Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,624 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EM%3C/text%3E%3C/svg%3E)
I am trying to set up the copy data activity in data factory to copy many tables from Sybase to Postgres. I have set up a lookup of the tables on the source and dynamically pass them to the copy function. My issue is the column names of the source tables are uppercase and the column name of the sink is lowercase causing the pipeline to fail. How do I dynamically map the column names from uppercase to lowercase?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMW%3C/text%3E%3C/svg%3E)
Hi Matthew,
I have figured out a way to do this without monotonously creating a sacrifice copy activity that you generate the mappings for and store in a separate table. It's a VERY hacky work-around, and I do hope Microsoft implements an "ignore case sensitivity" option in the future for migration cases like this, but in the meantime, here's how it works:
@Pratik Somaiya gave the idea that we need to pass the json for the translator into the copy activity's mapping tab as dynamic content. We just need to generate that content ourselves.
The first steps are exactly the same as you've already done, we'll create a pipeline with a Lookup activity to get a list of the names of all tables you have in your Database. Then, we'll feed that into a forEach activity.
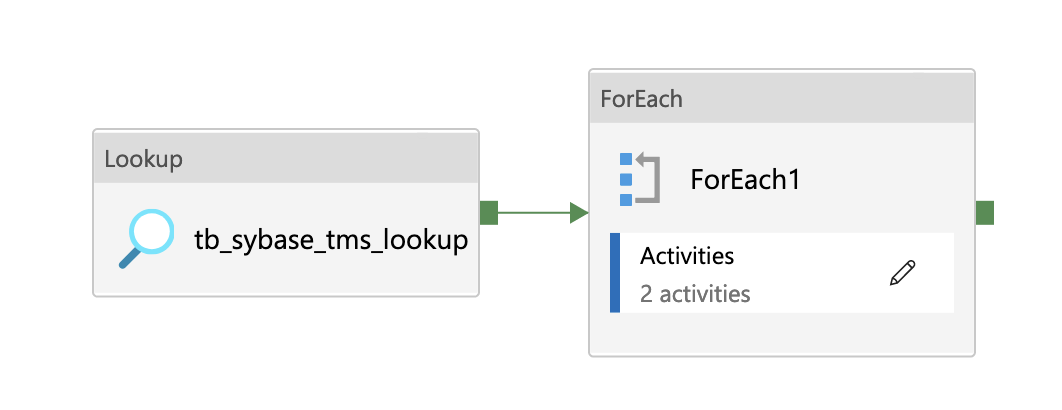
Inside that ForEach loop, we'll be iterating across all the tables you have. Now, we need to get a list of all the columns and generate the "transformer" source/sink strings that we'll need to pass into the copy activity. First, we have another lookup activity that takes the "item" of the for each loop as dynamic content to get the columns. I called the results column for this "source". I also went ahead and created a "sink" column in our results list and used Sybase's toLower function on the same query since your only transformation is makingthe column names lowercase. For Sybase, it looks something like this:
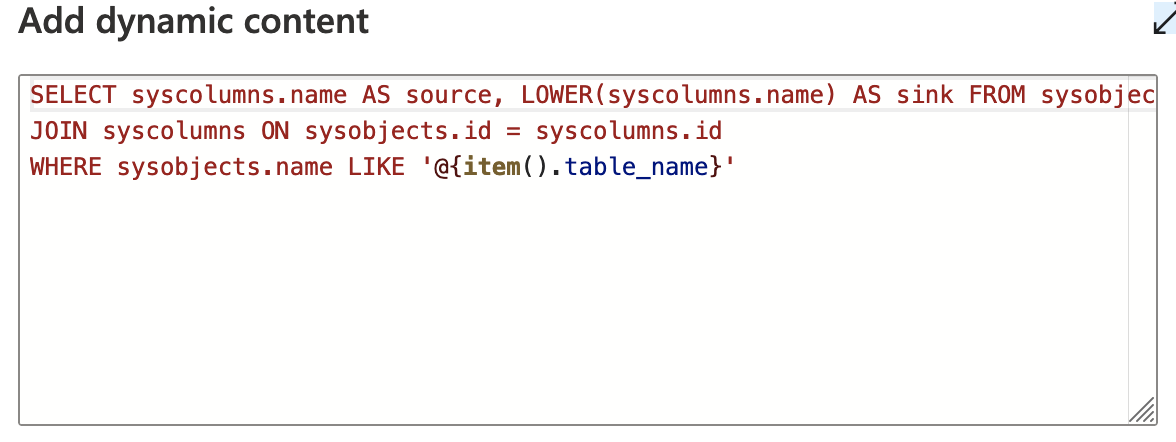
Once you run that query, we get our list of columns. This is where we should iterate through the list of columns and create the "source/sink" format for all of them, but ADF has a rule where you can't put a forEach activity inside of another forEach activity.
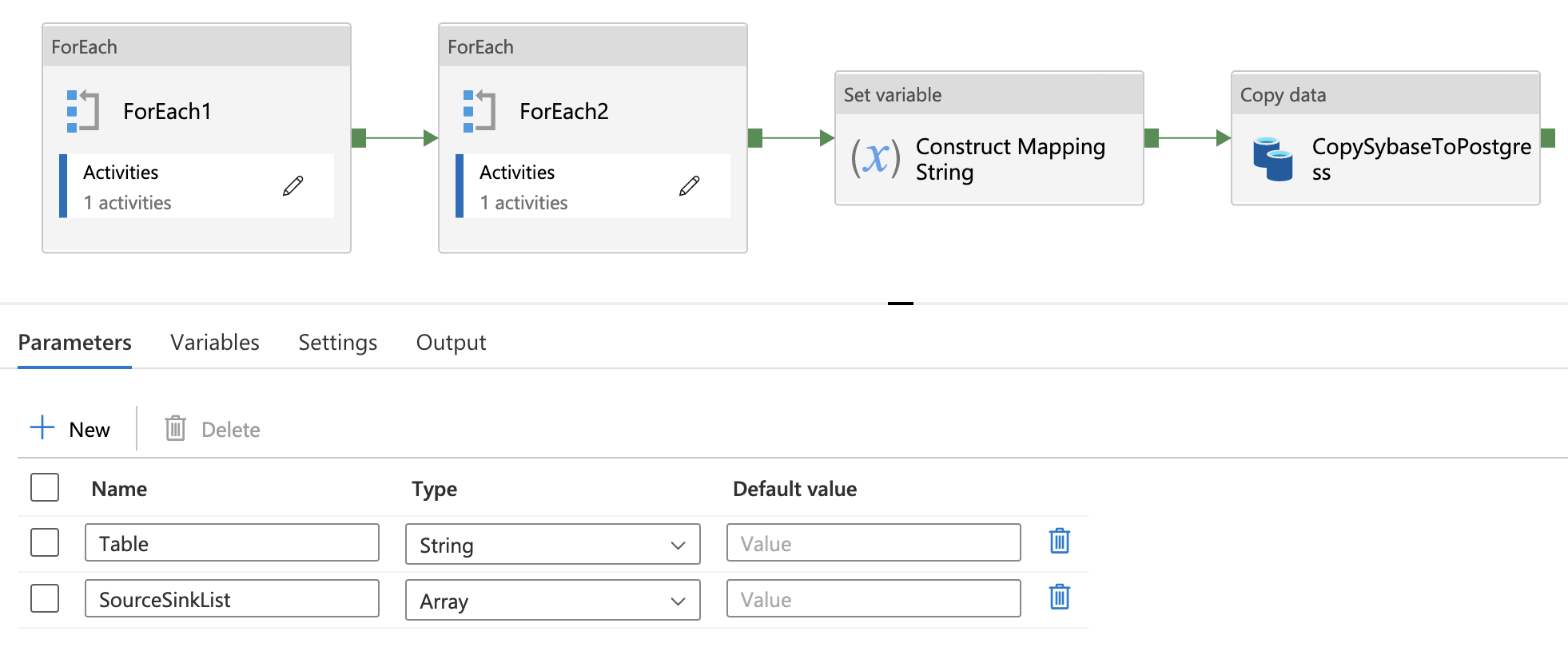
In order to get around this, we have to use another pipeline and pass the data we have (the table name and result list of columns) to it as parameters. To do this, we'll create another pipeline and create 2 parameters we can pass values to:
Then, use an "Execute Pipeline" activity in our original pipeline's forEach activity to call the pipeline and pass our data
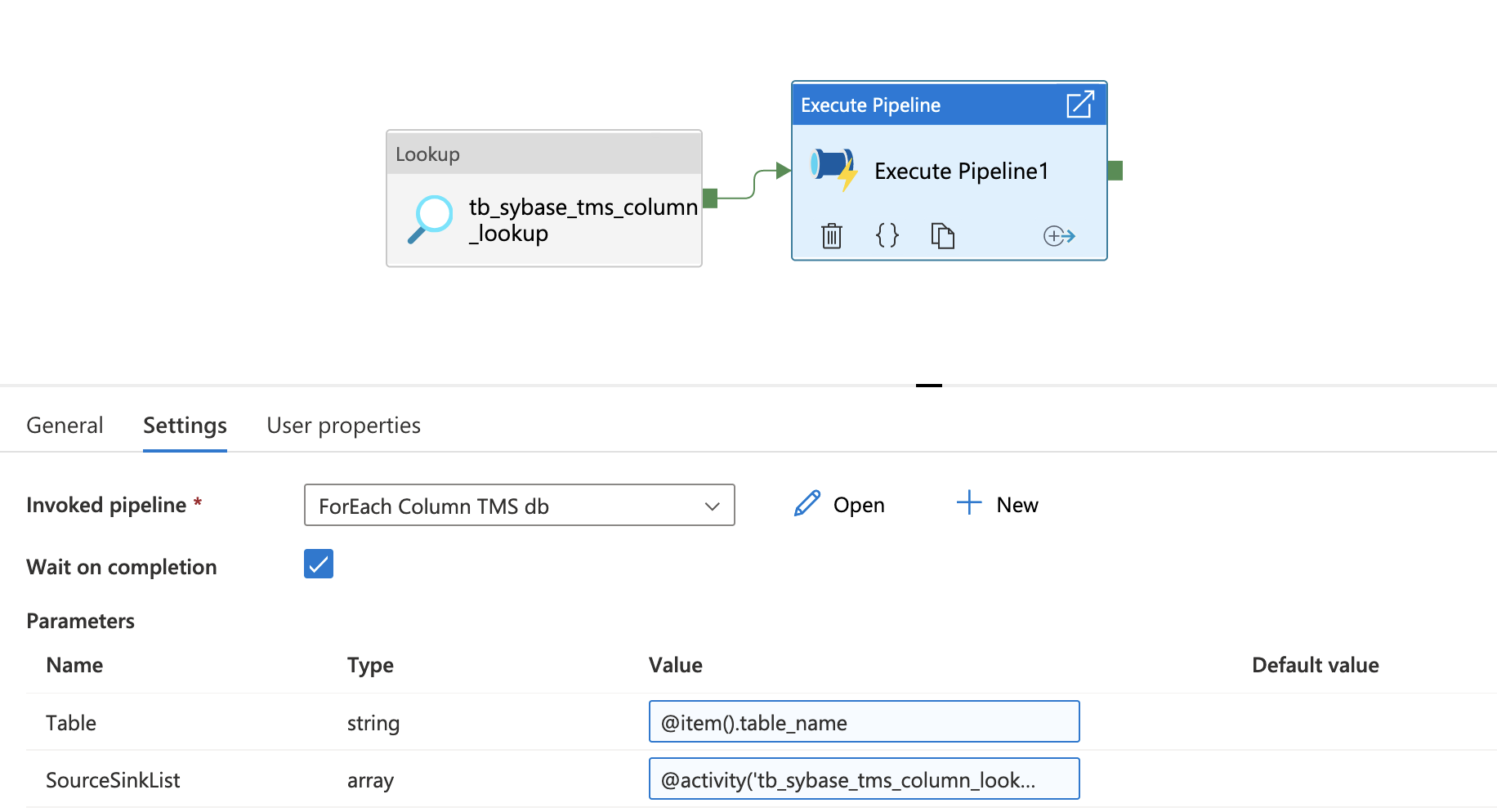
Now, we can get started on creating the transformer content strings. As you'll notice in the above picture of the second pipeline, there are a few for-each loops and variables we've created before our copy activity. ADF makes it possible, but not straightforward, to build a string. To do this, we will need to create Variables in the pipeline that we can store our strings in.

These 3 variables will help us with our 4 stage process:
These steps are all necessary due to the nature of how variables work. For some reason, the Array Variables store all elements as Strings, or that's how my implementation has found it.
So, the first forEach activity, we format the elements with an "Append Variable" activity and Append the following to the "MappingStrings" variable we created:
{"source":{"name":"@{item().source}"},"sink":{"name":"@{item().sink}"}}
Then we move to the second forEach activity where we have another Append Variable activity that appends the JSON-ified version of the string to to the "MappingArray" variable:
@json(item())
We then move on to the Set Variable activity, where we set the "FinalString" variable to include the Header for the translator JSON and the "MappingArray" variable with the following dynamic content:
{
"type":"TabularTranslator",
"mappings": @{variables('MappingArray')}
}
And then, the final step: the copy activity. This is where we finally use the Table parameter as well. Our Source tab, we need the Sybase DB dataset to take a table name parameter and pass in the following dynamic content:
@pipeline().parameters.Table
On the sink tab, we will need the Postgres DB dataset to also take a table name. Here, we can use dynamic content and the toLower function to get around the case-sensitivity mapping issue.
@toLower(pipeline().parameters.Table)
Then finally, on the mapping tab, you'll need to take our "FinalString", clean up any remaining newline characters or extra back-slashes from the string formatting, and then convert it to a JSON object with the following dynamic content:
@json(replace(variables('FinalString'),'\',''))
And that's all she wrote
There are deffinitely tons of ways this could break and isn't very scalable, but for your use case of converting uppercase column and table names to lowercase to get around case sensitivity, this should work.
Some notes:

Hello @Matthew
You can save the JSON mapping in your config / metadata table and return it from Lookup
For this, first you need to create a dummy copy activity and add source and destination to it, then in the mapping window, click on Import Schemas, it will map the column names, then you need to open the JSON code and copy the mapping
The JSON code for mapping should be something like this:
{
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": {
"name": "COLUMN1",
"type": "String"
},
"sink": {
"name": "column1",
"type": "String"
}
},
{
"source": {
"name": "COLUMN2",
"type": "String"
},
"sink": {
"name": "column2",
"type": "String"
}
}
]
}
}
You will have to save this JSON mapping in the config table as a new column
Then, in your main pipeline you need to do the following:
1) Update Lookup query to fetch the JSON Mapping from lookup / config table
2) In the Copy Activity, under Mappings tab, click on Add Dynamic Content and add following:
[@](/users/na/?userId=b1b84c87-4001-0003-0000-000000000000)(item().JSON_MAPPING) --where JSON_MAPPING is the column name in config table to store the mapping
3) Publish and execute the pipeline
This way you can maintain the mapping even if column names are totally different between source and sink, this also makes your pipeline dynamic
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
Hi @Pratik Somaiya , how can save this JSON mapping in the config table as a new column i am not understanding this give me example
The JSON mapping can be stored in the table by first adding a field in config table named JSON_MAPPING having datatype as varchar(max) then updating the table with the JSON mapping for each record as a string
Then simply this can be used in the lookup activity
I am already using it and its helping me a lot to execute multiple tables in same pipeline, because in my case too source and sink column names are different
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESS%3C/text%3E%3C/svg%3E)
When I'm copying the code @json (item().JSON_MAPPING) in the copy activity of dymanic content. getting issue as below:
Expression of type: 'String' does not match the field: 'mappingV2'.
Expected type is 'Object'.
Kindly help me on the same