Azure Backup
An Azure backup service that provides built-in management at scale.
1,498 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAH%3C/text%3E%3C/svg%3E)
Hello all, we'd love to use MARS but it is appearing unreliable.
This is a new installation. Latest agent installed.
It is a folder structure of 9TB of files&folders from an NTFS server volume, Windows Server 2016.
It will not complete the metadata VHD generation stage (takes forever to fail then restarts....) .
Error in window is "The current backup operation failed because the number of data transfer failures was more than 1000 Specified files could not be processed. 0x186D9"
The VHD appears to get corrupted after almost 12 hours.
Event viewer logs show event IDs such as 55 & 98 at the time of the fail.
The NTFS log also has an entry like this Event ID 305:
NTFS failed to mount the volume.
Event 305
Error: {Device Offline}
The printer has been taken offline.
Volume GUID: 3484a289-6bce-4bff-ae7c-0b3c325b0e37
Volume Name: Volume3484a289-6bce-4bff-ae7c-0b3c325b0e37
The volume is recognized by NTFS but it is corrupted that NTFS could not mount it. Run CHKDSK /F to fix any errors on this volume, and then try accessing it.
This has happened 3 times.
I have been into the logs in the agents' \temp folder.
Entries such as the below appear frequently.
MetadataVhdWriter.cpp(337) [0000022B70C0B090] 370EAC9B-DAFD-47B9-BE82-9887E87356DD WARNING Failed: Hr: = [0x80070570] : Encountered Failure: : lVal : hr
190C 2C08 04/22 02:24:04.867 32 VhdMgmt.cpp(5221) [0000022B69ADBD90] 370EAC9B-DAFD-47B9-BE82-9887E87356DD WARNING Failed: Hr: = [0x80070570] Failed to get free volume space for Metadata vhd volume path = [\Volume3484a289-6bce-4bff-ae7c-0b3c325b0e37]
The job fails then retries and remounts the VHD approx 15 mins later but seems to be doing the entire VHD generation again.....
c:\hh>err_6.4.5 0x80070003
or hex 0x80070003 / decimal -2147024893
COR_E_DIRECTORYNOTFOUND corerror.h
he specified path couldn't be found.
he system cannot find the path specified.
matches found for "0x80070003"
c:\hh>err_6.4.5 0x80070570
ERROR_FILE_CORRUPT winerror.h
The file or directory is corrupted and unreadable.
1 matches found for "0x80070570"
The errors indicate a problem with the destination VHD (I think anyway) rather than the source and the source files are accessible and readable and do not seem corrupt in any way.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAH%3C/text%3E%3C/svg%3E)
@SadiqhAhmed-MSFT Hi Sadiqh, this particular issue appears to be going around in circles again. I literally have no idea what is going on and although I'd love to stick with MARS I think we might have to abandon for another product :/
Could you perhaps point me in the right direction as to which logs to post for you with it?
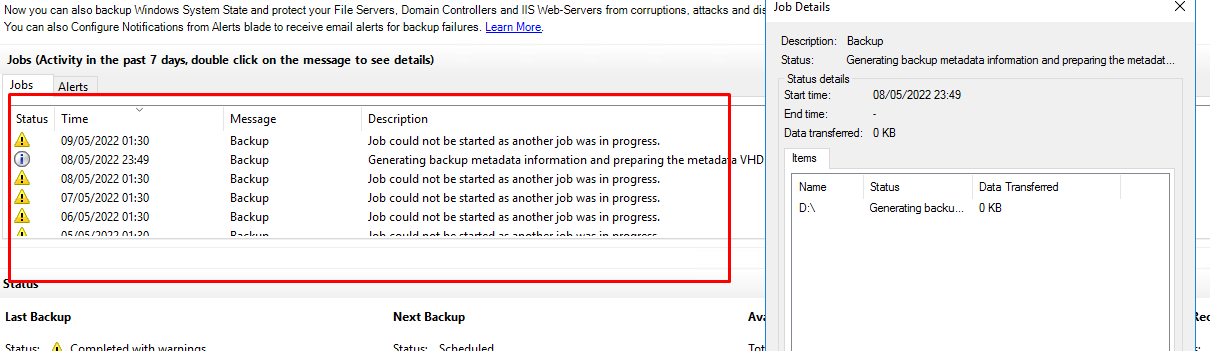
I have been through the FAQs again for MARS and on site servers, and I am also still unclear on what happens when a retention period is reached. For example we have a daily retention set for 7 days. What happens after 7 days? Does an entirely new VHD & Metadata process begin each time? If so, then it looks like the regeneration will take at least over 24 hrs before even beginning to xfer it up (we have an Express Route via Private Endpoints) in which case the backups can take 4 days or more to even get up there (including the initial metadata phase) - which renders the process pretty pointless really. At best we'd seem to get a couple of incremental restore points done before the VHD&Metadata has to be regenerated again.

I highly feel it is the Anti-Virus installed on the machine which is causing this metadata scenario and making it fail ultimately. Could you please select root folders and then keep on adding data?
As changing the backup selection would make MARS trigger backup scanning once again and go through all the data. This may delay the backup completion operation.
Hello, I am afraid I don't quite understand what you mean by:
'please select root folders and then keep on adding data'
Also, on the AV issue - it is set to not scan the folders associated with the scratch folder & also the installation folder for the agent, plus the process itself.
I can attach a log for you.
We can investigate the logs but public forum is not the right place to take this further. Recommend you to contact Azure backup technical support team by raising a support request.
@Andrew Howard Thank you for contacting us!
From the error details I can see that you are using MARS agent backup to backup a folder structure of 9TB and erroring out. This error code occurs when there is low disk space on drive C:.
To confirm the space need to the scratch folder, please check the following link - https://learn.microsoft.com/en-us/azure/backup/backup-azure-file-folder-backup-faq#what-s-the-minimum-size-requirement-for-the-cache-folder-
Another option is to relocate the scratch folder to another location. To change it, please see the following information: Change Scratch: https://learn.microsoft.com/en-us/azure/backup/backup-azure-file-folder-backup-faq#how-do-i-change-the-cache-location-for-the-mars-agent-
In your case, I also noticed the folder size is beyond the supported backup size limits - Refer to support matrix URL - https://learn.microsoft.com/en-us/azure/backup/backup-support-matrix-mars-agent#backup-limits
Recommendation: Please backup the data in smaller churns to avoid failures.
Hope this helps!
Update:
As the entire folder backup is 9TB (far less than the 54TB max that is specified) am I correct in thinking that there were too many files in the entire job from the perspective of the root folder level and that specifying the job using subfolders instead will overcome this?
Correct!
----------------------------------------------------------------------------------------------------------------------
If the response helped, do "Accept Answer" and up-vote it
Hi Sadiq. Thank you very much for getting back to me. I had a couple of days off for the weekend so I hadn't read this until now. I had a feeling scratch space could be an issue, but I was hoping I'd at least get a visible warning or pop up about this. Another MARS agent on another server does post a message in the "Alert" tab.
I will look at the the folder size. I am not quite sure what you mean by it being beyond the supported limits at this point (9TB isn't that much) but I'll see what I can do to mitigate this.
I'm guessing that rather than for example backup the one 9TB root folder (e.g. d:\9TBFolder) that I configure the job to do subfolders instead (e.d. d:\9TBFolder\folderA d:\9TBFolder\folderB etc etc)
Thank you so far!
We will wait for an update from you. Thanks!
The first step of the data upload is finally in progress. I have had to split the job into folders beneath previous 'root' folder of the structure.
As the entire folder backup is 9TB (far less than the 54TB max that is specified) am I correct in thinking that there were too many files in the entire job from the perspective of the root folder level and that specifying the job using subfolders instead will overcome this?
C: disk space isn't a problem.
The scratch is located on the D volume and there is more than 5 percent of 9TB free on the D volume.
As the entire folder backup is 9TB (far less than the 54TB max that is specified) am I correct in thinking that there were too many files in the entire job from the perspective of the root folder level and that specifying the job using subfolders instead will overcome this?
Correct!
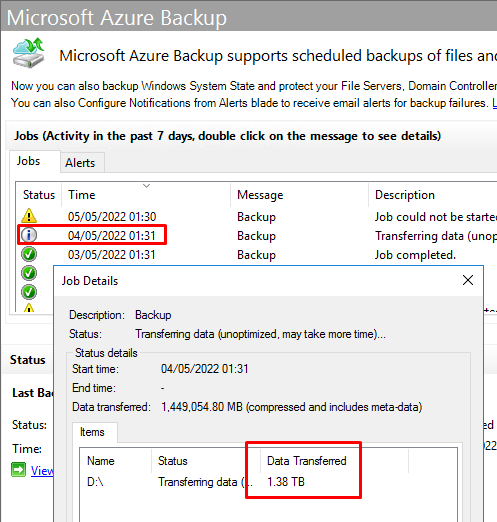
Hello. In way of an update I have noticed that at 01:30 when the job was scheduled to run on 4th May that it has basically started again. No errors are reported in the MARS GUI.
I had repeated the same steps as previous days and added a few extra folders to the job in order to build it up. However we seem to have gone from over 3TB stored back to the beginning and the VHD recreation process began and we're current at 1.3TB uploaded rather than the 4+TB that I expected to see. What is happening? Is it the weekly retention (set at 7 days) doing this?