Windows API - Win32
A core set of Windows application programming interfaces (APIs) for desktop and server applications. Previously known as Win32 API.
2,523 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPG%3C/text%3E%3C/svg%3E)
Hi!
I have a special case. Suppose you create files in the file system that uing a DBCS.
For reference, suppose you have:
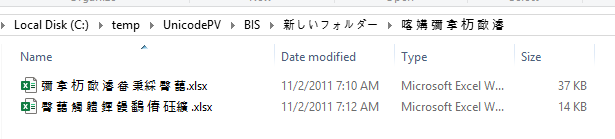
In text (in case you want to reproduce it) this is the path:
C:\temp\UnicodePV\BIS\新しいフォルダー\喀 媾 彌 拿 杤 歃 濬\彌 拿 杤 歃 濬 畚 秉綵 臀 藹.xlsx
See I mix several DBCS languages.
Doing a dir /x gives me this:
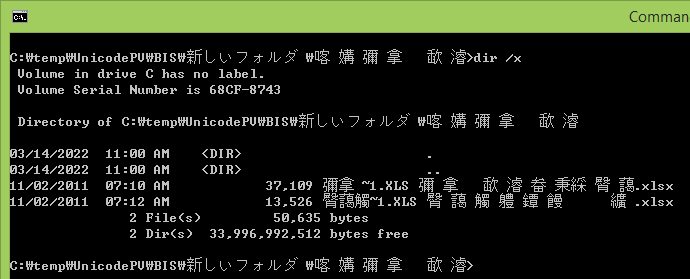
Notice that the short file name is also in DBCS. Remember that to have this short file name with Unicode characters you must use a DBCS in the "Language for non-Unicode programs" in the regional settings.
In this case now I have "Korean (korea)" in my "Language for non-Unicode programs".
Now I do a little program that receives a parameter that is a file path and it just calls GetShortPathNameW and then it calls WideCharToMultiByte and it displays it in the msgbox. In my case I have this:
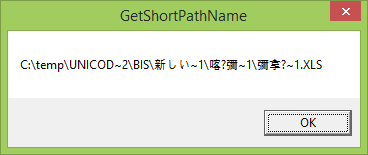
This is the part of the program I used:

Why does this API return a Unicode character that cannot be transformed into ANSI? I tried with FindFirstFileW but it's the same.
The 8.3 file name is supposed to work with non-Unicode programs and what I do is what is mentioned in many sites... the code is OK since if I copy the content of the command prompt and I paste it in Notepad and I save the Notepad .txt document using ANSI, when I open that .txt again I see the ? characters
Thanks
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EXY%3C/text%3E%3C/svg%3E)
According to Double-byte Character Sets,
Each DBCS code page supports different characters, but no page supports the full breadth of characters provided by Unicode. Each DBCS code page supports a different subset, differently encoded. Data converted from one DBCS code page to another is subject to corruption because the same data value on different code pages can encode a different character. Data converted from Unicode to DBCS is subject to data loss, because a given code page might not be able to represent every character used in that particular Unicode data.
Also Several Unicode and character set functions allow your applications to handle code pages. An application can use the GetCPInfo and GetCPInfoEx functions to obtain information about a code page. This information includes the default character used when a character in a converted string has no corresponding entry in the code page. And You'd better check what is CP_OEMCP(The current system OEM code page).
I understand this... but isn't the 8.3 short name designed for applications that need to access the file using ANSI functions instead of Unicode functions? In such case why doesn't Windows replace non-ASCII characters with numbers all the time?
I mean, suppose I have English as the language for non-Unicode programs.
I create ano12345678.txt. The short file name is ANO123~1.TXT. That's OK. Now I rename it to año12345678.txt. The "ñ" character is supported in this case... but it uses AO1234~1.TXT as the short path and this is just perfect since if I change the language for non-unicode programs to a character set not supporting "ñ" then the short path will still work.
Now, if I do the same in a computer having Chinese in "language for non-unicode programs " then when I specify chinese characters, the short path still contains chinese characters and when I switch to English in this computer the short file name will be "invalid" since it will contain ? when getting translated from Unicode to Ansi.
In my opinion it's a bug.
Why is It needed to convert the Unicode short name to ANSI? You can use GetShortPathNameA instead. If the Unicode short name can cooperate with other functions such as GetLongPathNameW, There is no problem. And you will not pass the converted ANSI short name to GetLongPathNameA, Will you?
I use an external library that only accepts ANSI characters and I must specify a valid file path. I cannot call GetShortPathNameA passing a "char *" that must hold a Unicode path!
GetShortPathNameA can get ANSI short name. Do you mean the external library which you use must accepts a Unicode path in ANSI format? If so, Does the string converted by WideCharToMultiByte work? And Does the short name return by GetShortPathNameA work?