Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHD%3C/text%3E%3C/svg%3E)
I have created Synapse pipeline where inside for each loop spark notebook is executing for different objects. The operations that are performing inside are merging two tables or query that joins two tables.
There is one parent pipeline from which child pipelines are executing which contains the spark notebook activity. While executing the pipeline I have noticed that notebook activity execution taking much time although there is no complex data processing and data volume is very small.
My question is each time spark pool gets started when notebook activity gets executed inside for each loop ?

Hi @Anonymous ,
Thank you for posting query in Microsoft Q&A Platform.
The Synapse notebook activity runs on the Spark pool that gets chosen in the Synapse notebook. When we run notebook activity, spark pool takes time to start spark session. Once spark sessions starts thats when data processing will actually gets trigger.
You can select an Apache Spark pool in the settings. It should be noted that the Apache spark pool set here will replace the Apache spark pool used in the notebook. If Apache spark pool is not selected in the settings of notebook content for current activity, the Apache spark pool selected in that notebook will be used to run.
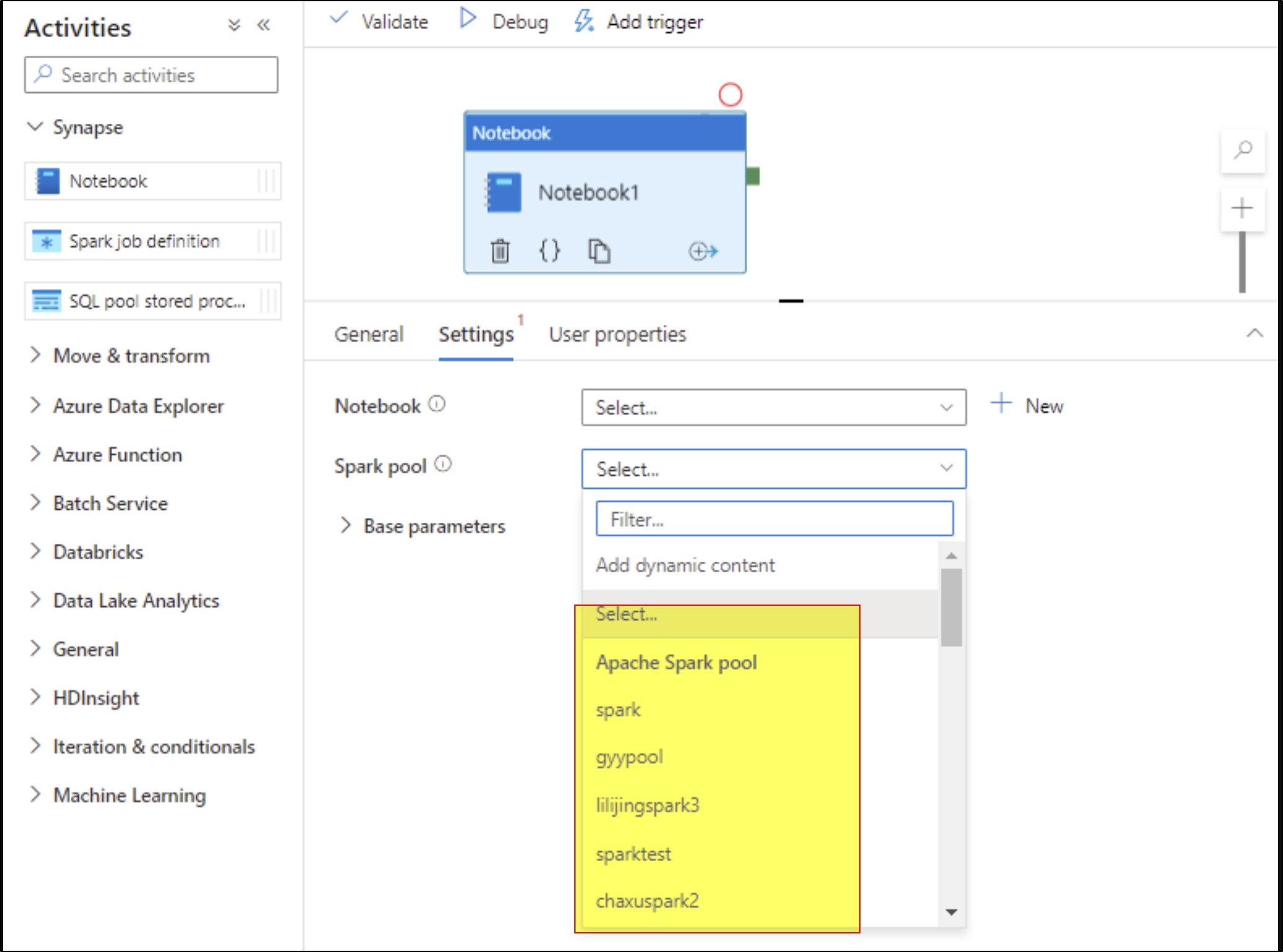
If we have multiple notebooks which you would like to run. Then try to chain them within the notebook. That means from notebook call another notebook. That way we wont end up using multiple synapse notebook activities and we don't end up taking more time for spark session to start every time.
We can use %run <notebook> or mssparkutils.notebook.run("<notebook>") to run one notebook from another.
Below are few useful videos to explain about above commands:
Hope this helps. Please let us know if any further queries.
-------------
Please consider hitting Accept Answer. Accepted answers help community as well.
Hi @Anonymous ,
Just checking in to see if the above answer helped. If this answers your query, do click  and upvote
and upvote  for the same. And, if you have any further query do let us know.
for the same. And, if you have any further query do let us know.