Azure AI Document Intelligence
An Azure service that turns documents into usable data. Previously known as Azure Form Recognizer.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EM%3C/text%3E%3C/svg%3E)
I'm looking out for a way to extract tables text present in a PDF document using form recognizer. I tried creating a custom model for training with labels wherein different labels were defined using the OCR labeling tool. Although, the accuracy received is ~30% which is really less. A sample image of the table is attached (please ignore the red color oval lines).
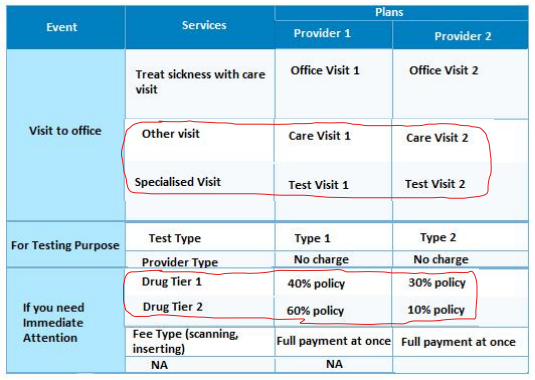
Is there a possibility to extract the content of the above table image into a .csv file?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EGM%3C/text%3E%3C/svg%3E)
Hi, thanks for reaching out. Currently, the supported output format is JSON. However, you can try to reformat the output to pandas dataframe and export to csv as shown in this example or check out other available resources online. Hope this helps.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ENH%3C/text%3E%3C/svg%3E)
That image should be pretty easy to process using forms recognizer. You will need a minimum of 5 images to train the model (but more will give better accuracy). You need to tag only the data elements you need (not any labels). If you have repeating groups such as services then tag each one with a separate tag service1, service2, service3, etc and the same for event, etc. Then you be able to see the accuracy grow as you add more tags across more invoices. I would create a simple azure function that monitors blob storage and then on receipt of a new file submits to form recognizer and takes the returned json output and writes back to blob storage a CSV (you may be able to write less code using a logic app).