SQL Server
A family of Microsoft relational database management and analysis systems for e-commerce, line-of-business, and data warehousing solutions.
13,362 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESD%3C/text%3E%3C/svg%3E)
In SQL 2017, we have a table defined with a column named CheckNo that is a varchar(100) We have a FTI on this column but are getting inconsistent or at times NO results and I'm trying to determine why. We have rebuilt/re-populated the FTI and still get bad results. I have tried using CONTATINS or FREETEXT with no differing results. Due to the amount of data in this table we really would not want to switch back to a LIKE compare due to processing time, but that seems to be the only way we get the results we need. An examination of the Crawl log yields no input or failures.
Examples follow:
--Example 1. Data exists with this string combo, not complete search term, but FTI returns no rows:
select * from TableName where CONTAINS(CheckNo ,'"51A33"' ) -- 0 rows returned
select * from TableName where FREETEXT(CheckNo , '51A33' ) -- 0 rows returned
select * from TableName where CheckNo like '%51A33%' -- 10 rows returned
--Example 2. Data with partial match returns 2 different ways via FTI with only the like compare returning all data
select * from TableName where CONTAINS(CheckNo , '"da80186140"' ) --10 rows returned
select * from TableName where CONTAINS(CheckNo , '"80186140"' ) --1 rows returned
select * from TableName where CheckNo like '%80186140%' -- 11 rows returned
--Example 3. Sheer difference in return set data volume
select * from TableName where CONTAINS(CheckNo , '"37265"' ) -- 142 rows returned
select * from TableName where CheckNo like '%37265%' -- 589 rows returned
Our team has done a moderate amount of searching for issues with this topic but haven't turned up much. Thought I would ask here to see if we could get some traction. Thanks!
EDIT: The format of my actual queries is correct. The forum posting stripped the * (or doesn't display them)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ETP%3C/text%3E%3C/svg%3E)
You can fix the query code by using the "Code" button at the top of the screen when posting code.

If the Full Text Indexing cannot be used and LIKE is not quick enough, did you consider building a custom index?
Can you elaborate more ? We tried a regular NCI on the column, but it is a varchar(100) with very mixed data. Did you have something else in mind? Also keep in mind that a like search will require wildcards and result in a full table scan every time.

Yes, your operation is correct. Full-text breaks the text into words and index those words. Which means that finding something that start with these words is quick. But it does not help you find fragment in words.
If you want to find fragment in words and you find LIKE to be a tad slow, there is a way to speed it up: cast to a binary collation
SELECT * FROM tbl WHERE col COLLATE Latin1_General_BIN2 LIKE '%ABC%'
Which gain you make depends on your current collation and data type. Or more precisely, you will make a gain of a factor 7-10 if you have nvarchar or a Windows collation. If you have an SQL collation and varchar, your gain will be quite modest.
If you want to it go as about as fast as full-text can give you, this is possible, but it requires heavy artillery. I have actually written about this, but in difference to about everything else I've written, this is not available on my web site, but in a book, where the royalities go to WarChild International. You can find a teaser here: https://www.sommarskog.se/yourownindex.html.
Thank you Erland! We will investigate this as well!
Full text search breaks strings into "words". Numbers and letters are not "words". Full text indexes will not work for what you are trying to use it for.
Full-text queries perform linguistic searches against text data in full-text indexes by operating on words and phrases based on the rules of a particular language such as English or Japanese.
Tom, thanks for the response, for the most part I believe you are correct, however we have successfully used this in the past for numeric searching. After doing more testing and working with this today, I believe this is treating these searches truly as a starts with , not contains, so if we pass a partial string, even with wild card operators, its returning data as if its a start with search.
As an example, passing '*AC07*' is returning items leading with AC07 but passing in '*C07*' is resulting in receiving only data back that starts with C whereas we thought it would include AC07. I think this is the crux of our issue and we are working towards a different resolution.
Thanks!
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBZ%3C/text%3E%3C/svg%3E)
Welcome to Microsoft T-SQL Q&A Forum!
Maybe you don't need to use like because of inefficiency, well I hate to use it when there are large data, here I suggest you to change the full text parser (take a neutral language: NaturalLanguage6.dll) and English format.
Below is my test data:
CREATE FULLTEXT CATALOG FullTexttest22
CREATE TABLE TF (Id INT NOT NULL, AllText NVARCHAR(400))
CREATE UNIQUE INDEX test_tfts2 ON TF(Id)
CREATE FULLTEXT INDEX ON TF(AllText language 2057)
KEY INDEX test_tfts2 ON FullTexttest22
WITH CHANGE_TRACKING AUTO, STOPLIST OFF
INSERT INTO TF
VALUES (1, ' 123_456 789 '), (2, ' 789 123_456 '),
(3, ' 123_456 ABC '), (4, ' ABC 123_456 ')
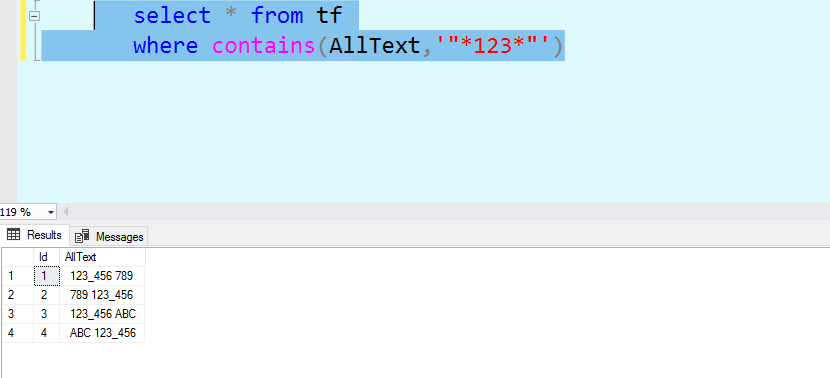
select * from tf
where contains(AllText,'"*123*"')
Here is a link about Change tokenizer.
Just a reminder: you have to add an extra step. When the parser change is done, the FTI has to be dropped and recreated to refresh the data, my database version is 2008 and debugging works fine at the moment.
Data I use:
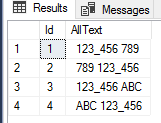
test results:
Best regards,
Bert Zhou
If the answer is the right solution, please click "Accept Answer" and kindly upvote it. If you have extra questions about this answer, please click "Comment".
Note: Please follow the steps in our Documentation to enable e-mail notifications if you want to receive the related email notification for this thread.
Thank you Bert! Do you know how much , if any changing the parser will affect our word searching FTIS? I understand we will need to test on our own, but thought maybe you might have some idea what these changes may mean for that.
Hi,@ ShoemakerDon-9960
At present, many people have encountered this problem using contains, but I am sorry that there is no solution that can complete the target search through contains.
For the retrieval of intermediate fields, full-text search has never been so easy to use. After consulting relevant materials and tests, I found it Only helps words that end with a target, not words with a target in the middle. It feels a lot like a data/code smell, I think you're better off using the regular "LIKE %abc%" or switching the database engine to modify the code, thanks.