Azure Machine Learning
An Azure machine learning service for building and deploying models.
3,334 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ET%3C/text%3E%3C/svg%3E)
Hello,
I have built an Azure ML pipeline which will be called from a Data Factory pipeline at a specified interval.
The ML pipeline contains PythonScriptSteps which take various datasets as an input. All datasets are registered and versioned in the same Azure ML workspace.
The Data Factory pipeline regularly updates the datasets to a new version and then run the registered ML pipeline. The expected behavior is that the ML pipeline will read the latest version of each dataset every time it is run by Data Factory.
Even though I have set the parameter 'allow_reuse' of my PythonScriptStep objects to 'True', I expect the steps to be executed when the input datasets have been updated to a new version. But the problem is they are not executed. In the Experiments details, I can see that each step has its flag 'Reuse' set to 'Yes' and the execution duration is 0 second.
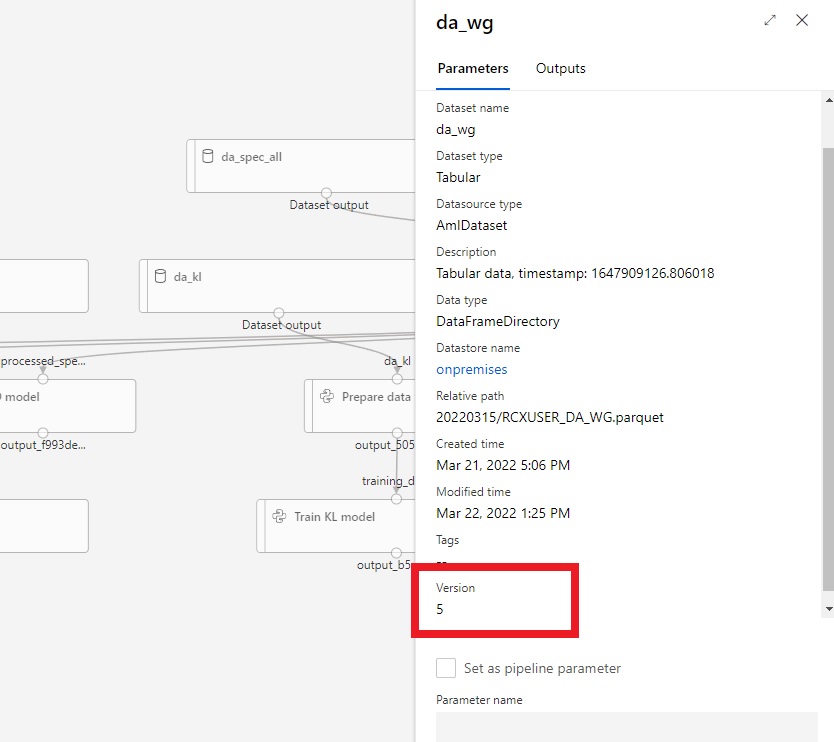
When I look at the registered pipeline in 'Azure ML Studio -> Pipelines -> Pipeline endpoints' and I click on the input datasets, I can see that they have a parameter 'version' with an old version of the dataset 'hardcoded' in it (see picture below). It seems like once an ML pipeline has been published, it will always use the same dataset version at every run, even though the dataset have been updated in between. Is this the normal behavior?
Here is a simplified version of my pipeline code.
# Get a reference to the workspace
ws = Workspace.from_config()
# Get the registered dataset
dataset1 = Dataset.get_by_name(ws, 'dataset1')
# Pipeline's first step
script1 = PythonScriptStep(
name="Script 1",
script_name="script.py",
source_directory="./",
inputs=[dataset1.as_named_input('dataset1')], # Passes the dataset path to the script
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
# Build the pipeline
pipeline = Pipeline(workspace=ws, steps=[[script1]])
from azureml.core import Experiment
# Submit the pipeline to be run
pipeline_run = Experiment(ws, 'experiment').submit(pipeline)
pipeline_run.wait_for_completion()
published_pipeline = pipeline.publish(name = "pipeline1")

@ThierryL-3166 Dataset.get_by_name() uses the latest version by default and if the dataset version is registered or updated by the datafactory pipeline the latest version should be picked up.
What is the version or versions that is displayed for dataset1 when you lookup the concerned dataset from the dataset tab on ml.azure.com?
I can confirm that for a pipeline endpoint if you have setup the pipeline to use the latest version of dataset it should display the latest version. Screenshot below:
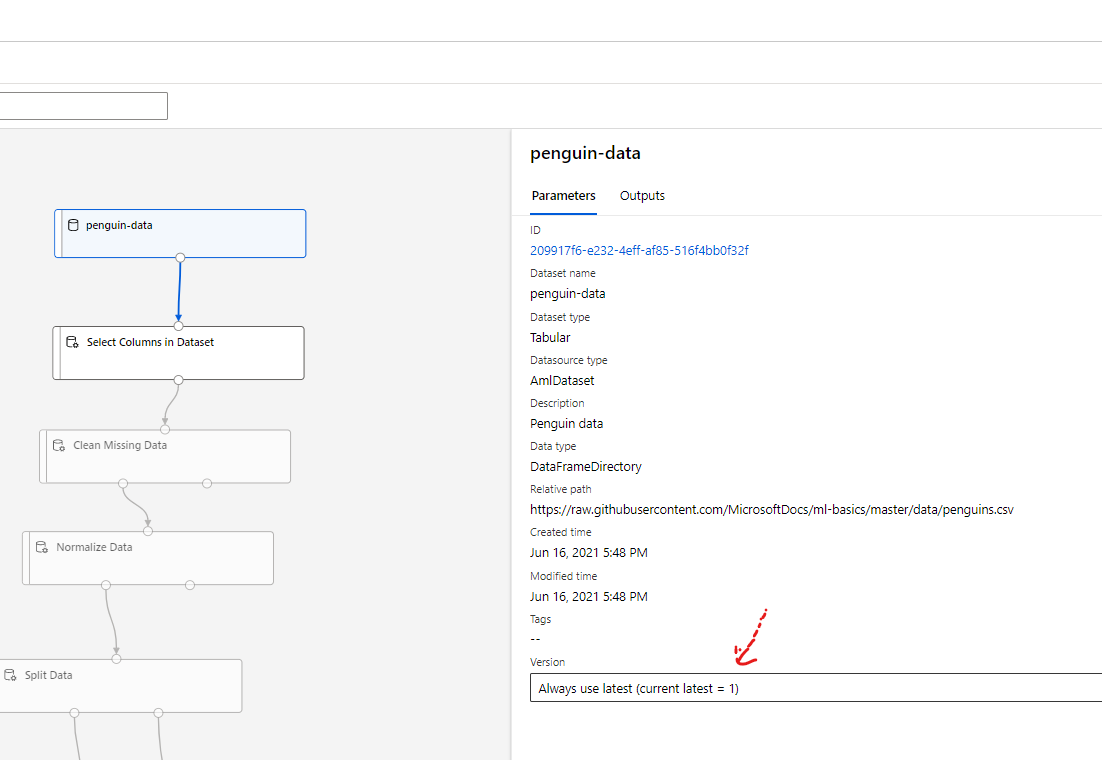
The version displayed in the Dataset tab is 10, which is the latest version.
I will try to create the simplest pipeline possible and post the code here if it still doesn't work.
@romungi-MSFT I have tried with a simple pipeline below but still the dataset version is hardcoded in the pipeline parameters.
@ThierryL-3166 The pipeline I have is created from the UI ml.azure.com and the one you created is using SDK and it might be picking up the version by number instead of latest.
I tried an export of my pipeline after adding a new version and it seems to export with the number instead of latest. For example, the export snippet of my UI pipeline.
penguin_data = Dataset.get_by_name(workspace, name='penguin-data', version='2')
I think this might be the reason that the published pipeline is picking up the previous version as it is created from SDK. The UI shows the latest though.
I am checking internally with product team to understand if this is the expected behavior. Thanks!!
Thanks.
@ThierryL-3166 After checking with required developers I can confirm that the behavior you are seeing is expected. But, to ensure you pass the latest version of dataset to pipeline you can introduce a pipeline parameter and run the published pipeline with dataset version that is latest i.e by using Dataset.get_by_name() as the parameter. This ensures that a version change in dataset does not need a pipeline to be re-published. I hope this helps!!
@romungi-MSFT Are you suggesting me to use 'Dataset.get_by_name()' in the parameters of Data Factory 'Machine Learning Execute Pipeline' activity? I'm afraid such function is not available as a dynamic content there.
@ThierryL-3166 No, I meant using this with the Azure ML pipeline.
1) It's odd that when you create a pipeline with the UI you can configure it to pick up the latest version of a dataset at each run, but when you create the pipeline from the SDK this doesn't work the same way.
2) I tried using a PipelineParameter but it doesn't work. In the pipeline definition script I wrote:
dataset = PipelineParameter(name="dataset", default_value=Dataset.get_by_name(ws, 'dataset'))
step1 = PythonScriptStep(
[...]
arguments = [
"--dataset", dataset,
],
)
And in the script:
parser.add_argument("--dataset", type=TabularDataset, dest="dataset")
dataset= args.dataset
dataset_df = dataset.to_pandas_dataframe()
The pipeline fails with the following error:
{'code': data-capability.DatasetMountSession:ctb_compound.UserErrorException, 'message': , 'target': , 'category': UserError, 'error_details': [{'key': NonCompliantReason, 'value': UserErrorException:
Message: Dataset xxx is not a FileDataset and cannot be used as input for mount/download.
3) The only solution I found and which seems to work is to add the following code into every PythonScriptStep of my pipeline when I need to access a dataset (this forces me to duplicate a lot of code, and these datasets are not displayed graphically when I visualize the pipeline graph in ML Studio):
ws = run_context.experiment.workspace
dataset = Dataset.get_by_name(workspace=ws, name='dataset')
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EDL%3C/text%3E%3C/svg%3E)
Hi @ThierryL did you ever get a solution to this? I have the same issues.
@romungi-MSFT What is the best way to ensure that a Pipeline created with SDKv1 runs with the latest version of a registered dataset by default? Is it to simply just load from the dataset from within a pipeline stage, instead of treating it as an input?
As far as I can tell, using Dataset.get_by*_*name(), ensures that the Pipeline will be generated to use the latest version of the dataset, but only at the time of the pipeline being generated, not for future pipeline runs where the registered dataset may have been updated.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAS%3C/text%3E%3C/svg%3E)
Hi @David Lazaridis
The pipeline needs to be submitted before publishing. When you submit it, you can specify regenerate_outputs = True
from azureml.core import Experiment
test_pipeline_run1 = Experiment(workspace, 'ExperimentName').submit(test_pipeline, regenerate_outputs=True )
test_pipeline_run1.wait_for_completion()
After this, the pipeline should be published.
regenerateoutputs=True will make sure that output is generated every time the pipeline is run. Allow_reuse = False flag in the python script steps will make sure that new version of dataset is used.
These 2 factors together have made my pipelines work on new dataset every time. I hope it helps.
Hello @David Lazaridis
I modified my code to load the dataset from within the pipeline stage, instead of treating it as an input.
I have not tried the solution posted earlier by @annu.shokeen@team.telstra.com (regenerate_outputs=True and allow_reuse = False).
I created and published a simple pipeline with the code below:
from azureml.core import Workspace, Dataset
from azureml.core.runconfig import RunConfiguration
from azureml.pipeline.steps import PythonScriptStep
from azureml.core.compute import ComputeTarget
from azureml.pipeline.core import Pipeline
ws = Workspace.from_config()
compute_target = ComputeTarget(workspace=ws, name='DS3-v2-standard-cpu')
compute_target.wait_for_completion(show_output=True)
aml_run_config = RunConfiguration()
aml_run_config.target = compute_target
da_rolled = Dataset.get_by_name(ws, 'da_rolled', version = 'latest')
step1 = PythonScriptStep(
name="Step1",
script_name="test.py",
source_directory="./",
inputs=[da_rolled.as_named_input('da_rolled')],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=False
)
pipeline = Pipeline(workspace=ws, steps=[[step1]])
published_pipeline = pipeline.publish(name = "TestPipeline")
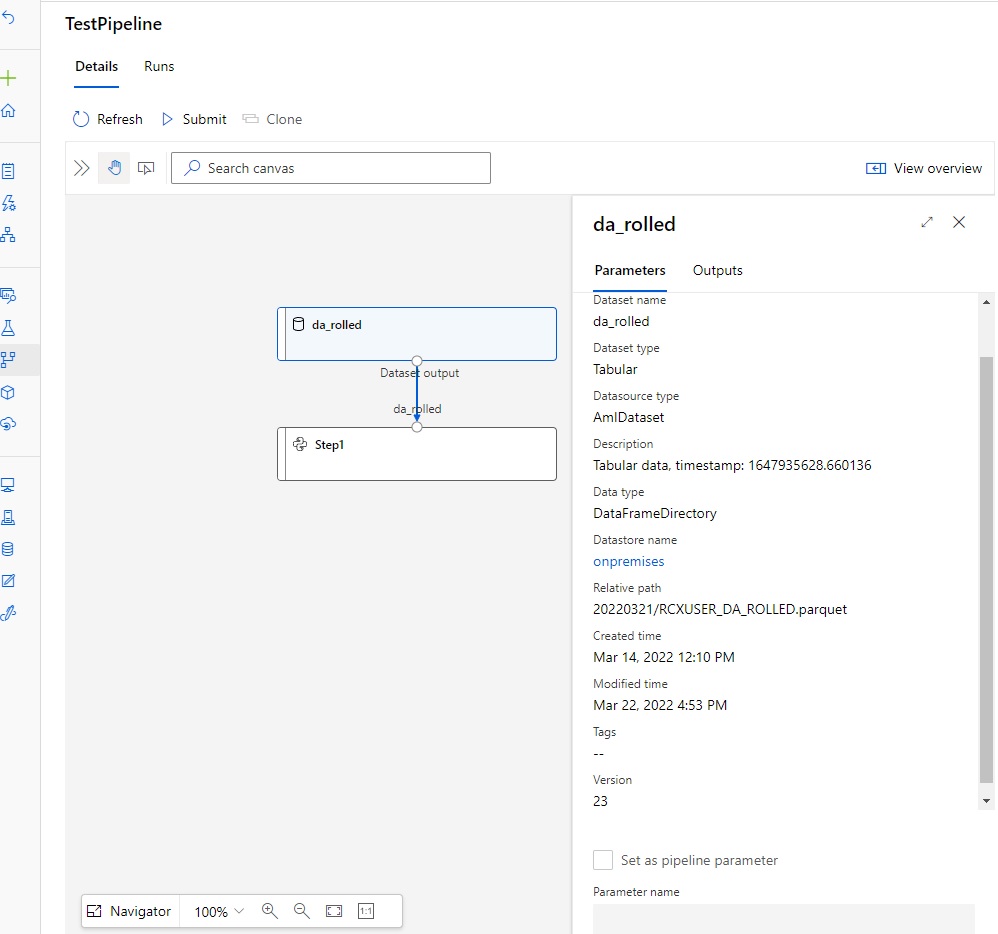
You can see in the image below that the version of the dataset (23, which is the latest version at the time the pipeline is published) is hardcoded in the pipeline definition.
And this is my dataset.
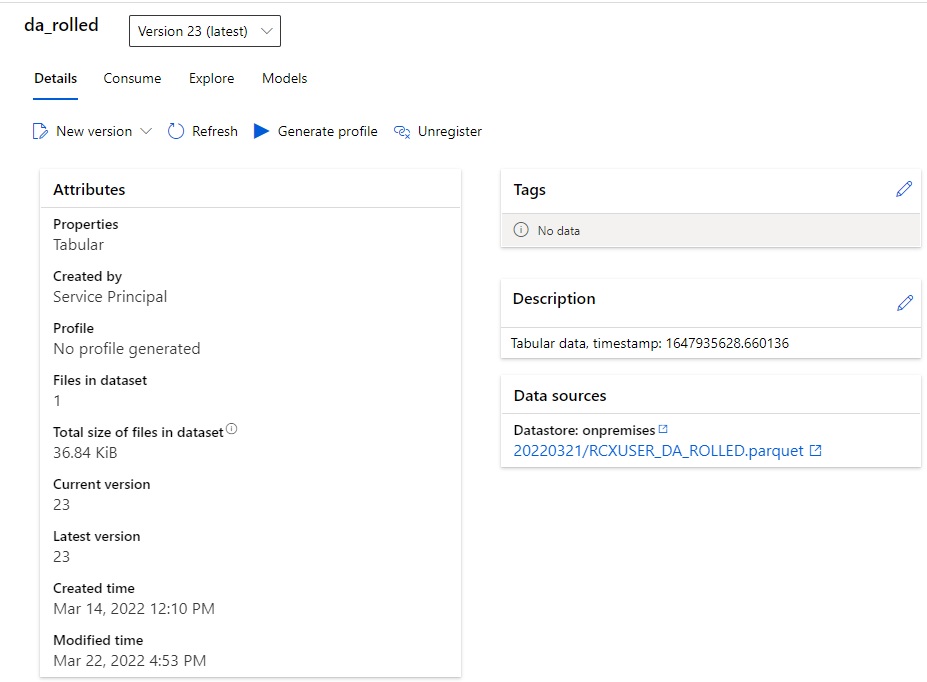
Now if I run my Data Factory pipeline to update the dataset to a new version (which will make it version 24), the version in the pipeline definition will still be 23.
It seems like I need to republish the pipeline every time the dataset is updated.
Hi,
I was having this same issue. allow_reuse falg is not checking the underlying data but only the dataset's definition. Following is the explanation provided by Microsoft:
"Indicates whether the step should reuse previous results when re-run with the same
settings. Reuse is enabled by default. If the step contents (scripts/dependencies) as well as inputs and parameters remain unchanged, the output from the previous run of this step is reused. When reusing the step, instead of submitting the job to compute, the results from the previous run are immediately made available to any subsequent steps. If you use Azure Machine Learning datasets as inputs, reuse is determined by whether the dataset's definition has changed, not by whether the underlying data has changed"
I resolved this issue by adding regenerate_outputs=True while submitting the pipeline like following:
pipeline_run = Experiment(workspace, 'exp_name').submit(pipeline1, regenerate_outputs=True)
It was working fine until last week and everytime pipeline was generating outputs which I intend to but this week it started to give me another weird problem. When I am submitting the pipeline first time, I see the first step is "Not Started" saying that rerun will be used (which it should not) and weirdly the rerun id of that step and current runId is same. So finally nothing happens and pipeline stays in running stage for like 12 hrs until I cancel it.
delete the comment
Hi @David Lazaridis
The pipeline needs to be submitted before publishing. When you submit it, you can specify regenerate_outputs = True
from azureml.core import Experiment
test_pipeline_run1 = Experiment(workspace, 'ExperimentName').submit(test_pipeline, regenerate_outputs=True )
test_pipeline_run1.wait_for_completion()
After this, the pipeline should be published.
regenerateoutputs=True will make sure that output is generated every time the pipeline is run. Allow_reuse = False flag in the python script steps will make sure that new version of dataset is used.
These 2 factors together have made my pipelines work on new dataset every time. I hope it helps.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKG%3C/text%3E%3C/svg%3E)
Hi, @annu.shokeen@team.telstra.com
When you publish this pipeline dataset version is still hardcoded.
If you run from code yes, version is updateed but I think idea of publishing pipeline is that developers preparing some pipeline and then when data changes, they don't need to rerun it from code but just click submit and steps which depends on new data will run.
It's important especially when pipeline is prepared for non-technical users who are working on data and results, not on python codes.
In the published pipeline, I have a python script step which fetches data from the database and the data assets are created by the pipeline itself. Its basically running SQL queries directly. So every time the published pipeline is run, the code fetches the new data based on those SQL queries since regenerate_outputs is set to true.
I haven't tried publishing a pipeline which uses the data assets created manually.
Thanks