' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EV%3C/text%3E%3C/svg%3E)
4,707 questions
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYK%3C/text%3E%3C/svg%3E)
Hi @VS29 ,
Please try the following solution.
It is using tokenization technique via XML and XQuery.
SQL
DECLARE @input VARCHAR(1000) = 'Mailing: XYZ ABC Street, Dallas, TX, 45862 Residence: XYZ GHD Street, Detroit, MI, 45864 Other: XYZ ABC Street, Denver, CO, 45862 Business: XYZ ABC Street, Cleveland, OH, 45862 Residence: YTRH GHD Street, Detroit, MI, 45864';
DECLARE @separator CHAR(1) = ',';
SET @input = REPLACE(REPLACE(REPLACE(REPLACE(@input
, ' Mailing:', ',Mailing:')
,' Residence:', ',Residence:')
,' Other:', ',Other:')
,' Business:', ',Business:')
DECLARE @input_XML XML =
TRY_CAST('<root><r><![CDATA[' +
REPLACE(TRIM(',' FROM @input), @separator, ']]></r><r><![CDATA[') +
']]></r></root>' AS XML);
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS Nmbr
, TRIM(c.value('(/root/r[sql:column("seq.pos")]/text())[1]', 'VARCHAR(30)')) AS Address
, TRIM(c.value('(/root/r[sql:column("seq.pos") + 1]/text())[1]', 'VARCHAR(30)')) AS City
, TRIM(c.value('(/root/r[sql:column("seq.pos") + 2]/text())[1]', 'VARCHAR(30)')) AS State
, TRIM(c.value('(/root/r[sql:column("seq.pos") + 3]/text())[1]', 'VARCHAR(30)')) AS Zip
, seq.pos -- just to see
FROM @input_XML.nodes('/root/r[position() mod 4 = 1]') AS t(c)
CROSS APPLY (SELECT t.c.value('let $n := . return count(/root/*[. << $n[1]]) + 1','INT') AS pos
) AS seq;
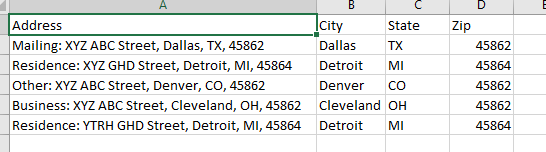
Output
+------+----------------------------+-----------+-------+-------+-----+
| Nmbr | Address | City | State | Zip | pos |
+------+----------------------------+-----------+-------+-------+-----+
| 1 | Mailing: XYZ ABC Street | Dallas | TX | 45862 | 1 |
| 2 | Residence: XYZ GHD Street | Detroit | MI | 45864 | 5 |
| 3 | Other: XYZ ABC Street | Denver | CO | 45862 | 9 |
| 4 | Business: XYZ ABC Street | Cleveland | OH | 45862 | 13 |
| 5 | Residence: YTRH GHD Street | Detroit | MI | 45864 | 17 |
+------+----------------------------+-----------+-------+-------+-----+