Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJS%3C/text%3E%3C/svg%3E)
In our project we use dataflow to ingest data into a Postgre database from a csv file. We do a join before inserting with the table itself to detect which items have been updated and thus assign an update timestamp.
The problem occurs in this join, because if I remove it there are no problems. The database exceeds 100GB. The error does not give me much information as to what might be happening:
{"StatusCode":"DFInternalServerError","Message":"Job failed due to reason: Failed to execute dataflow with internal server error, please retry later. If issue persists, please contact Microsoft support for further assistance","Details":"org.apache.spark.SparkException: Job aborted.\n\tat org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:202)\n\tat org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelationCommand.scala:159)\n\tat org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:104)\n\tat org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:102)\n\tat org.apache.spark.sql.execution.command.DataWritingCommandExec.doExecute(commands.scala:122)\n\tat org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:157)\n\tat org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:153)\n\tat org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:181)\n\tat org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)\n\tat org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:1"}
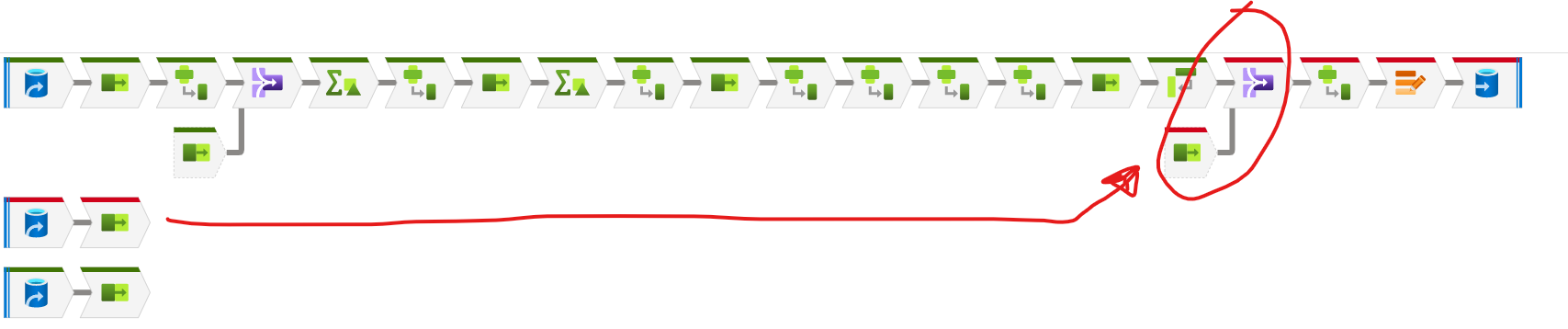
Does any one have the same problem recently?

Hi @Jaime Sendra ,
Thank you for posting query in Microsoft Q&A Platform.
Usually this kind of error will be transient. They may go away when we retry. If its not the case then underlying dataflow cluster creation may giving this error.
Please retry after some time and see if that helps. If not I would encourage you to have support ticket for this case to investigate deeper and get the resolution. Below is the link that helps with steps to submit support ticket.
https://learn.microsoft.com/en-us/azure/azure-portal/supportability/how-to-create-azure-support-request
Hi @Jaime Sendra ,
Just check if get chance to share any updates on this. Feel free to share if you found any other resolution, that helps community as well. Thank you.