Azure SQL Database
An Azure relational database service.
6,326 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EN%3C/text%3E%3C/svg%3E)
Hello,
we are currently replicating D365 Dataverse data to Azure SQL Database as per this MS document. We have built multiple data models that drive a number of PowerBI dashboards.
However, as per that same article MS claims that the "Data Export Service" will reach end-of-life in November 2022 and encourages customers to export their Dataverse data to Azure Synapse Analytics and/or Azure Data Lake Gen2. As such we have created data export(s) via "Azure Synapse Link for Dataverse" and into a Azure Data Lake Gen2 storage account.
However, we are unclear how to query this data now and how to create and enrich our data models as we have previously done in Azure SQL Database so that our PowerBI dashboards continue to function.
Is there a way (preferably using SQL) to directly query Azure Data Lakes and/or create data models that PowerBI can consume? If so, how?
If not, what are our industry best practice(s) ways forward from here?
many thanks,
Nem
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESM%3C/text%3E%3C/svg%3E)
Hi @Nem ,
Just checking in to see if the below answer provided by @Nandan Hegde and @Alberto Morillo helped. If this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.

Hey,
You can follow the below architecture:
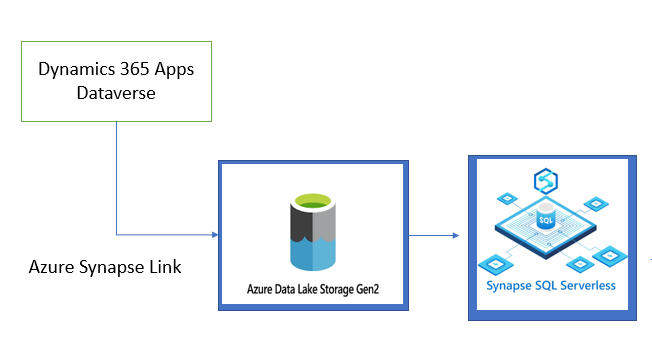
you can leverage synapse serverless to query data from ADLS gen 2
https://endjin.com/blog/2021/05/how-to-use-azure-synapse-sql-serverless-to-connect-data-lake-and-power-bi

You can use serverless Synapse SQL pools to enable your Azure SQL to read the files from the Azure Data Lake storage. Please read on this article of the steps needed.
Thanks for your input Nandan & Alberto!
Would there be a way to do this without using Azure Synapse Analytics? Or is a ASA workspace the only way to accomplish querying ADL data with the familiarity of using T-SQL syntax?
That is they way to do it to my knowledge. We need to use ASA.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EVS%3C/text%3E%3C/svg%3E)
@Nem If you are familiar with Databricks, you can use Azure Databricks SQL endpoint to query the data in the lake using SQL. Create a non managed delta table from databricks and then its matter of querying the table. You can do this via Databricks SQL endpoint or via all-purpose cluster using SQL queries.