Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
【介绍】
SQL Server 通过WORKER, SCHEDULER, TASK等来对任务进行调度和处理。了解这些概念,对于了解SQL Server 内部是如何工作,是非常有帮助的。
通常来讲,SCHEDULER个数是跟CPU个数相匹配的 。除了几个系统的SCHEDULER以外,每一个SCHEDULER都映射到一个CPU,如下面的查询结果所示,我们有四个CPU,也就有相应四个SCHEDULER。
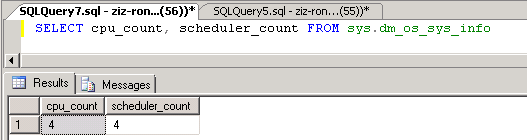
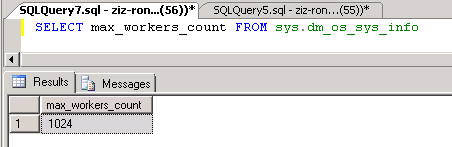
而WORKER (又称为WORKER THREAD), 则是工作线程。在一台服务器上,我们可以有多个工作线程。因为每一个工作线程要耗费资源,所以,SQL Server有一个最大工作线程数。一个TASK进来,系统会给它分配一个工作线程进行处理。但是当所有的工作线程都在忙,而且已经达到了最大工作线程数,SQL Server就要等待,直到有一个忙的工作线程被释放。最大工作线程数可以通过下面的查询得到。SQL SERVER并不是一开始就把这些所有的工作线程都创建,而是依据需要而创建。
TASK是由BATCH而来。我们知道,一个连接,可以包含多个BATCH,而每个BATCH则可以分解成多个TASK。如下面某一个连接要做的事情。这个连接要做的有两个BATCH,而每个BATCH,如SELECT * FROM TABLE_B,因为可以支持并行化查询,所以可能会被分解成多个TASK。具体BATCH怎么分解成TASK,以及分解成多少个,则是由SQL Server内部决定的。
INSERT INTO TABLE_B VALUES (‘aaa’)
GO
SELECT * FROM TABLE_B
GO
【关系】
我们初步了解了Connection, Batch, Task, Worker, Scheduler, CPU这些概念,那么,它们之间的关系到底是怎么样呢?
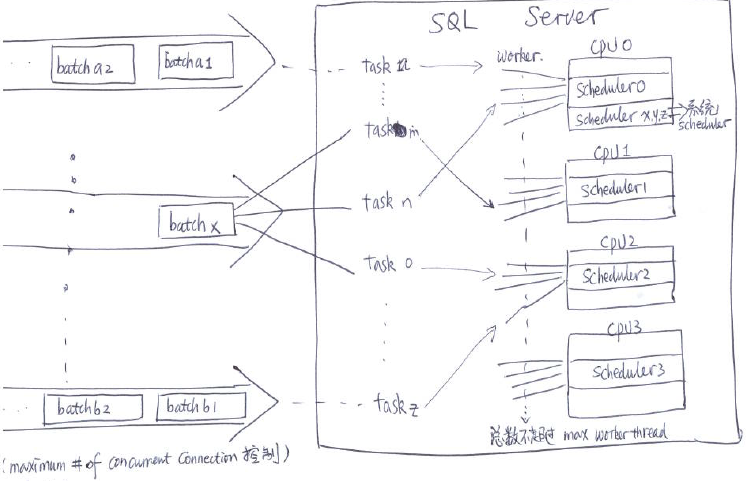
如上图所示,左边是很多连接,每个连接有一个相应的SPID,只要用户没有登出,或者没有timeout, 这个始终是存在的。标准设置下,对于用户连接数目,是没有限制的。
在每一个连接里,我们可能会有很多batch,在一个连接里,batch都是按顺序的。只有一个batch执行完了,才会执行下面一个batch。因为有很多连接,所以从SQL Server层面上看,同时会有很多个batch。
SQL Server会做优化,每一个batch,可能会分解成多个task以支持如并行查询。这样,在SQL层面上来看,同时会有很多个TASK。
SQL Server 上,每一个CPU通常会对应一个Scheduler, 有几个额外的系统的Scheduler,只是用来执行一些系统任务。对用户来讲,我们只需要关心User Scheduler就可以了。如果有4个CPU的话,那么通常就会有4个User Scheduler。
每个Scheduler上,可以有多个worker对应。Worker是真正的执行单元,Scheduler(对CPU的封装)是执行的地方。Worker的总数受max worker thread限制。每一个worker在创建的时候,自己需要申请2M内存空间。如果max worker thread为1024,并且那些worker全部创建的话,至少需要2G空间。所以太多的worker,会占用很多系统资源。
【跟踪】
我们了解了Connection, Batch, Task, Worker, Scheduler, CPU之间的关系,下面我们用DMV跟踪一下运作的流程。
步骤一:
执行下面的脚本,创建一个测试数据库和测试数据表
CREATE DATABASE TEST
go
use TEST
go
CREATE TABLE TEST
(ID int,
name nvarchar(50)
)
INSERT INTO TEST VALUES (1, 'aaa')
步骤二:
打开一个查询窗口,执行下面的语句,注意,我们这里并没有commit transaction.
begin tran
update TEST set name='bbb' where [ID] = 1
步骤三:
打开另外一个窗口,执行下面的语句,我们会看到,下面的查询会一直在执行,因为我们前面的一个transaction并没有关闭。从查询窗口,我们可以看到,下面语句执行的SPID为58
SELECT * FROM TEST
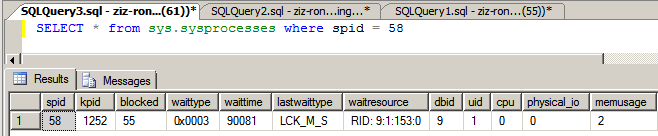
步骤四:查看连接。
从下面的查询来看,我们的连接对应的SPID是58,被block住了。
步骤五:查看batch
我们查看SQL Profiler, 看到我们的Batch是SELECT * FROM TEST

步骤六:查看TASK
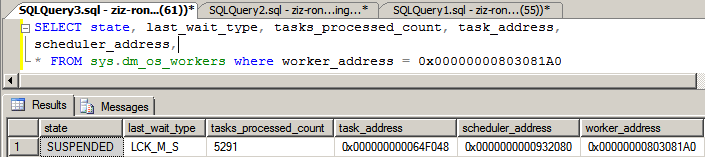
用下面的DMV, 我们可以看到,针对SESSION_ID=58的,只有一个task. (地址为0x0064F048), 而针对该TASK的worker地址为: 0x803081A0。同时我们也可以看到该worker运行在Scheduler 0上面。

步骤七:查看WORKER
从下面的查询可以知道,这个WORKER已经执行了5291个task了。这个worker相应的Scheduler地址是0x00932080
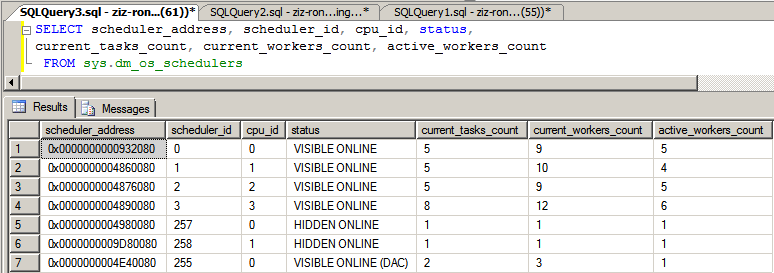
步骤八:查看SCHEDULER
从下面的查询可以得知,Scheduler_address (0x00932080) 相应的CPU_ID是0。在我们的系统上,有4个CPU, 编号分别为0, 1, 2, 3. 但是有7个SCHEDULER, 其中3个是SYSTEM SCHEDULER, 4个是USER SCHEDULER。在每个SCHEDULER上,有相应的WORKER数目。因为WORKER是根据需要而创建的,所以,在每个SCHEDULER上,目前WORKER数目很少。而且其中有些WORKER还处于SLEEPING状态。
【应用】
我们了解了SQL SERVER任务调度的机制,那么有些问题,就会更加清楚。
设置MAXDOP的作用。MAXDOP=1的话,可以使得一个BATCH只对应一个TASK。如果一个BATCH产生多个TASKS,那么TASK之间的协调,等待等等,将是很大的开销。把MAXDOP设小,能同时减少WORKER的使用量。所以,如果我们看到等待类型为CXPACKET的话,那么我们可以设置MAXDOP,减少并行度。
比较大的SPID。如果我们看到SPID的号码非常大,如超过1000, 那么通常表明,我们系统有很严重的BLOCKING。SQL SERVER不对连接数做限制,但是对于WORKER数,是有限制的。缺省情况下,最大个数如下:
Number of CPUs |
32bit |
64 bit |
<=4 processors |
256 |
512 |
8 processors |
288 |
576 |
16 processors |
352 |
704 |
32 processors |
480 |
960 |
对于很大的SPID编号,通常表明,我们的WORKER数是很高的。这种情况比较危险,如果一个新的连接进来,可能没有空闲WORKER来处理这个连接。在CLUSTER环境下,ISALIVE检查会失败,会导致SQL SERVER做FAILOVER。
NON-YIELDING SCHEDULER错误。我们有时候会看到SQL Server会报一个17883错误, NON-YIELDING SCHEDULER。这个错误指的是,在一个SCHEDULER上,会有多个WORKER,它们以友好的方式,互相占用一会儿SCHEDULER资源。某个WORKER占用SCHEDULER后,执行一段时间,会做YIELD,也就是退让,把SCHEDULER资源让出来,让其他WORKER去使用。如果某一个WORKER出于某种原因,不退让SCHEDULER资源,导致其他WORKER没有机会运行,这种现象叫NON-YIELDING SCHEDULER。出现这种情况,SQL SERVER有自动检测机制,会打一个DUMP出来。我们需要进一步分析DUMP为什么该WORKER不会YIELD。
WORKER 用完。我们可以做一个小实验。我们在一台32位机器上,创建上面提及的测试数据库,并且,开启一个同样的未关闭transaction的update语句。
然后执行下面的程序。下面的程序会开启256个连接到SQL Server, 这256个连接由于前面的transaction未闭合,都处于BLOCKING状态。
using System;
using System.Diagnostics;
namespace WORKER
{
class Program
{
static void Main(string[] args)
{
for(int i=0; i<256; i++)
{
OpenConnection();
}
}
static void OpenConnection()
{
ProcessStartInfo startInfo = new ProcessStartInfo();
startInfo.FileName = "sqlcmd.exe";
startInfo.Arguments = " -E -S SERVERNAME -d TEST -q \" SELECT * FROM TEST \"";
Process.Start(startInfo);
}
}
}
查询SELECT * FROM sys.dm_os_tasks这时候我们发现有278个TASK,而查询sys.dm_os_schedulers 我们发现有两个CPU, 因此有两个用户SCHEDULER, 每个SCHEDULER上,有128个workers. 加起来有256个WORKERS。针对两个CPU的架构,我们缺省最大的WORKER数是256。所以已经到了极限了。
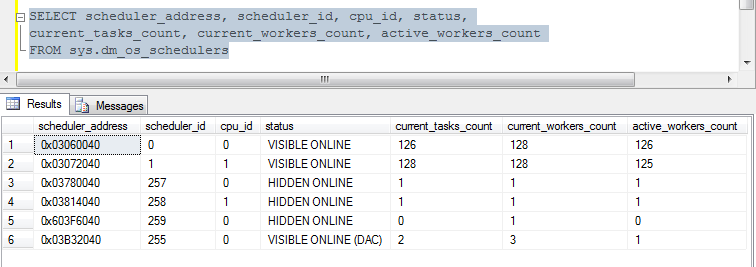
这时候,我们新开启一个连接,会发现SQL Server连不上,并报如下错误:

这是因为WORKER用完的缘故。新的连接无法获得一个WORKER来做login process。所以导致连接失败。在群集环境下,如果连接不上SQL Server, ISALIVE检查会失败,会引起SQL Server FAILOVER。所有的连接都会被强迫中止,并且SQL Server会在新结点上重新启动。针对这种情况,我们可以修改提高MAX WORKER THREAD,但是并不能最终解决问题,由于BLOCKING缘故,新的连接会迅速积累,一直把MAX WORKER THREAD用完,所以这时候,我们应该检查BLOCKING。使得task能及时完成,释放WORKER。
【总结】
SQL Server的任务调度使得SQL SERVER能够以最快方式处理用户发过来的请求。了解SQL SERVER的任务调度过程,对于我们调整系统性能是非常有帮助的。如适当增加MAX WORKER THREAD,调整MAXDOP,去除BLOCKING等等,了解这些概念,会使得我们的调整更有目的性。
Comments
- Anonymous
November 27, 2011
手绘的那个图非常给力,很受益。 - Anonymous
February 01, 2012
"。出现这种情况,SQL SERVER有自动检测机制,会打一个DUMP出来。我们需要进一步分析DUMP为什么该WORKER不会YIELD。" 能否提供一个例子来说明一下如何分析DUMP来找出NON-YIELDING SCHEDULER的原因。