Azure Data Lake Storage
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
1,348 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAS%3C/text%3E%3C/svg%3E)
I'm using mount point in synapse notebook as shown in MS Azure Docs.
I'm using same mount point and same path to read and write spark dataframe and that is working fine but while operation with pandas I'm facing this issue.
import pandas as pd
data = {'Name':['Tom', 'nick', 'krish', 'jack'],
'Age':[20, 21, 19, 18]}
df = pd.DataFrame(data)
mssparkutils.fs.mount(
"abfss://Container@storageAccountName.dfs.core.windows.net",
"/test",
{"linkedService":DefaultADLSlinekedservice)}
)
jobID=mssparkutils.env.getJobId()
mount_path='synfs:/{jobId}/test/'.format(jobId=jobID,)
df.to_csv(mount_path + '/myPath')
No such file or directory exists error
I used same mount point to read and write spark dataframe it's working fine but with pandas dataframe I'm having this issue

Hi @Amit Sopan Shendge ,
Thank you for posting query in Microsoft Q&A Platform.
If possible could you please share your code snippet along with error screenshot? So that We can try same and help better.
I have updated question with sample code I used.
Hi @Amit Sopan Shendge ,
Thank you for posting query in Microsoft Q&A Platform.
As per documentation of Pandas in Synapse notebooks. I see example of using path URL along with linked service. So you can consider doing same in your case instead of mount point. Click here to see the same.
Below is the sample code.
#Read data file from URI of secondary Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path', storage_options = {'linked_service' : 'linked_service_name'})
I tried using mount point and ending up with the similar issue as yours. I suspect with pandas mount points may be not work. I am checking more on this internally. I will share updates soon.
Hope this helps. Please let us know if any furthher queries.
------------
Please consider hitting Accept Answer button. Accepted answer help community as well.
Hi @Amit Sopan Shendge - Just checking is above answer helped? If yes, Please consider hitting Accept Answer. Accepted answers helps community as well.
Please note, I am yet to receive update from PG on confirmation about Is Pandas work with mount point or not. I will be sharing updates soon. Thank you.
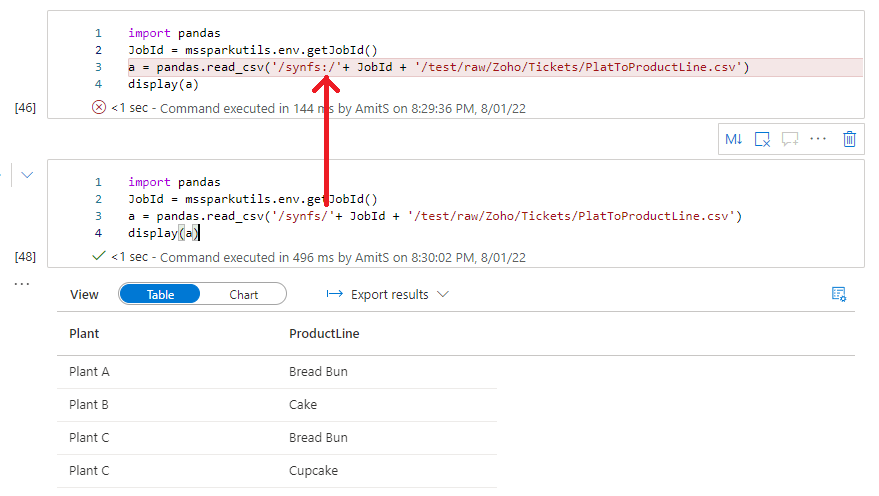
Hi @Amit Sopan Shendge - Pandas also working fine with mount points. There is small correction in the path syntax to use. Kindly use as /synfs/<jobid>/<mountpoint>/path. Please check below screenshot.
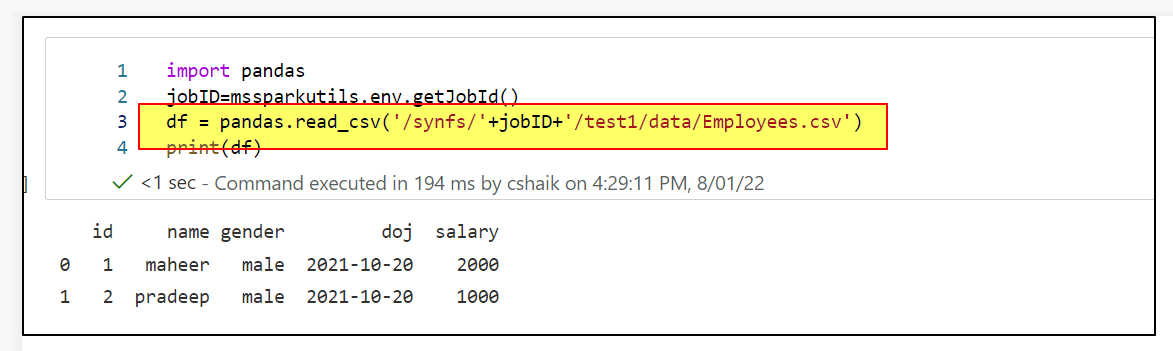
Hope this helps.
-----------
Please consider hitting Accept Answer button. Accepted answers help community as well.
Thank You all How Helped me. Special Thanks to @ShaikMaheer-MSFT
The only problem was Colen : It ruined my so many hours Just fired up my head.
Now I feel relaxed.