Azure AI Speech
An Azure service that integrates speech processing into apps and services.
1,413 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
Speech-to-text
In the docs en-US is listed as a language that supports custom model training with audio data.
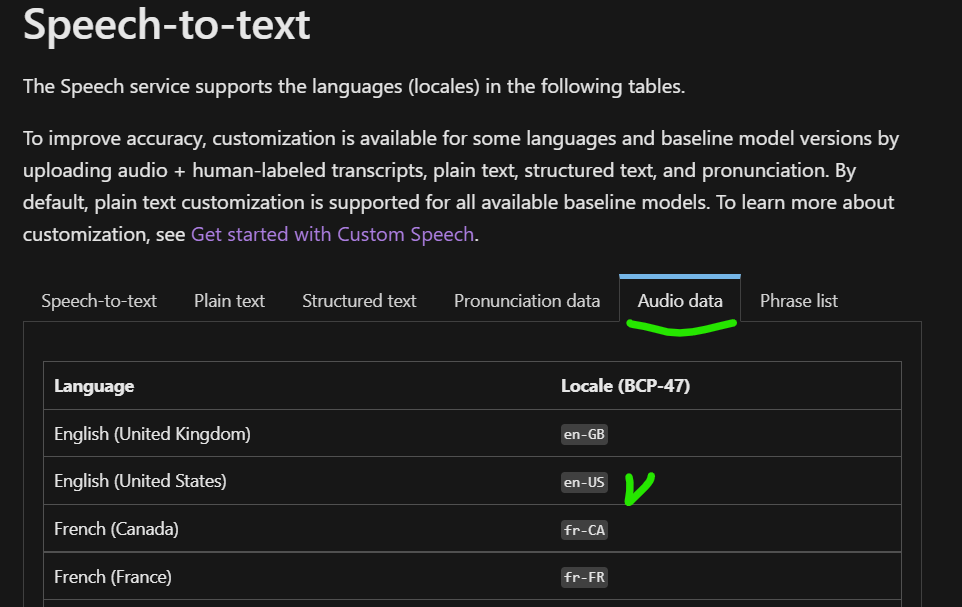
But in the Speech Studio there is no base models with audio data training support. Where did they go?!
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYM%3C/text%3E%3C/svg%3E)
@Alex Sorry for the misunderstanding and unclear document, this table you shared is not about the baseline model, it's about the lanauage supports for each feature. I know the description is confused, I will contact the content author to modify it.
The table you shared is related to input data and data type as below screenshots, this means, for languages in this table, the audio data input is supported:
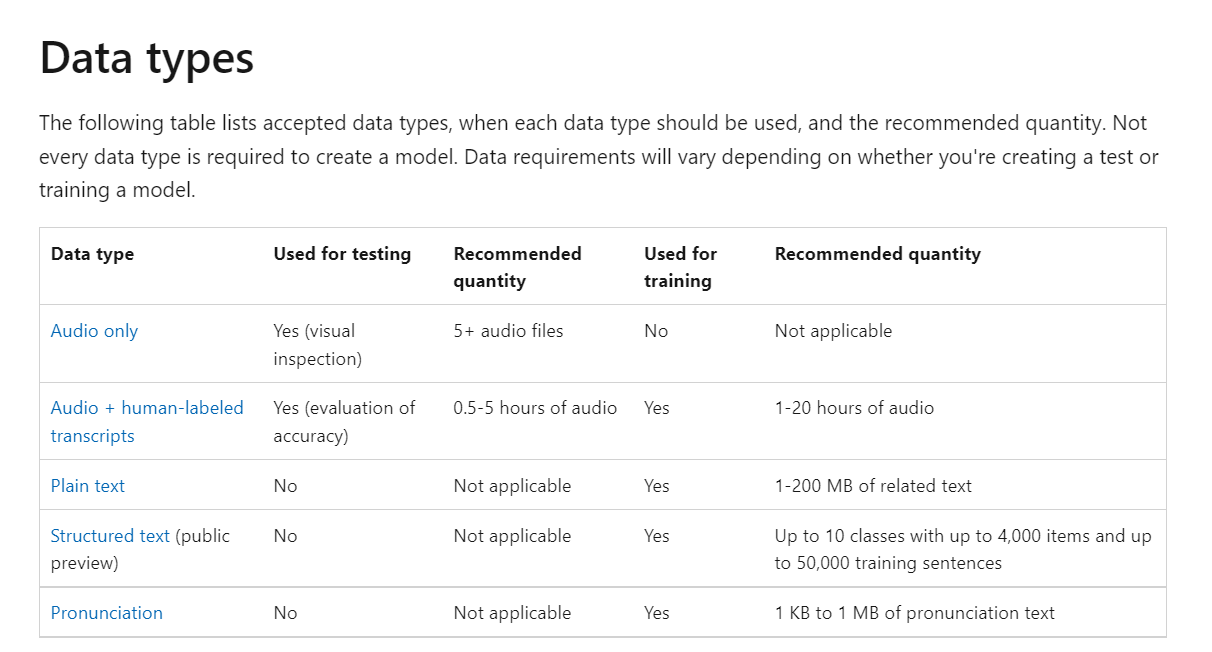
In the studio, it reflect below:
Sorry again for the misunderstanding.
I hope this helps.
Regards,
Yutong
-Please kindly accept the answer if you feel helpful, thanks a lot.
Thanks for the reply, Yutong.
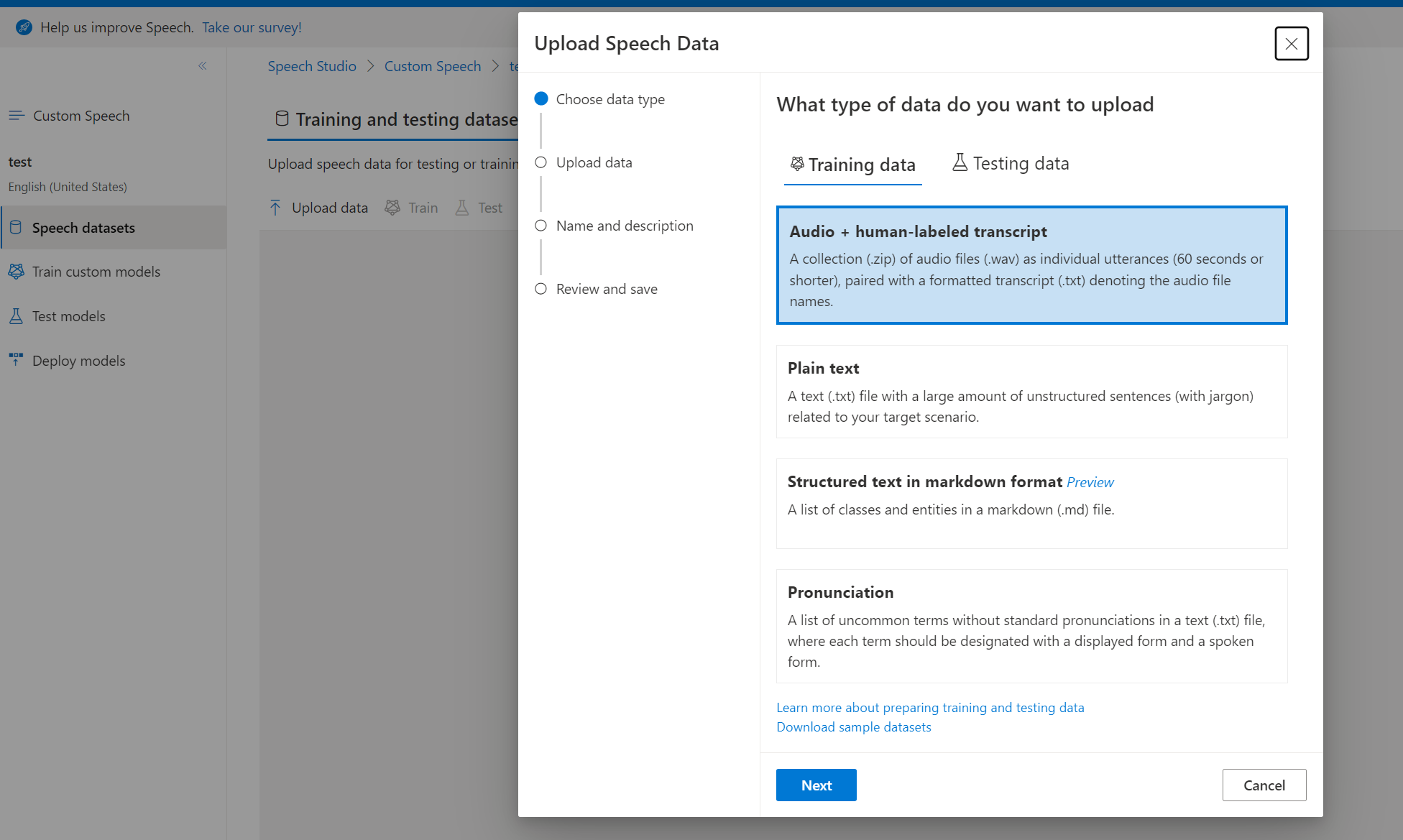
The problem is I can create a dataset of type "audio + human-labeled transcripts", but I don't see any base models in the list that support training using audio.
See below screenshot from the Add audio with human-labeled transcripts
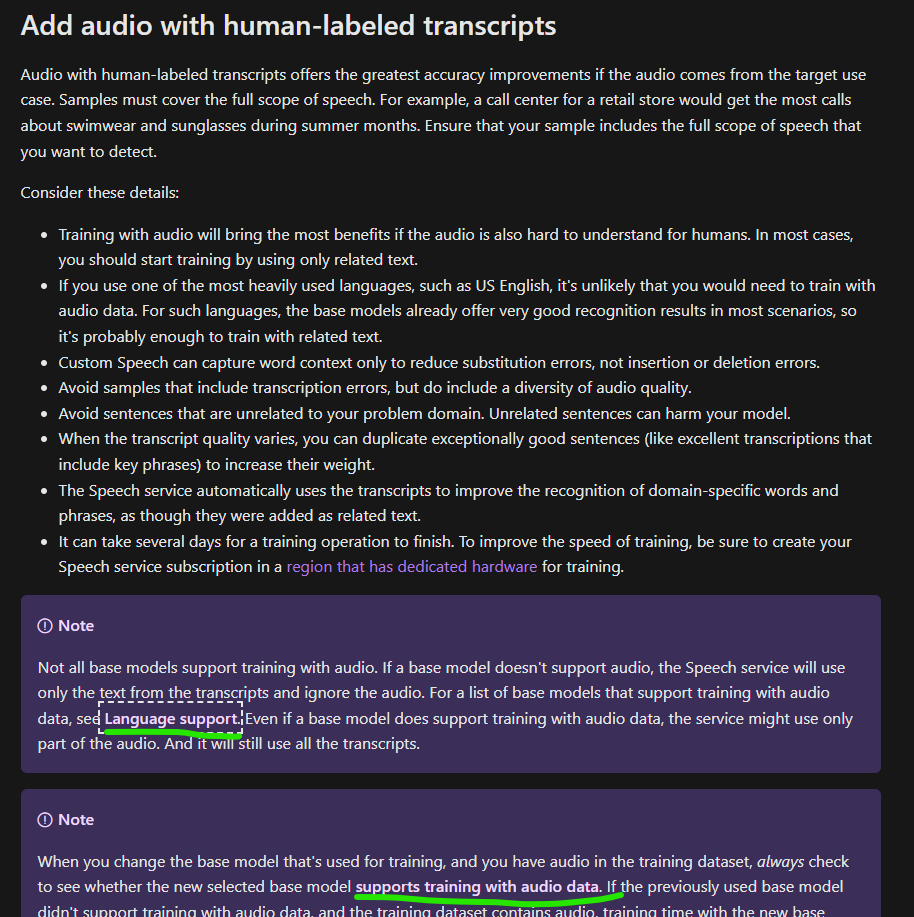
Note highlighted both links point to the same page as I mention in my original question.
I've tried various regions but I can't see any base models that support training with audio. Last time it did work was middle of March.
I wonder if I'm missing something.
Regards
Alex
Yes @Alex
There are region limilations but I have seen the same issue as well, let me double check with product team to see what it should be and also content team to update the document with more clear description. Sorry about the experience.

I will update later once I get any response from them. Thanks for the understanding.
Regards,
Yutong
Hi Yutong.
Thanks for looking into it.
Are there any updates from the product team? Thanks.
Regards
Alex
I see those baseline models with support for audio training data are back now.
Thanks for you help!