Azure Data Lake Storage
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESC%3C/text%3E%3C/svg%3E)
Hi Microsoft Team,
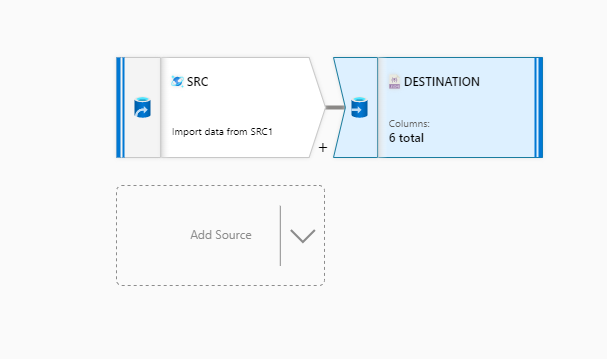
We have a Azure Data Factory Pipeline which executes a simple Data Flow which takes data from cosmosdb and sinks in Data Lake . As destination Optimize logic , we are using Partition Type as Key and unique value partition as a cosmosdb identifier. The destination Dataset also has a compression type as gzip and compression level to Fastest
Problem:
The data is partitioned as expected but we do not see the compression on the files created. Is this the expected behavior or is it a bug ? Can some one please help.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EH%3C/text%3E%3C/svg%3E)
Hello @Suman C ,
Thanks for the question and using MS Q&A platform.
As we understand the ask here is to check if the records can be compressed to gzip format , please do let us know if its not accurate.
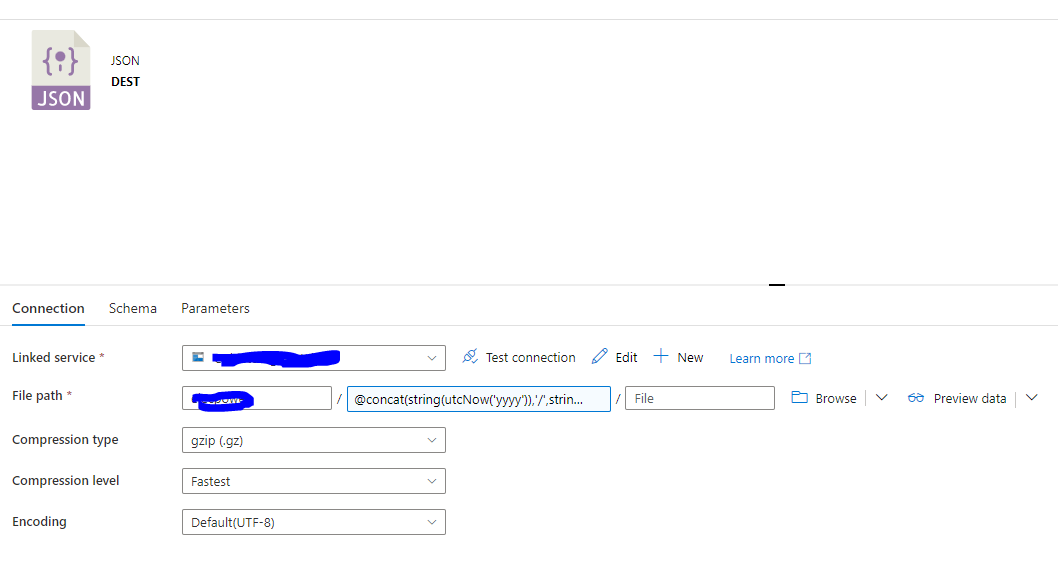
From the screenshot it appears that the you are trying to compress JSON to Gzip format . As per the ciocument here https://learn.microsoft.com/en-us/azure/data-factory/format-json , this should be a supported .
<< extract from the document >>
The compression codec used to read/write JSON files.
Allowed values are bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy, or lz4. Default is not compressed.
Note currently Copy activity doesn't support "snappy" & "lz4", and mapping data flow doesn't support "ZipDeflate"", "TarGzip" and "Tar".
Note when using copy activity to decompress ZipDeflate/TarGzip/Tar file(s) and write to file-based sink data store, by default files are extracted to the folder:<path specified in dataset>/<folder named as source compressed file>/, use preserveZipFileNameAsFolder/preserveCompressionFileNameAsFolder on copy activity source to control whether to preserve the name of the compressed file(s) as folder structure.
Whikle tr4rying with the CSV file I can see that this is working but i was not able to make it work for JSON .

I am reaching out to the internal team on this and I will update you this once I hear back from them .
Please do let me if you have any queries.
Thanks
Himanshu
Hello @Suman C ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet .In case if you have any resolution please do share that same with the community as it can be helpful to others . Otherwise, will respond back with the more details and we will try to help .
Thanks
Himanshu