("url", "jdbc:sqlserver://dburl:1433;database=db;user=usr;password=pwd").insertInto("dbo.Employee")
Error stack:
Py4JJavaError Traceback (most recent call last)
/databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw)
62 try:
---> 63 return f(*a, **kw)
64 except py4j.protocol.Py4JJavaError as e:
/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name)
327 "An error occurred while calling {0}{1}{2}.\n".
--> 328 format(target_id, ".", name), value)
329 else:
Py4JJavaError: An error occurred while calling o319.insertInto.
: org.apache.spark.sql.AnalysisException: Table or view not found: dbo.Employee;
at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:47)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.org$apache$spark$sql$catalyst$analysis$Analyzer$ResolveRelations$$lookupTableFromCatalog(Analyzer.scala:749)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$$anonfun$apply$8.applyOrElse(Analyzer.scala:725)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$$anonfun$apply$8.applyOrElse(Analyzer.scala:723)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1$$anonfun$2.apply(AnalysisHelper.scala:90)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1$$anonfun$2.apply(AnalysisHelper.scala:90)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:76)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1.apply(AnalysisHelper.scala:89)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1.apply(AnalysisHelper.scala:86)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:198)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$class.resolveOperatorsUp(AnalysisHelper.scala:86)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsUp(LogicalPlan.scala:29)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.apply(Analyzer.scala:723)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.apply(Analyzer.scala:663)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:112)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:109)
at scala.collection.LinearSeqOptimized$class.foldLeft(LinearSeqOptimized.scala:124)
at scala.collection.immutable.List.foldLeft(List.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:109)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:101)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:101)
at org.apache.spark.sql.catalyst.analysis.Analyzer.org$apache$spark$sql$catalyst$analysis$Analyzer$$executeSameContext(Analyzer.scala:137)
at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:131)
at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:103)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$executeAndTrack$1.apply(RuleExecutor.scala:80)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$executeAndTrack$1.apply(RuleExecutor.scala:80)
at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:88)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.executeAndTrack(RuleExecutor.scala:79)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:115)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:114)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:205)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:114)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$analyzed$1.apply(QueryExecution.scala:85)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$analyzed$1.apply(QueryExecution.scala:86)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$executePhase$1.apply(QueryExecution.scala:229)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:835)
at org.apache.spark.sql.execution.QueryExecution.executePhase(QueryExecution.scala:228)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:83)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:83)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:75)
Thank you

Hello @Raj D ,
To know exact reason, I would request you to check out the complete stack trace and try to find root cause of the issue.
If you scroll down the error message you will find something called as "Caused by".
How to check complete stack trace and find caused by reason?
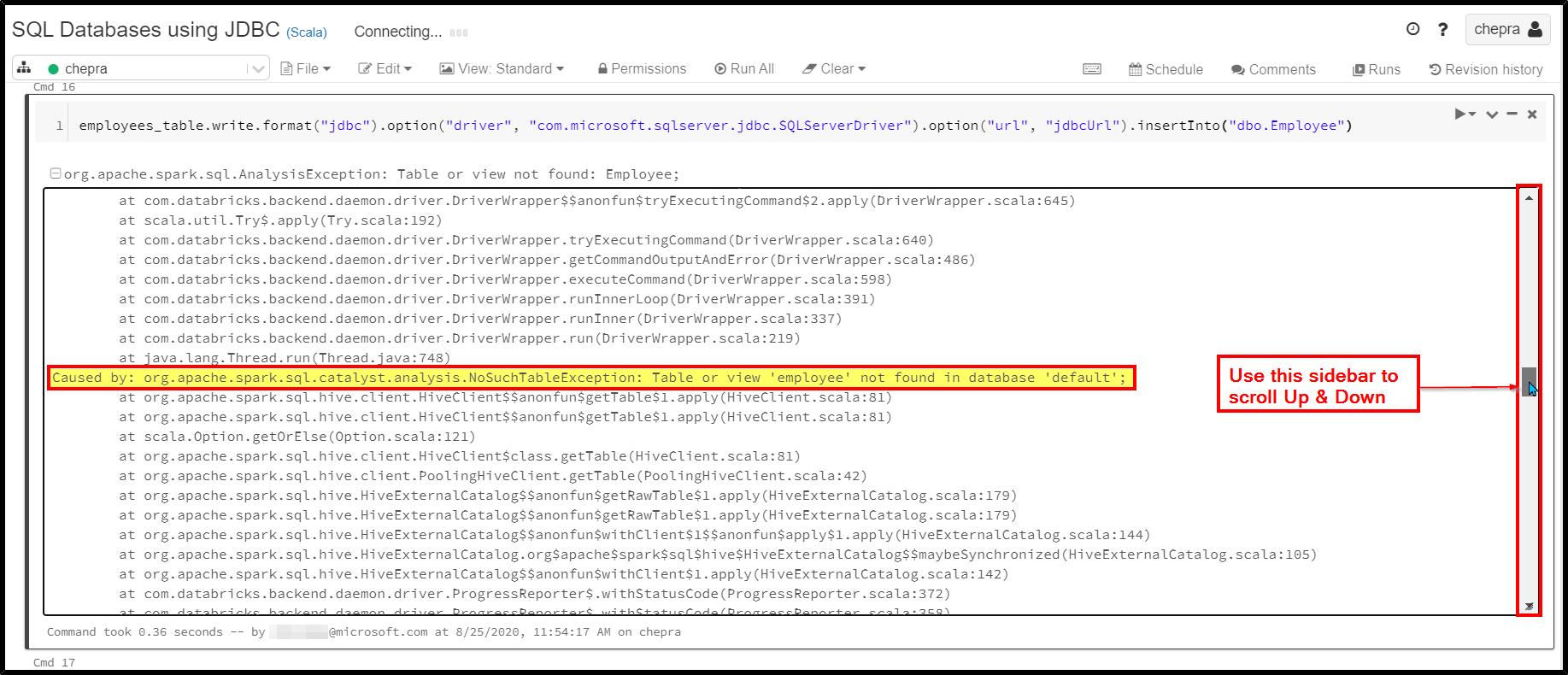
When you are using “.insertInto” with the dataframe. It will insert the data into underlying database which is databricks default database.
To successfully insert data into default database, make sure create a Table or view.
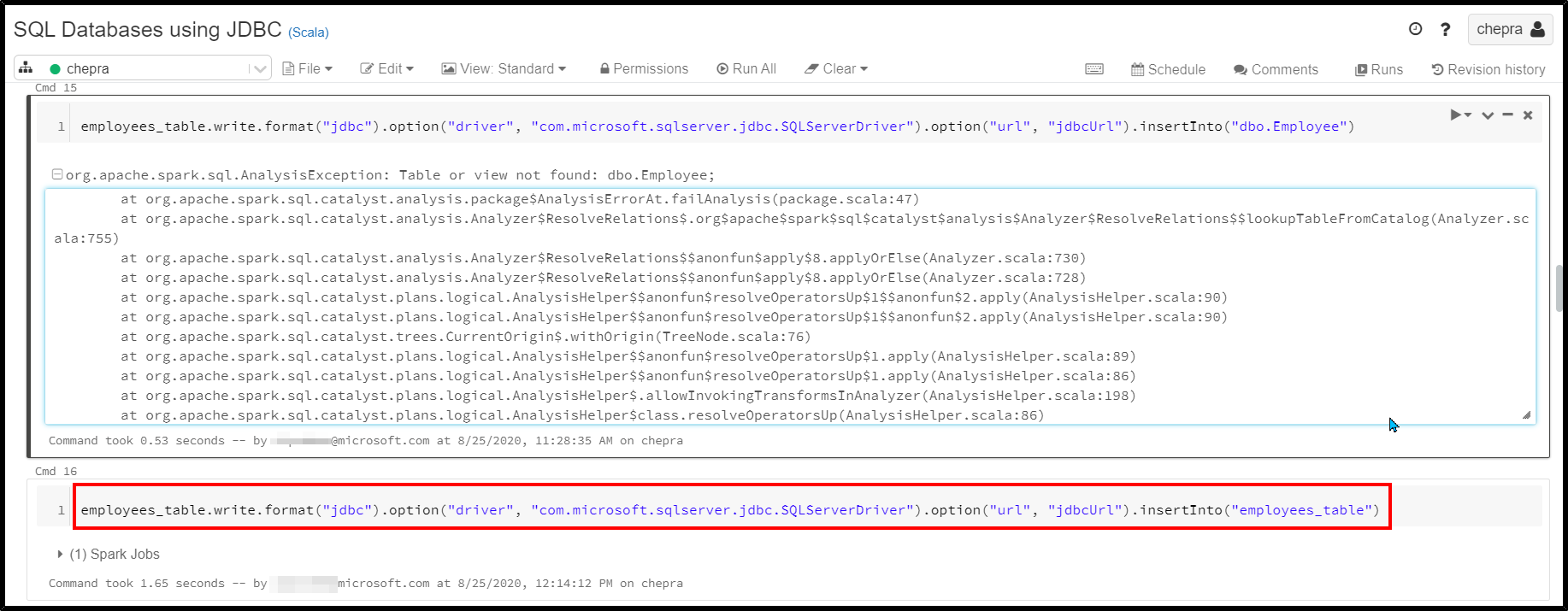
Checkout the dataframe written to default database.
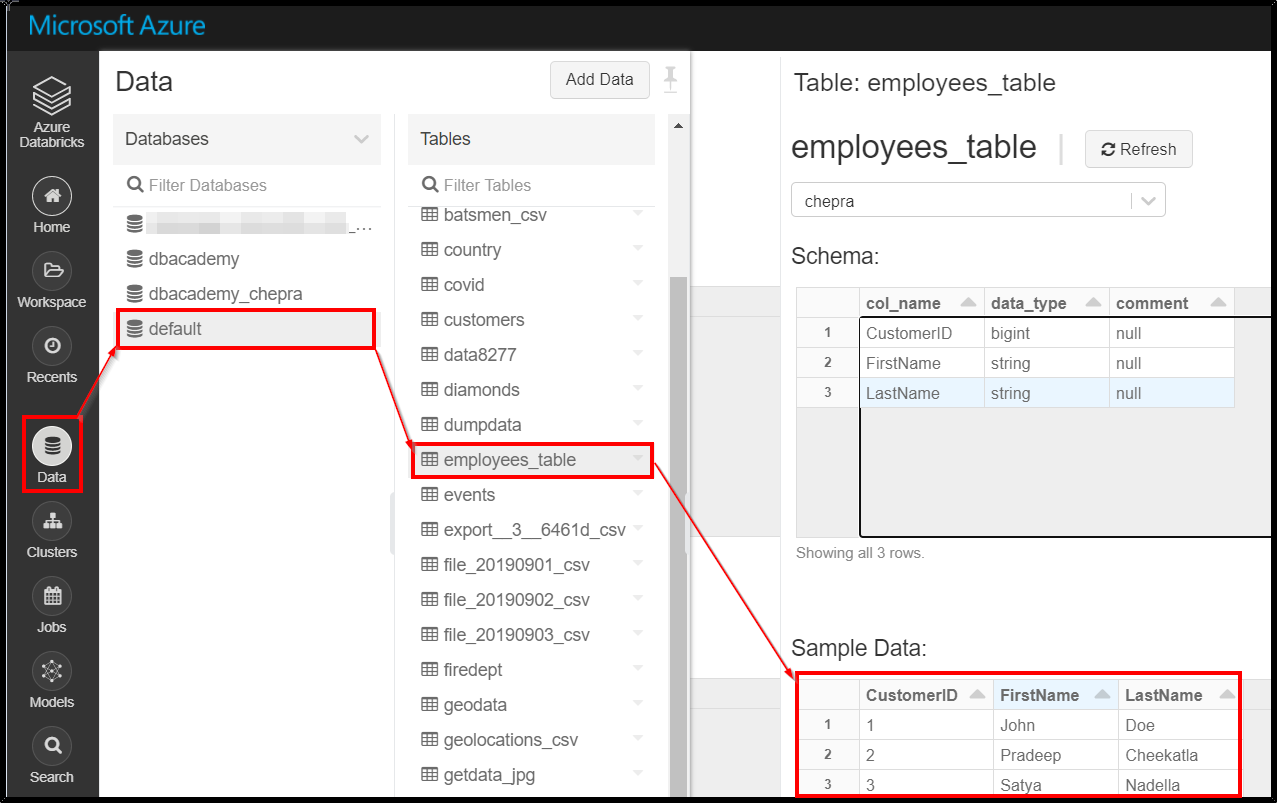
For more details, refer “Azure Databricks – Create a table.”
Here is an example on how to write data from a dataframe to Azure SQL Database.
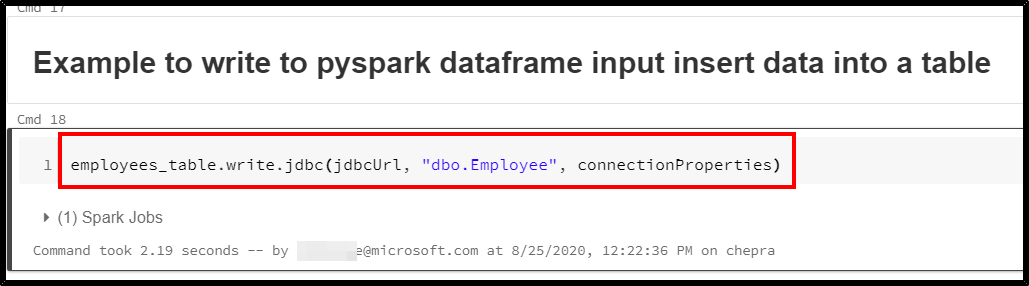
Checkout the dataframe written to Azure SQL database.
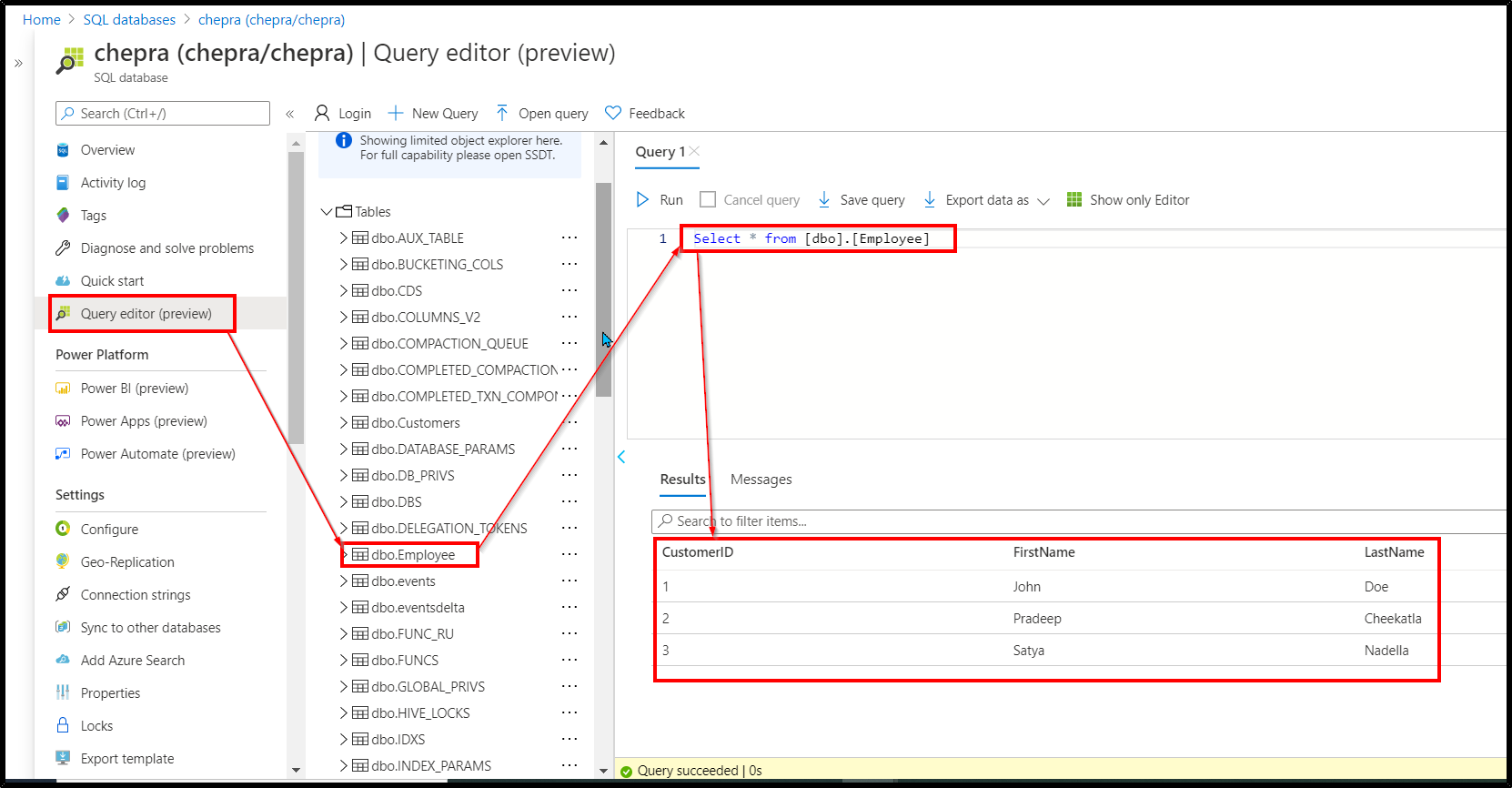
For more details, refer “Azure Databricks – Write to JDBC”.
Hope this helps. Do let us know if you any further queries.
----------------------------------------------------------------------------------------
Do click on "Accept Answer" and Upvote on the post that helps you, this can be beneficial to other community members.
Hello @Raj D ,
Just checking in to see if the above answer helped. If this answers your query, do click “Accept Answer” and Up-Vote for the same. And, if you have any further query do let us know.
Take care & stay safe!