Cloud computing guide for researchers - faster, better, more reproducible research
Wouldn't it be great if you had a time machine for your research? Or more realistically, access to all the computing and data capabilities you could ever wish for, right now? That's exactly what cloud computing can give you and it's a lot easier than you think. This blog series explains how cloud computing can help you do faster, better and more reproducible research, in any discipline, anywhere around the world.
A real problem for researchers is that computing and data requirements often change over the course of a project. Whether that is setting up an experiment, a complex set of simulations, or collecting and analysing data from a field study, what you initially design may not be what you end up using. When it comes down to it, eventually we must run some code, a processing pipeline, big data computation, or share our data and methods with the community. This is where access to computing and shareable data resources becomes critical, and a real bottleneck, depending on what is available to you on your desktop, at your university, or through a research centre. The Microsoft Azure for Research program can provide cloud computing for you to see how it can help your project.

What is cloud computing?
Cloud computing can be described in simple terms as on-demand access to near-infinite computing and data services, from anywhere on the internet. While this may seem like an over-simplification, this high-level view can help you make the best use of the cloud. It can provide everything for just about every researcher, with no waiting. Microsoft Azure, one of the world's biggest hyper-scale clouds, provides a vast collection of researcher-relevant services and capabilities that is increasing in scope every day. There is a particular focus on open-source solutions, including Linux, Python, Apache Spark, Kubernetes, and more. With so much choice, it can be difficult to know where to start. This series of blog articles aims to lead you through common ways that researchers around the world are using Azure today.
Microsoft Research has worked with hundreds of researchers in every discpline to explore how cloud computing can be best used. We see the following research scenarios over and over again, that cover most of the different situations researchers find themselves in:
Beyond the desktop. Would you be able to be more effective if you had a bigger desktop machine or access to a bigger server? Microsoft Azure provides a whole host of machine types that you can quickly create, install with all your own software and data, and be up and running in no time. For example, if you need a fast machine with lots of cores and memory, you can have it, say 16 cores and 224GB RAM. This is sometimes all that is needed to really speed up research. For example, Sandy Brownlee at the University of Stirling was looking at waiting several months to be able to process all of his research data, but by using Microsoft Azure he was able to do this in just a couple of weeks, as he explains, "One of the things cloud computing does is bring the power and data processing ability of huge machines to any researcher's desk". You can read about how Azure helped him here.

Computing at scale. You may want to run lots of computations, such as a parameter study or Monte-Carlo run. Running a high-performance computing simulation that needs high-bandwidth, low-latency (< 3 microsecond) supercomputer networking to scale to hundreds of cores is uniquely possible on Microsoft Azure. So you can have whatever cluster you want, lots of basic machines, or even true HPC with InfiniBand and GPUs. The big advantage is not having to wait in any queues – such as for science and engineering simulations. It's easy to deploy using our Azure Resource Manager templates, such as a SLURM cluster. You can find our detailed walkthrough for this here on Github. Read about how Simon O'Hanlon at Imperial College London was able to speed up his genomics research with Azure. Azure Batch is even more powerful, delivering a true HPC-as-a-Service model, where you can wrap your application with a simple template, and then run your HPC job without worrying about cluster management at all. You simply specify the job (e.g. input, output, number of cores), hit go, and get the results back. This is brilliant if you are running the same application over and over again, and gives you immediate access to a personal cluster, but without worrying about any cluster management.
Data science, big data and machine learning. The topic of data science encompasses a huge array of different ideas, approaches and technologies. Cloud computing is an ideal platform for exploring these, as it provides just about everything researchers need, hiding much of the complexity of setting up systems. Researchers at Cornell University found HDInsight (Hadoop/Spark/R/and more) on Azure ideal for analysing bird migration data as part of the eBird project. At the University of Oxford, Cortana Intelligence has allowed the REACH team to take their machine learning from the lab, and deploy at it scale easily to help provide water for thousands across Africa and Asia. This is one of the fastest moving areas of cloud computing, and Microsoft Azure has the latest open-source tools and technologies to make sure that you can have access to what you need, in an open way. A great example is our Jupyter notebooks on Azure, available as a service, fully executable, and shareable. These are a great way to do science in a reproducible way. You can start from scratch or upload your existing notebooks to Azure at https://notebooks.azure.com
Internet of Things. There is so much exciting IoT work being done, accelerated by the nexus of cheap and capable devices, connectivity, and cloud computing. Researchers often spend a lot of time figuring out how to deploy and manage devices, and gather data from them. This is a pre-requisite for many researchers, and Microsoft Azure provides an out-of-the-box solution for this called Azure IoT Suite.
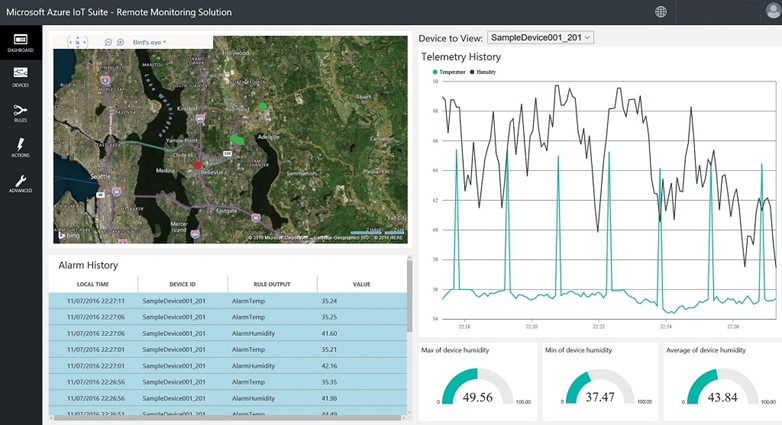
There is even a pre-configured remote monitoring solution that deploys an end-to-end system with a single mouse-click that is a great starting point for any IoT research project. The Azure IoT SDKs are open-source, and there are Arduino (SparkFun Thing, Feather M0, and Feather HUZZAH), Intel Edison, and Raspberry Pi-based Azure IoT hardware starter kits to get you started. The real value from IoT comes with making sense of the data, and that's where Azure Machine Learning and Stream Analytics come in. Feeding your IoT data into a data science pipeline, as described above, is where you can really make great strides with your research. Whether you're deploying sensors in the Brazilian rainforest, or on a linear accelerator, cloud computing means you can concentrate on your research.
Research data sharing and collaboration. Research is a collaborative endeavour, but it's not always easy to share data, workflows and software with others in the lab, research group, or around the world. Cloud computing makes this much easier, by being able to host data, workbooks, and computing together in one place. You can share as much data as you like, and it's as easy as using Azure Storage Explorer, Python, or command line tools, as explained in this video, and this detailed walkthrough on Github. Jupyter notebooks are one example of how collaborative open science is developing, with Azure providing executable Notebooks-as-a-Service for free. Azure provides the ideal platform for creating services that make research data and outputs easily available. Parker MacCready has used Azure to complement his university's Linux HPC cluster, by building a cloud system to manage his regional climate simulation output data, and make it available to other as part of the LiveOcean project. This is a great example of how Azure can be used to augment existing research projects for greater impact.

This blog series will tackle each one of these workloads in more detail, providing you with all the information you need to get started, and ramp up quickly.
How to plan for success?
Hopefully one of the scenarios outlined above fits what you are trying to do, so how do you get started? You can certainly dive in and gets your hands dirty, but it's good to step back a little bit to think about what you're trying to achieve before trying the first thing that comes to mind. Here are five questions to ask yourself, to get you thinking in the right direction, and help you navigate your journey with cloud computing. While you can get up and running very quickly, the following questions are good to think about upfront to help you plan where to go next, and who to talk to:
- What are you trying to achieve? This may sound like an obvious question, but it's good to set some targets for yourself so you can focus your efforts in the right direction. This could be as simple as getting a set of computations done as quickly as possible, or being able to share your results in a reproducible way with your community. The timescale and granularity is totally up to you, it could be next week, next year, or next decade. Try to identify where you want to get to. It's hard to get from A to B, if you don't know where or what B is!
- What does your ideal world look like? Once you've identified what you want to achieve, then it's good to imagine what a perfect world would look like. Don't think about how you do things today, what is available to you, or any other constraints (like funding!). This is about the art of the possible, not the impossible. Again, the level of detail is up to you. If you lived in this ideal world, what opportunities does it open? Often thinking like this can make you think in a different direction, being more ambitious about your research.
- Where are you today? Now you should have a good idea of what nirvana looks like. Time for a reality check! Try and map out how you currently do your work, paying attention to parts of your workflow that are slow or cumbersome. Identify problem areas, such as: computers that are not fast enough, don't have enough memory, or if you don't have enough of them; Spending too long waiting in queues to run on a cluster/supercomputer; not enough flexibility to deploy software on your cluster; hard to share data and workflows; complexity of deploying sensors and collecting data from them, and whatever else is relevant to you. Highlight items that are real blockers, and that if improved, could make a big difference to what you can do. For example, access to a machine with more memory (RAM) that would make data pre-processing orders of magnitude faster than you can do today (as your current computer must swap memory to disk). Think hard about what is working well for you. It's easy to take this for granted, so it is good to positively identify how you like to work now. This provides a good foundation and with templates for the future.
- What is your timeline and/or milestones? It is good to brainstorm and imagine what a better future might look like, but it is never going to happen unless there is a plan. Deadlines are good, as they provide focus and an incentive for progress. It is good to set small milestones and targets, so that you can measure how you are doing, and feel like you are indeed moving forwards! Don't expect to transform your research overnight. You should be able to make rapid progress, but take small steps first, and don't run until you're ready. By building a solid foundation of knowledge and skills around the cloud will mean you can take advantage of more advanced features more quickly. Remember, it's hard to ride a bike if you don't know how to stand up yet.
- What next? Once you've identified where you're trying to get to, where you are today, and what the steps to getting there are, then it's time to get started! Focus on one thing that will start you moving forwards. The hardest part is getting started, so don't wait. You'll be flying along before you know it.
What I've just described may seem ominous, but is something you can do in about ten minutes, at least to get the ball rolling. An example of a five-step plan for someone doing computational science might look something like this:
- What am I trying to achieve?
- Running a parameter sweep of my modelling code, where each model runs on a single core/machine.
- What does my ideal world look like?
- Ability to run all my models simultaneously on dozens of machines.
- Where am I today?
- I can run on my desktop machine, running two simulations at a time. This takes several weeks to complete one parameter study. Alternatively, I can use a high-performance computing cluster, but have to wait in a queue for several hours/days, and it is complex to use.
- What is my timeline?
- I have a paper deadline next month.
- What next?
- Setup an Azure virtual machine with 16 cores with my software running. Then scale up to several virtual machines, to complete all the computations for my paper over the weekend.
What next for faster, better, more reproducible research?
So you've thought about where you want to be, and have a plan to get there, what next? Well, start small, but aim to grow quickly. The cloud is a great playground for you to try things out – fast. Most of all, experiment and have fun!
To get you going here are some pointers for where to go next. This blog series will focus on the main research workloads, and do tell us about what you want to hear more about.
An interactive overview of all Microsoft Azure services is at https://azureplatform.azurewebsites.net/en-us/
Need access to Microsoft Azure?
There are several ways you can get access to Microsoft Azure for your research. Your university may already make Azure available to you, so first port of call is to speak to your research computing department. There are also other ways for you to start experimenting with the cloud:
- Several free services for you to explore:
- Sign-up to a one month free trial here

- Apply for an Azure for Research award. Microsoft Azure for Research awards offer large allocations of cloud computing for your research project, and already supports hundreds of researchers worldwide across all domains.