Azure Machine Learning
An Azure machine learning service for building and deploying models.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EE%3C/text%3E%3C/svg%3E)
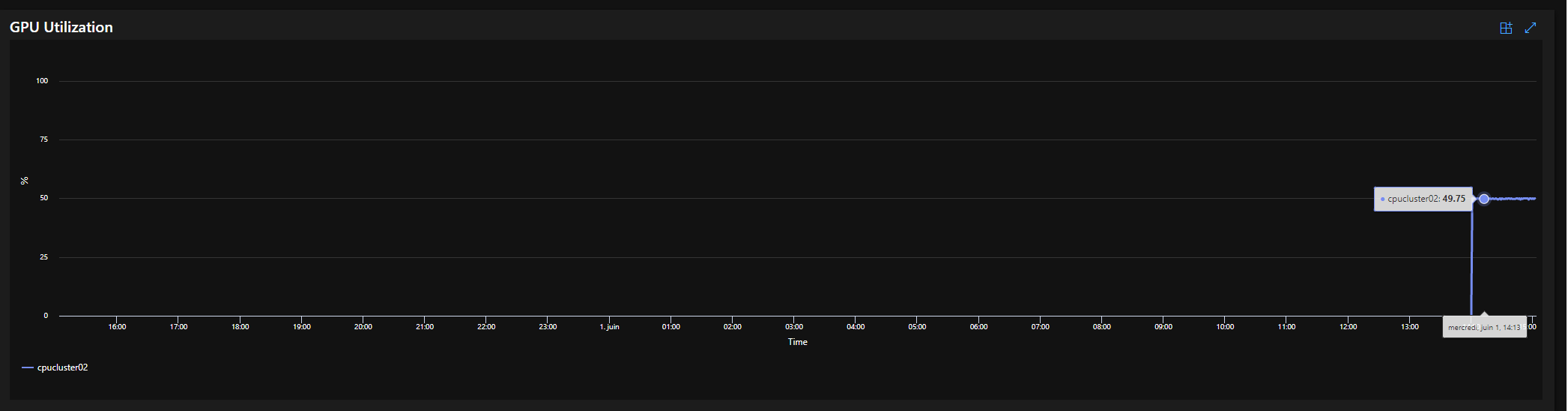
Azure does not use the two GPUs of my node with PyTorch (and Hugging Face). The monitoring tool of Azure shows the GPU usage is stuck at 50%.
Its a Standard_NC12, so it has two K80s.
I tried this way :
https://azure.github.io/azureml-cheatsheets/docs/cheatsheets/python/v1/distributed-training/#distributeddataparallel-per-process-launch
and it looked like this in my notebook :
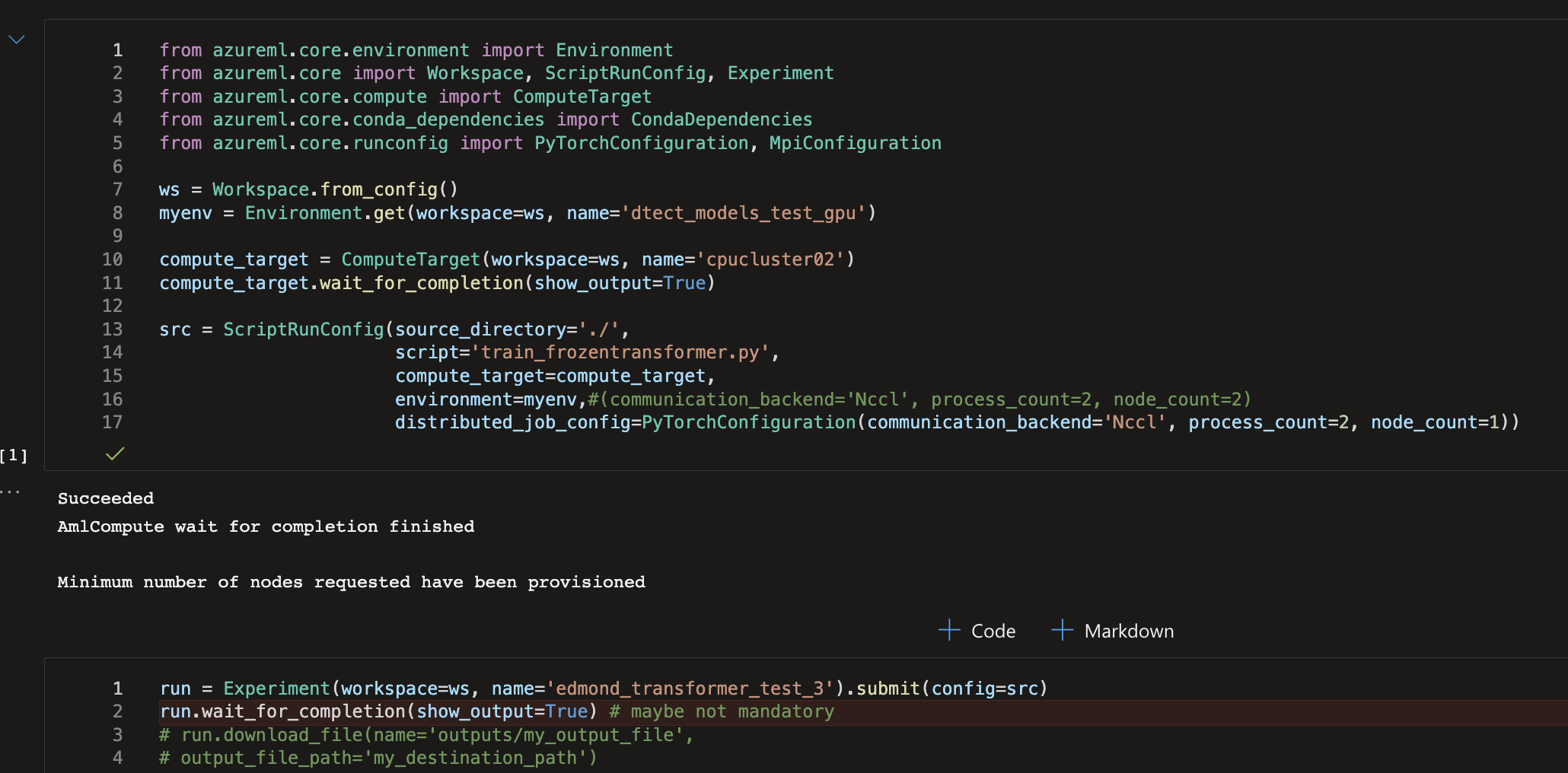
I copied the docker file from the curated environments and added the libraries I needed successfully :
FROM mcr.microsoft.com/azureml/openmpi4.1.0-cuda11.1-cudnn8-ubuntu18.04:20220329.v1
ENV AZUREML_CONDA_ENVIRONMENT_PATH /azureml-envs/pytorch-1.10
# Create conda environment
RUN conda create -p $AZUREML_CONDA_ENVIRONMENT_PATH \
python=3.8 \
pip=20.2.4 \
pytorch=1.10.0 \
torchvision=0.11.1 \
torchaudio=0.10.0 \
cudatoolkit=11.1.1 \
nvidia-apex=0.1.0 \
gxx_linux-64 \
-c anaconda -c pytorch -c conda-forge
# Prepend path to AzureML conda environment
ENV PATH $AZUREML_CONDA_ENVIRONMENT_PATH/bin:$PATH
# Install pip dependencies
RUN pip install 'matplotlib>=3.3,<3.4' \
'psutil>=5.8,<5.9' \
'tqdm>=4.59,<4.63' \
'pandas>=1.3,<1.4' \
'scipy>=1.5,<1.8' \
'numpy>=1.10,<1.22' \
'ipykernel~=6.0' \
'azureml-core==1.40.0' \
'azureml-defaults==1.40.0' \
'azureml-mlflow==1.40.0' \
'azureml-telemetry==1.40.0' \
'tensorboard==2.6.0' \
'tensorflow-gpu==2.6.0' \
'onnxruntime-gpu>=1.7,<1.10' \
'horovod==0.23' \
'future==0.18.2' \
'wandb' \
'transformers' \
'einops' \
'torch-tb-profiler==0.3.1'
# This is needed for mpi to locate libpython
ENV LD_LIBRARY_PATH $AZUREML_CONDA_ENVIRONMENT_PATH/lib:$LD_LIBRARY_PATH
RUN export CUDA_VISIBLE_DEVICES=0,1
I tried everything, I even added the CUDA_VISIBLE_DEVICES=0,1 inside the docker file.
My cluster is correctly configured because my colleague can use another tool (Detr with Lightning) and use 100% of the computing power.
I copied his docker file and the result was the same, so our guess is that his tool is automatically managing all GPUs for him.
Does anyone know why the cluster is using only one GPU ?

@Edmond I am curious to know if both the GPUs are detected. You could try to print the device count and check in the logs.
import torch
print(torch.cuda.device_count())
Also, I found that from NC series documentation:
1 GPU = one-half K80 card.
So, I think it has a total of 1 K80 card for 2 GPUs.
Does the node_count also be updated to 2 in the PyTorchConfiguration()?
model = nn.DataParallel(model)
did the job.
That's interesting because it was written :
Virtual machine size
Standard_NC12 (12 cores, 112 GB RAM, 680 GB disk)
Processing unit
GPU - 2 x NVIDIA Tesla K80
Then I guess I did not understand it properly and I am stuck using 50% of 1 K80.
print(torch.cuda.device_count()) gives :
2
node_count = 2 leads to :
Requested 2 nodes but AzureMLCompute cluster only has 1 maximum nodes.
(I also realized in the job's properties raw json that gpuCount is 0 in the compute and computeRequest sections)