Azure Machine Learning
An Azure machine learning service for building and deploying models.
3,337 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ET%3C/text%3E%3C/svg%3E)
Hello,
Is it possible to use a PipelineParameter (defined in a DataFactory 'Machine Learning Execute Pipeline' activity) during the creation of a OutputFileDatasetConfig object in said Machine Learning pipeline?
My DataFactory pipeline runs on a schedule (via a trigger) and executes an Azure ML pipeline which does data preparation and model training.
The trigger start date is passed as a parameter 'date_time' to the ML pipeline.
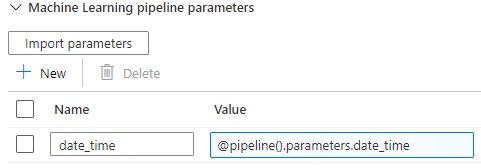
In my ML pipeline, I want to save the model artifacts (trained in a PythonScriptStep) to a blob path (default_datastore + 'output_model/{date_time}') which contains the value of the 'date_time' parameter. But I can't figure out a way to use the value of 'date_time' during the creation of the OutputFileDatasetConfig object (maybe there is a simple way to save model artifacts than to use a OutputFileDatasetConfig object?).
As a temporary hack, I am using a variable 'today_date' in my ML pipeline definition which contains today's date, and I use this variable to build the destination path of OutputFileDatasetConfig.
But the ideal solution would be to get the actual date directly from the DataFactory trigger parameter.
This is how I do now in my ML pipeline (not ideal):
import datetime
today_date = datetime.date.today().strftime('%Y%m%d')
model_output_path = (def_data_store, f"output_model/{today_date}")
output_config = OutputFileDatasetConfig(destination = model_output_path)
This is what I tried in order to get the value of PipelineParameter, but it didn't work:
pipeline_parameter = PipelineParameter(name="date_time", default_value=today_date)
model_output_path = (def_data_store, f"output_model/{pipeline_parameter}")
output_config = OutputFileDatasetConfig(destination = model_output_path)
It seems the only way to get the value of the PipelineParameter is through an argument inside a PythonScriptStep.
I don't think I can create the OutputFileDatasetConfig object INSIDE the PythonScriptStep.
Is there any other way to easily save model artifacts to a specific blob path which contains the value of a PipelineParameter?

Hi @ThierryL-3166 ,
Thank you for posting query in Microsoft Q&A Platform.
As I understand your query here, you want to pass a value to your ML pipeline experiment from ADF. Please correct me if I am wrong.
As you are correctly identified "Machine learning Pipeline Parameters" section area is right place to pass value to your ML pipeline parameters.

Here your ML pipeline should has a parameter defined with name "data_time". So that "ML Execute pipeline" activity can pass value to that parameter.
Click here know more details about "ML Execute pipeline" activity property details.
Hope this helps. Please let us know how it goes. Thank you.
Hello and thanks for your answer.
I solved my problem and I will explain how.
What I was trying to do was to get the value of a PipelineParameter (containing the date at which the pipeline was triggered by Data Factory) in my Azure ML pipeline definition script in order to use it in the destination name of my OutputFileDatasetConfig object. Basically I wanted the destination name to be something like 'output_model/20220328' where '20220328' is the value of the PipelineParameter.
But it seems impossible to read the value of a PipelineParameter outside of a PythonScriptStep.
What I did to solve this is to create my OutputFileDatasetConfig first without specifying the full destination path.
I specify only 'output_model' in the path. Then I get a reference to the PipelineParameter (at this point I still don't know its value).
model_output_config = OutputFileDatasetConfig(destination = (def_data_store, 'output_model'))
output_model_date = PipelineParameter(name="date_time", default_value="20220328")
Then I pass both references as arguments to my PythonScriptStep.
train = PythonScriptStep(
name="Train model",
script_name="train.py",
source_directory="./",
arguments=[
"--output-model-dir", model_output_config ,
"--output-model-date", output_model_date
],
compute_target=compute_target,
runconfig=aml_run_config
)
And finally in my training script I get the actual value of the PipelineParameter and I just concatenate both parameters to create the full path:
parser.add_argument("--output-model-dir", type=str, dest="output_model_dir", default="output_model", help="Directory to store trained output models and artifacts")
parser.add_argument("--output-model-date", type=str, dest="output_model_date", default="20220328", help="Date to use in the name of the output model folder")
output_model_dir = args.output_model_dir
output_model_date = args.output_model_date
full_output_model_dir = os.path.join(output_model_dir, output_model_date)
And now I can save directly my model artifacts to 'full_output_model_dir'.