用HDInsight进行中文处理(系列一)
对于大数据处理而言,文字方面的处理一直是一个非常重要的应用领域。在本系列里面,我们将针对中文文字的处理,借用大数据平台HDInsight做一些尝试。
HDInsight的本源其实是Apache Hadoop, 是用Java语言开发的。HortonWorks把它移植到了Windows平台,微软又把它架到了云端。Hadoop提供了一个非常有意思的方式,称为Streaming,通过控制标准输入输出流,我们可以很巧妙地使用任何其他语言来编写MapReduce的程序。微软提供的SDK本身也是基于这样一个方式。
然而巧妙归巧妙,从效率而言,要创建一个高效的MapReduce,自然用原生的方式也就是Java来直接写Mapper跟Reducer更靠谱. 作为微软平台的开发者,大多数人都比较熟悉.NET的编程。 但是对于Java却一知半解。Java曾经因为法律和同业竞争的问题,一直是微软的一个比较敏感的话题。时光荏苒,当云服务成为主流,摒弃前嫌而有效整合各种技术为客户服务才是王道。所以Java和开源也成为微软的选择。
接下来我们就来摸索一下如何编写Java的MapReduce。
第一步: 配置Java的环境
1.1 最淳朴的Java环境自然是安装JDK。安装对应的Windows版本就可以了。
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
在安装的时候,按照一些文档的建议,安装的路径最好不要带有空格。比如安装在\Program Files\下也许并不太合适。
安装完以后,需要设定JAVA_HOME这样的环境变量。直接在 Control Panel->System->Advanced->Environment Variables 中设定即可。值就是对应的JDK目录,比如
c:\Java\jdk1.6.0_02
然后我们可以再把JDK的路径加在Path变量中
重启以后,检验一下Java的compiler, 也就是Javac是否可以运行。打开一个命令行窗口,输入:
javac -version
运行成功,代表配置可以了。
1.2 对于习惯了使用Visual Studio进行开发的开发人员来说,一个好的集成开发环境(IDE)是非常重要的提高生产力的工具。在Java的世界里也有这样的工具,比如Eclipse:
https://www.eclipse.org/downloads/
直接下载Eclipse IDE for Java Developer的Windows版本就可以了。无需安装,直接解压到对应的目录就可以了。
1.3 由于我们的Hadoop大数据平台很多项目都是用Apache Maven进行项目管理的,使用Maven会比较有效率。Eclipse也正好提供了对Maven的插件支持。我们就来配置Maven,并把它跟Eclipse整合起来。首先我们需要下载解压Maven:
https://maven.apache.org/download.cgi
下载zip包,然后解压到一个目录就可以了。
然后和JDK类似,设置环境变量MAVEN_HOME,再把Maven的目录加到Path变量中。
然后,打开Eclipse. 在Help->Eclipse Marketplace中可以找到Maven Integration for Eclipse:
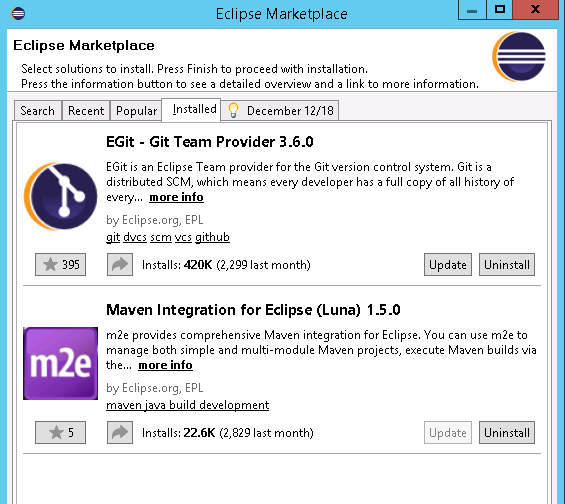
新版本Eclipse都已经安装了该插件,如果没有的话就搜索并安装一下。
另外,我们需要对Eclipse进行一些必要的配置。打开Windows->Preferences,展开Java->Installed JREs,注意把当前的路径设置为JDK所在的路径,不要使用JRE的路径。
然后展开Maven->Installations, 按下Add添加maven安装的目录,并且打钩:
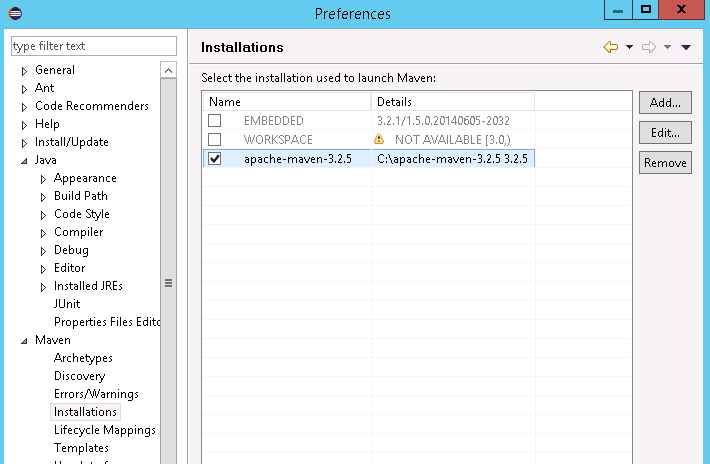
到此,我们的配置就完毕了。
接下来,我们就该开始创建我们的项目了。我们的原始项目是按照下面的步骤来做的
https://azure.microsoft.com/en-us/documentation/articles/hdinsight-develop-deploy-java-mapreduce/
但是如果要从Eclipse来编译的话,我们需要按下面的方式来。 从菜单里选File->New->Other,然后选Maven下的Maven Project。在选择Archetype的页面。我们原始的命令行是下面的样子:
mvn archetype:generate -DgroupId=org.apache.hadoop.examples -DartifactId=wordcountjava -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
所以在Wizard里我们找到ArtifactId为maven-archetype-quickstart。然后在下一页输入对应的信息:

按下Finish,Eclipse就会自动帮我们生成对应的一个非常简单的项目。
我们可以打开pom.xml来编辑它。
按照原来的指令,我们需要添加下面的dependency:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-examples</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.5.1</version>
</dependency>
所以我们手工添加这些dependency到pom.xml:
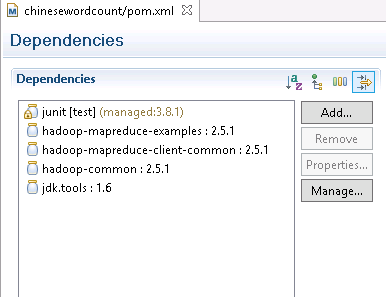
注意在有些环境里会报jdk.tools这个dependency找不到。其实这不影响我们进行编译。但是如果想解决这个问题,可以到命令行安装一下tools.jar:
Cd c:\java\jdk1.8.0_25\lib
Mvn install:install-file –DgroupId=jdk.tools –DartifactId=jdk.tools -Dpackaging=jar -Dversion=1.6 –Dfile=tools.jar -DgeneratePom=true
然后把jdk.tools:1.6也加为dependency
到这里我们可以把src/main/java下的App.java改名成WordCount.java,然后就可以编译了。
我们可以在Package Explorer里右键点Package名字,然后选Run As->Maven Build…,然后在Goals里填入Clean Package。按下Run来生成Jar。