Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,624 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPV%3C/text%3E%3C/svg%3E)
Hello
we have a pipeline with data flow. Input are SQL Server tables, output csv.
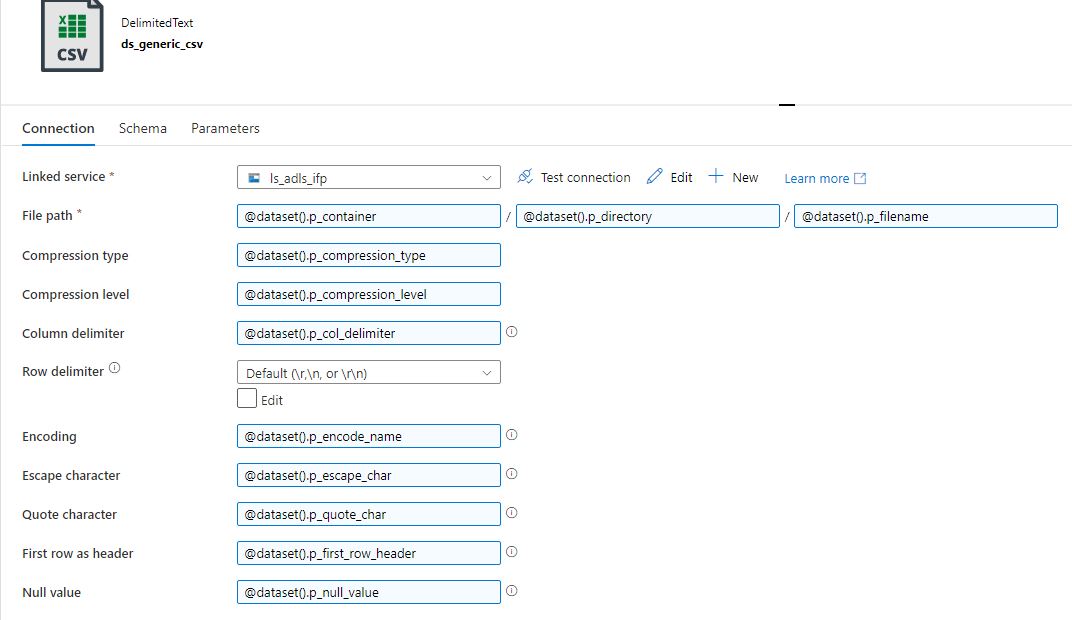
Values are filled as follows
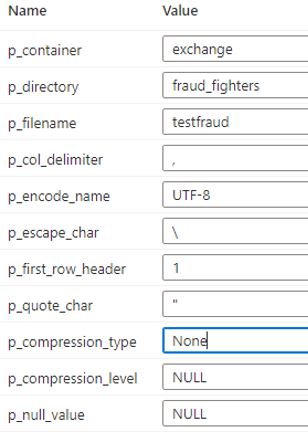
When using a Copy activity in a pipeline everything works fine. We get a csv, layout correct
But if we use the same dataset as a Sink in a data flow, it keeps on writing Parquet, whatever we change.
Only if we change in Settings of the Sink 'File name options' from Default to Output to single file, and in Optimize tab set Single partitioning on, it will create a file with extension csv.
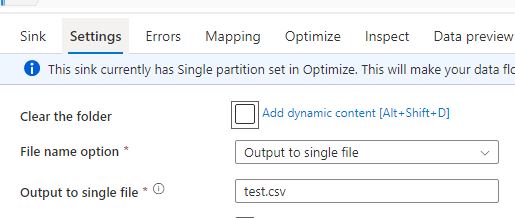
But the content is still Parquet, some binary format.
What is the issue here?
Does anybody know?
regards
Ron
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello Ron @Poel van der, RE (Ron) and welcome to Microsoft Q&A.
Lets see if I get this right. Your CSV dataset works fine as copy activity sink, but has unexpected behavior as Data Flow sink.
Things are as expected if and only if "single partition" and "File name option -> Output to single file" is selected. All other permutations end up as parquet.
To clarify, what do you expect to happen when multiple partitions are selected? What do you expect to happen when file name option is not Output to single file?
Do you expect a folder containing multiple csv files? It is not an unreasonable assumption, I'm just checking. Getting a totally different file format sounds weird to me too.
I'll try to reproduce this on my end. I am making the assumption the source dataset does not matter.
In my experience, it is not always easy to tell what gets decided by the Data Flow and what gets decided by the Dataset. For example, the functionality of "Output to single file" name overlaps with the Dataset file name.
somebody advised me to delete the Sink and create it again.
I did and the problem was solved. I am getting a csv with correct content.
What caused the issue is unclear to me.
So tip. In these cases first delete and recreate the Sink.
Thnx for your help.
Thank you for sharing the resolution @Poel van der, RE (Ron)
I am also unclear what would cause this behavior. Did you have the "preview studio updates" feature enabled? I have seen different weird behavior from the update, but not like yours before.
If this issues happens again, and you can cause it at will, let me know and i can send a bug report to the development team.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EOG%3C/text%3E%3C/svg%3E)
I was having the same issue, thought I might've clicked something so I recreated my sink dataset and still would not work. Deleted the Sink and tried again and lo and behold the data was written correctly, Thank you!