Azure AI Document Intelligence
An Azure service that turns documents into usable data. Previously known as Azure Form Recognizer.
2,114 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ET%3C/text%3E%3C/svg%3E)
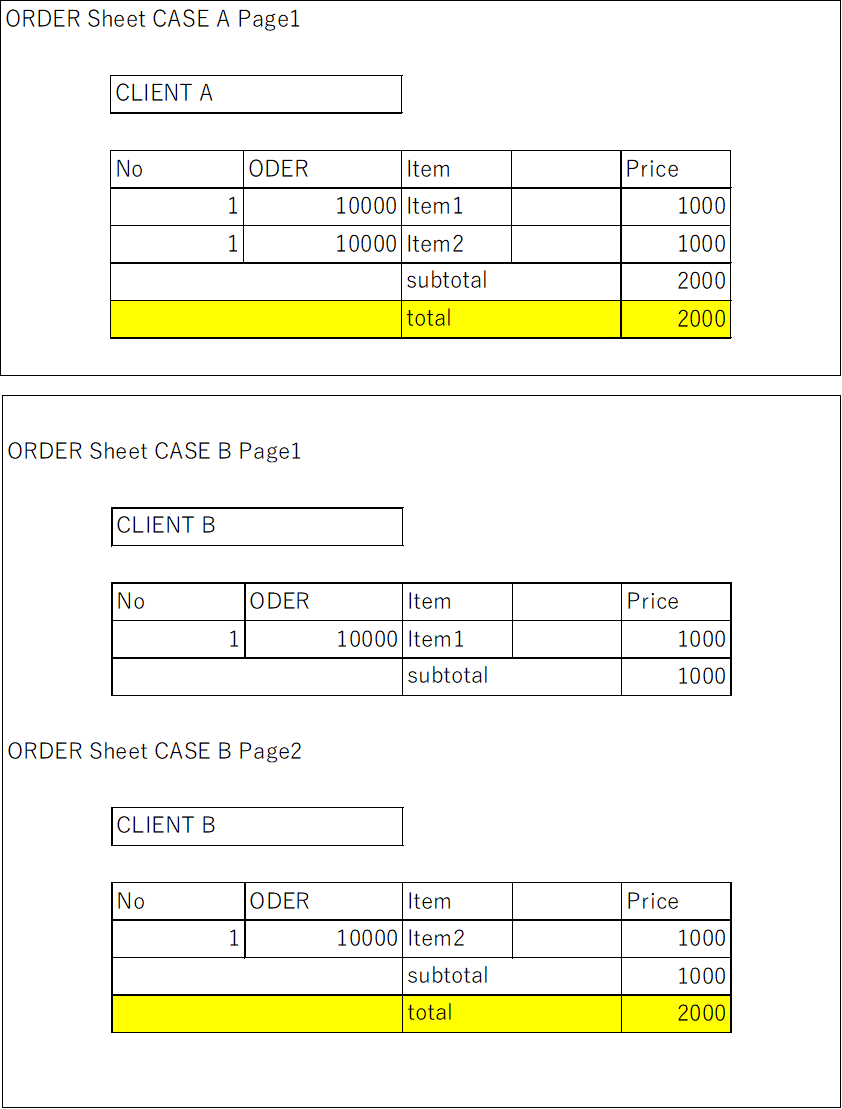
My team is conducting a PoC to extract text specified by Azure Form Recognizer from PDF files such as purchase orders, payment slips, etc.
During the PoC, we encountered an issue that the total amount in the last row of the table cannot be retrieved because the position is variable depending on the number of rows, as shown in the attachment. (CASE A)
In some cases, the total amount is displayed after the second page. (CASE B)
Our client has asked us to explain the accuracy of the OCR when deploying Azure Form Recognizer to the production environment.
How many PDF files should we train Azure Form Recognizer on in order to get enough accuracy to deploy it in a production environment?
Also, any best practices on how to train the Azure Form Recognizer model?

@test29998411 I believe you are using a custom model to extract the table with analyze API?
If you have trained a model with a certain layout of text then the model extracts text and assigns labels similarly. If the table extends to a different page then it would not be able to automatically stich the table data in the current scenario. However if you train the model with this scenario you can actually post process the results based on other data in the table like column data.
Even with the layout model API where tables can be extracted without any prior training you need to use the page parameter to post process the result.
With respect to FR limits and characteristics you can refer this page which is mostly based on the accepted image quality for OCR performance.
We are extracting tables with the Analyze API using a custom model trained on a label called total.
Is the following interpretation correct?
tables and repeat the process of getting the rowIndex that satisfies the condition text=total for each page of the PDF, can I get the value of total? json tables instead of labeled fields?tables, but not when retrieving text from fields?
@test29998411 the first approach might work as long as the fields or column names are fixed.
The second approach of using labels is better suited if your tables have fixed number of rows and follow a pattern.
The third approach of splitting the file can be used for large files. Splitting a file based on tables or labels might not improve the extraction.
Training is done with a minimum of 5 documents with the form having all the required fields or values you expect to extract. If you want to add more document formats you can always train a new model and create a composite model using all your models to extract different document formats.
If an answer is helpful, please click on  or upvote
or upvote  which might help other community members reading this thread.
which might help other community members reading this thread.
Thanks for answering.
The number of columns in the table is fixed, but the number of rows is variable and the number of pages is undecided, so it seems difficult to extract by learning by labels, so I will implement the No.1 approach.