Azure HDInsight 3.6 - Five things that will make a data developer happy
Working with Hive, I regularly find myself staring at a csv/tsv/json files wondering where to start....
Hive View 2.0 is a new Web Experience in HDInsight 3.6 that greatly simplifies many common Hive Tasks and makes it easy to author and debug hive queries. In this post, we will look into 5 key feature that will tremendously simplify our lives
1 Create Hive table by uploading a file
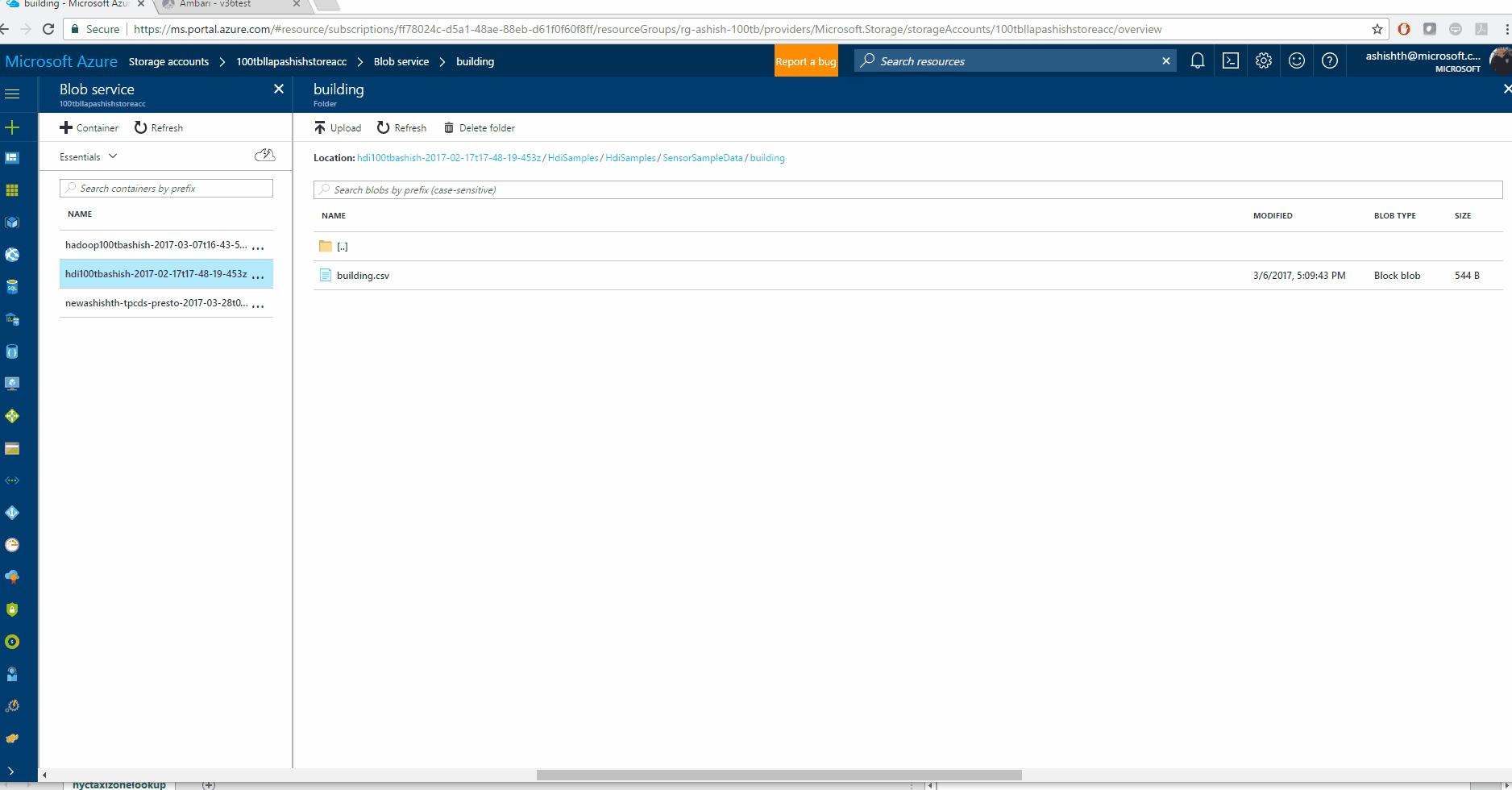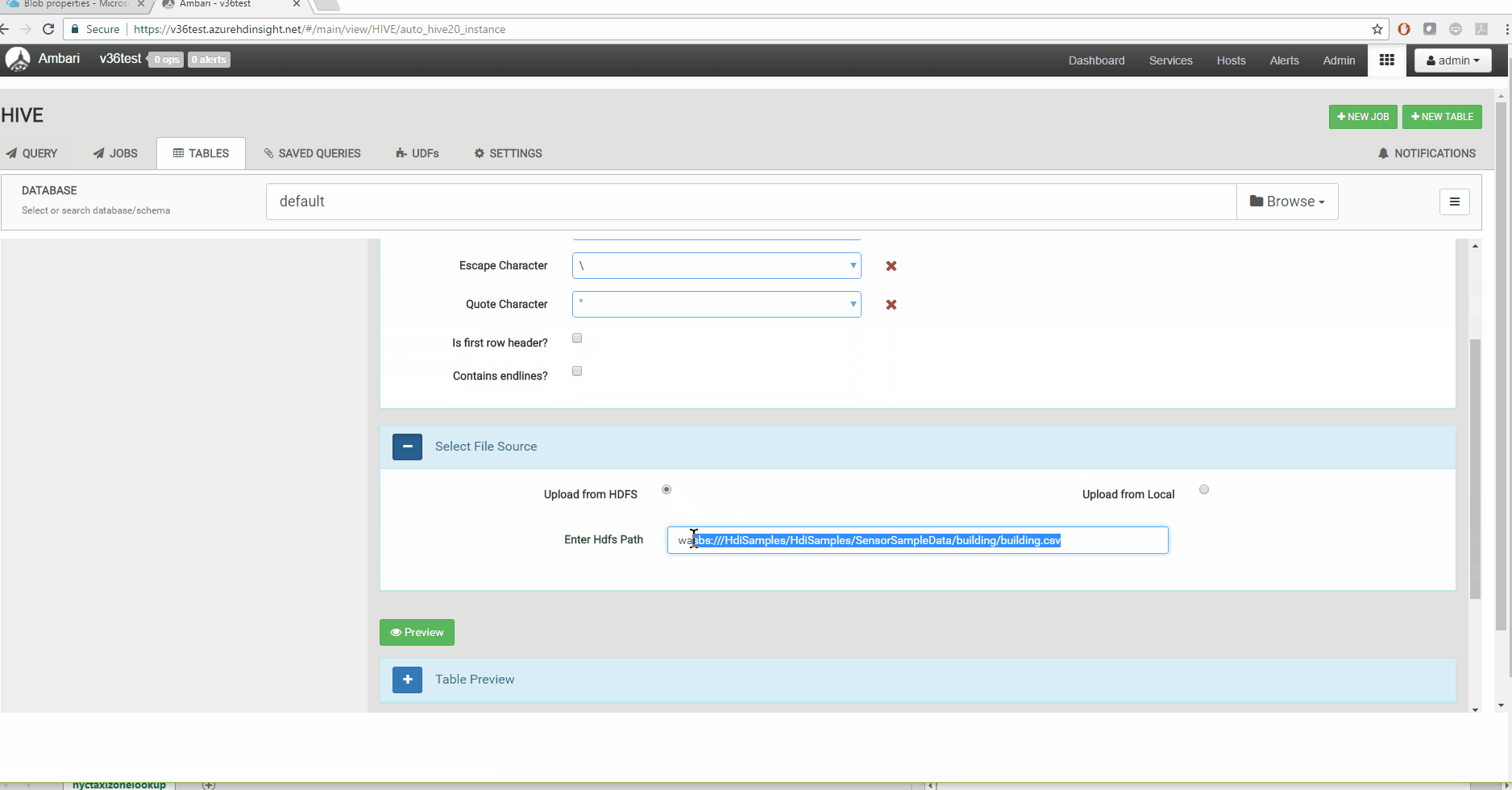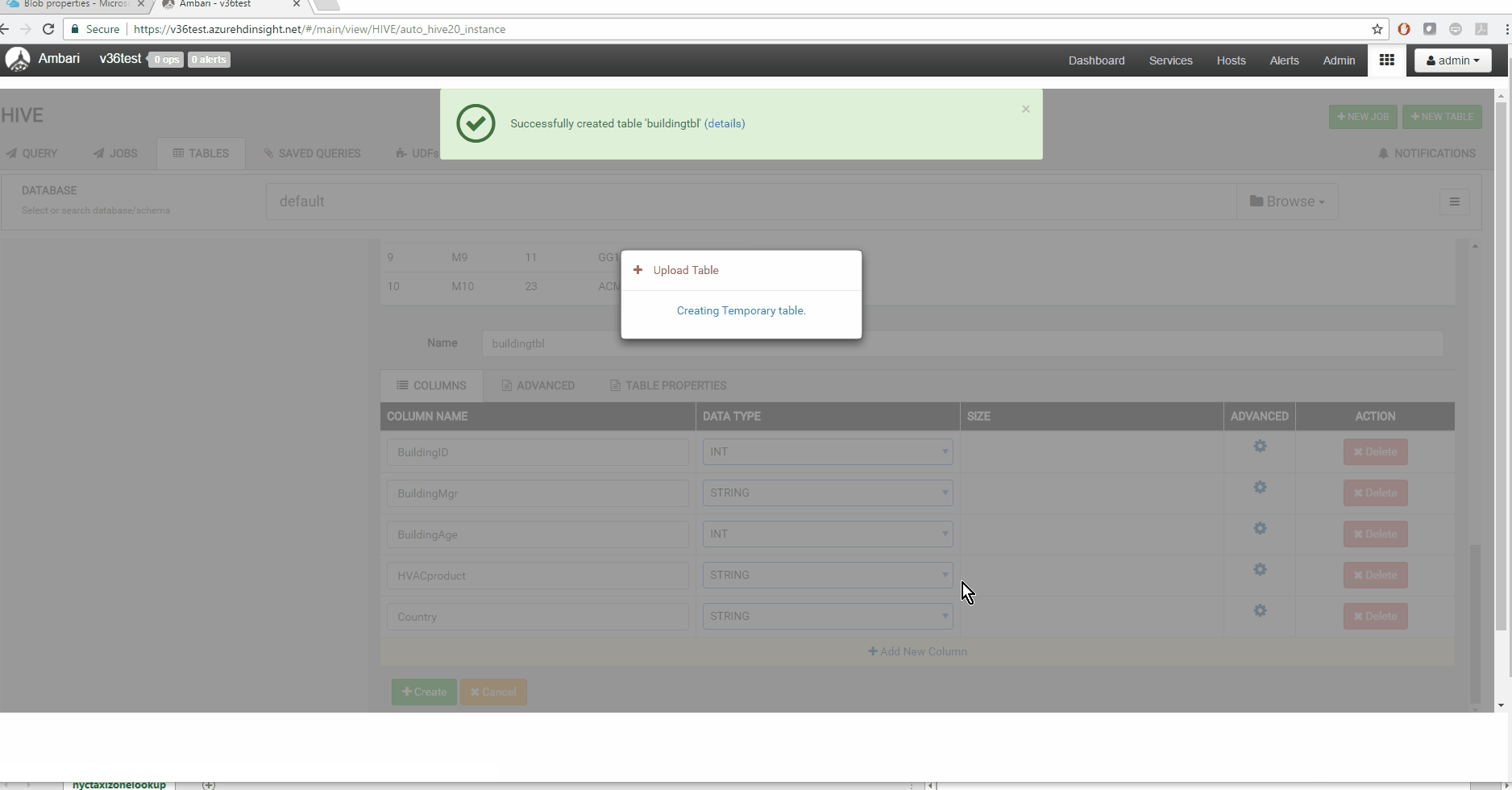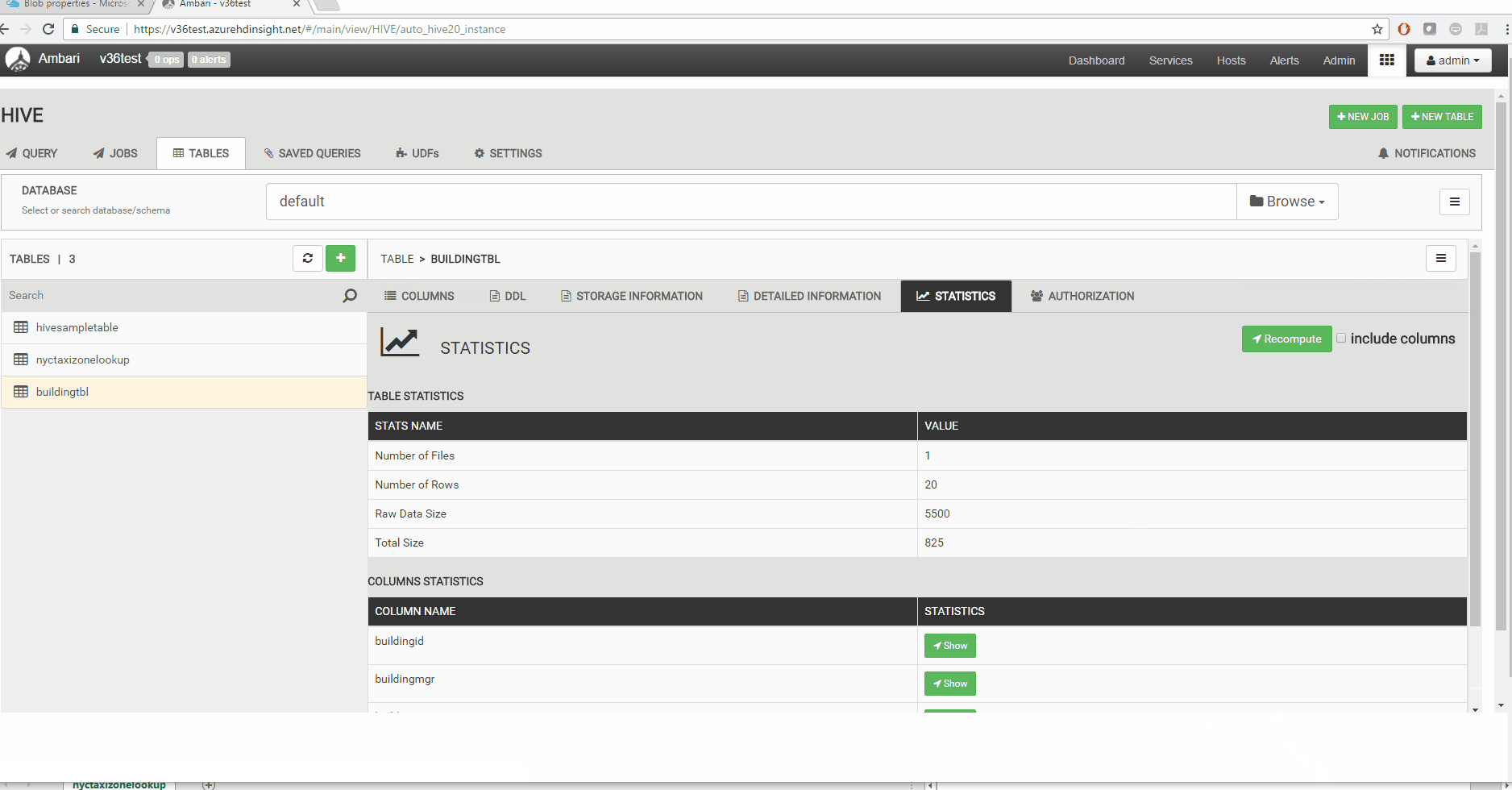
If you have a data file of the format CSV, JSON or XML, Upload table feature allows to create a table from the data file. To upload and create a table, click on Upload Table on create table wizard
- File can be uploaded from Azure Storage (WASB) or local machine accessing the view. For WASB, you can use wasbs protocol such as
wasbs:///HdiSamples/HdiSamples/SensorSampleData/building/building.csv - Choose file type and format according to the file being uploaded.
- If the first row of the CSV is a header row, check the ‘Is first row header?’ Checkbox.
- If needed, create a partitioned column or clustered column, using the gear icon against the column.
2 Create a new Hive table from scratch or alter Table
Create a new table by, clicking on the ‘+’ icon, which opens the create table wizard. Enter table name, column name and choose a data type from the dropdown. You can pick folloiwng advanced hive settings directly from the UI
- Transactional : Turn on transaction support in Hive, by checking this flag. Note that the table must be bucketed and stored using an ACID compliant format (such as ORC).
- Location : Hive stores the table data for managed tables in the Hive warehouse directory in HDFS which is configured in hive-site.xml with property hive.metastore.warehouse.dir. The default location is /apps/hive/warehouse. The location can be changed using the Location text field.
- File Format : The default file format for CREATE TABLE statement is ORC. choose a format from the file format dropdown.
- Row Format : Select a row format such as Field terminator, Lines terminator, and Stored File type.
- Table can be altered to add new columns or change the column name or column datatype.
- Tables can also be renames and altred
3 Query editor that auto completes
HiveQL authoring experience is much better with autocompleter. It will suggest keywords, functions, etc. which is very handy. 
4 Visual Explain
Hive View 2.0 has much improved visual explain that will let you view query execution in Hive. 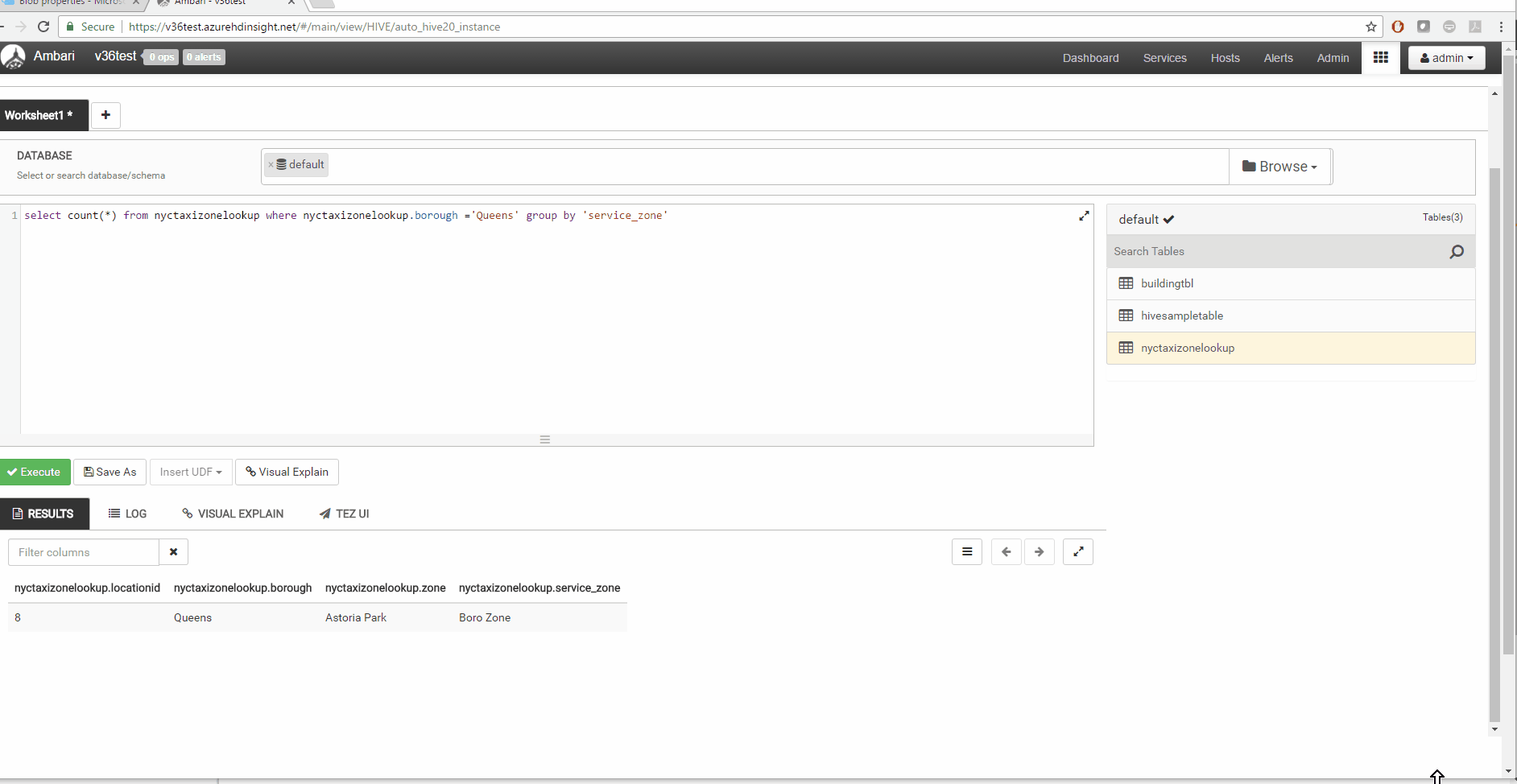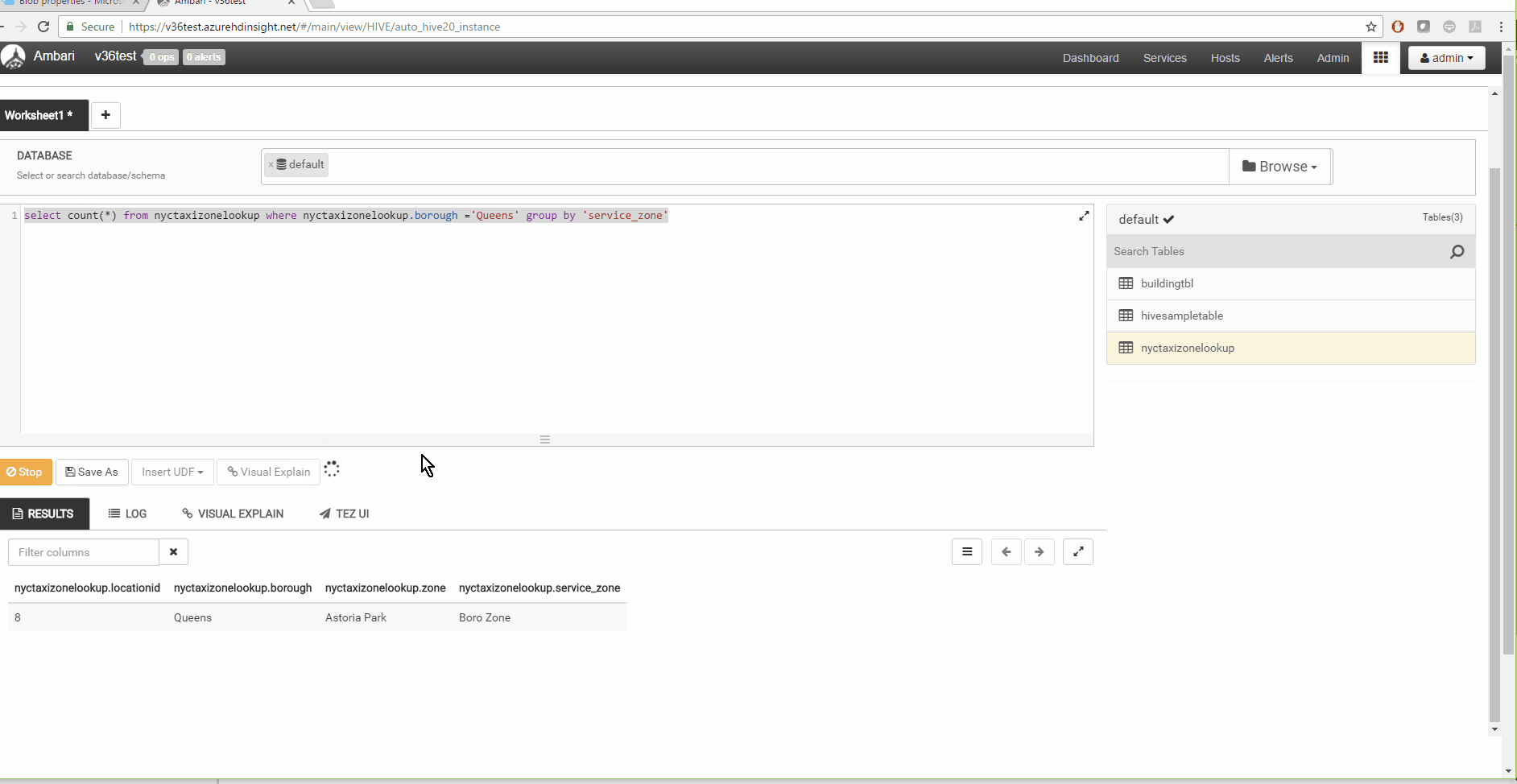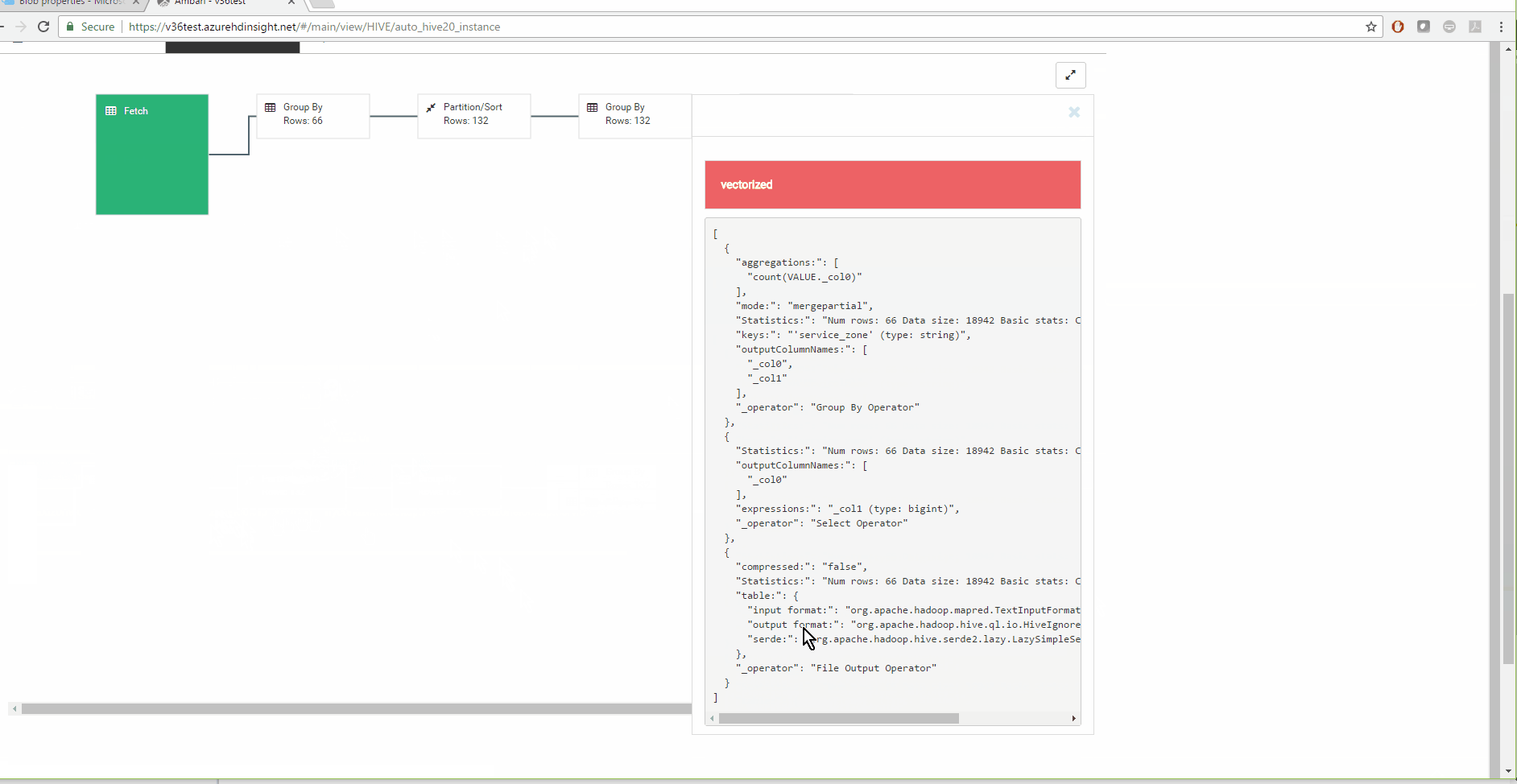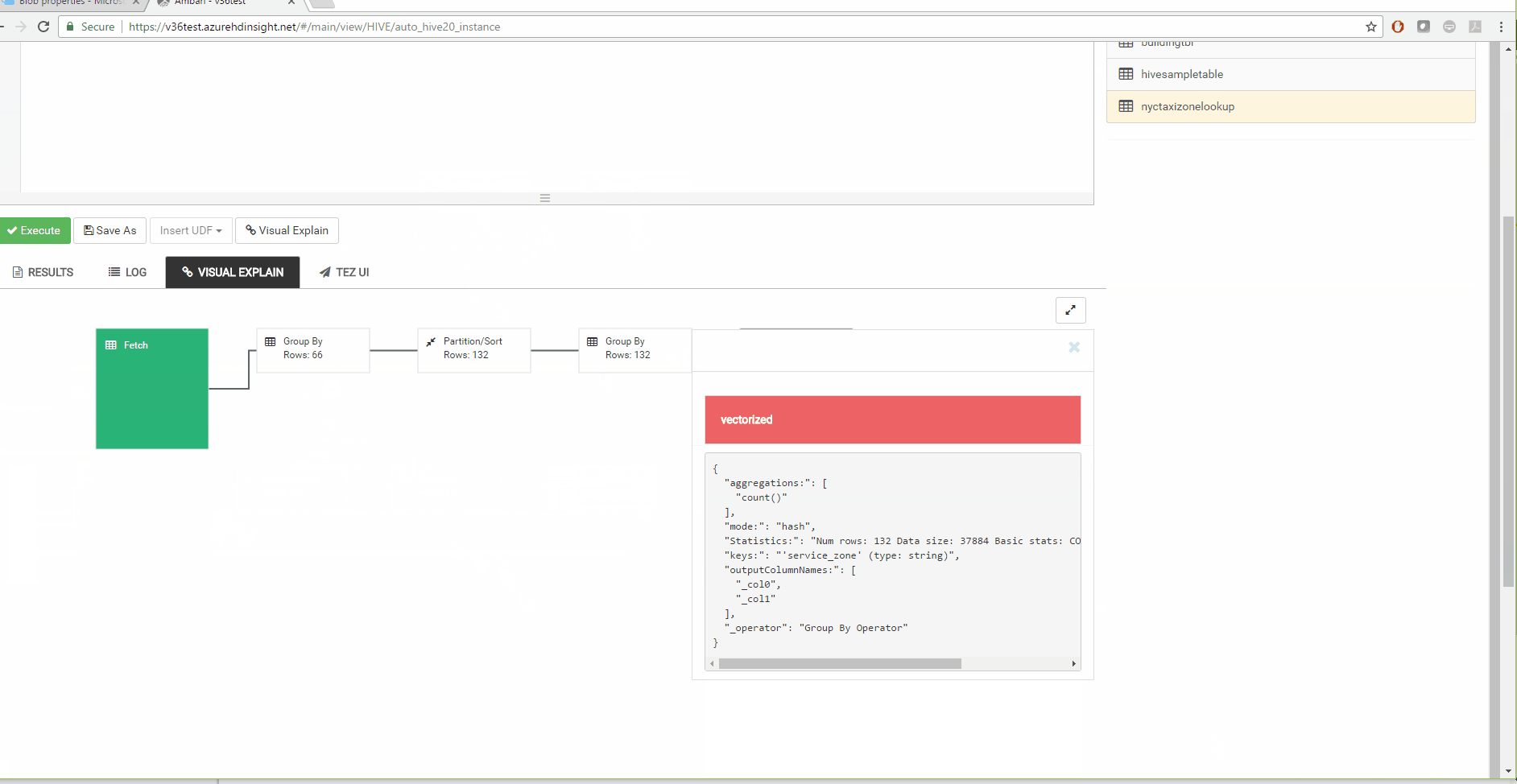
5 Improved Tez View
Apache Hive and Pig use the Tez framework. When you run a job such as a Hive query or Pig script using Tez, you can use the Tez View to track and debug the execution of that job. HDInsight 3.6 includes much improved TezView. It will help you quickly debug your queries and find bottlenecks.
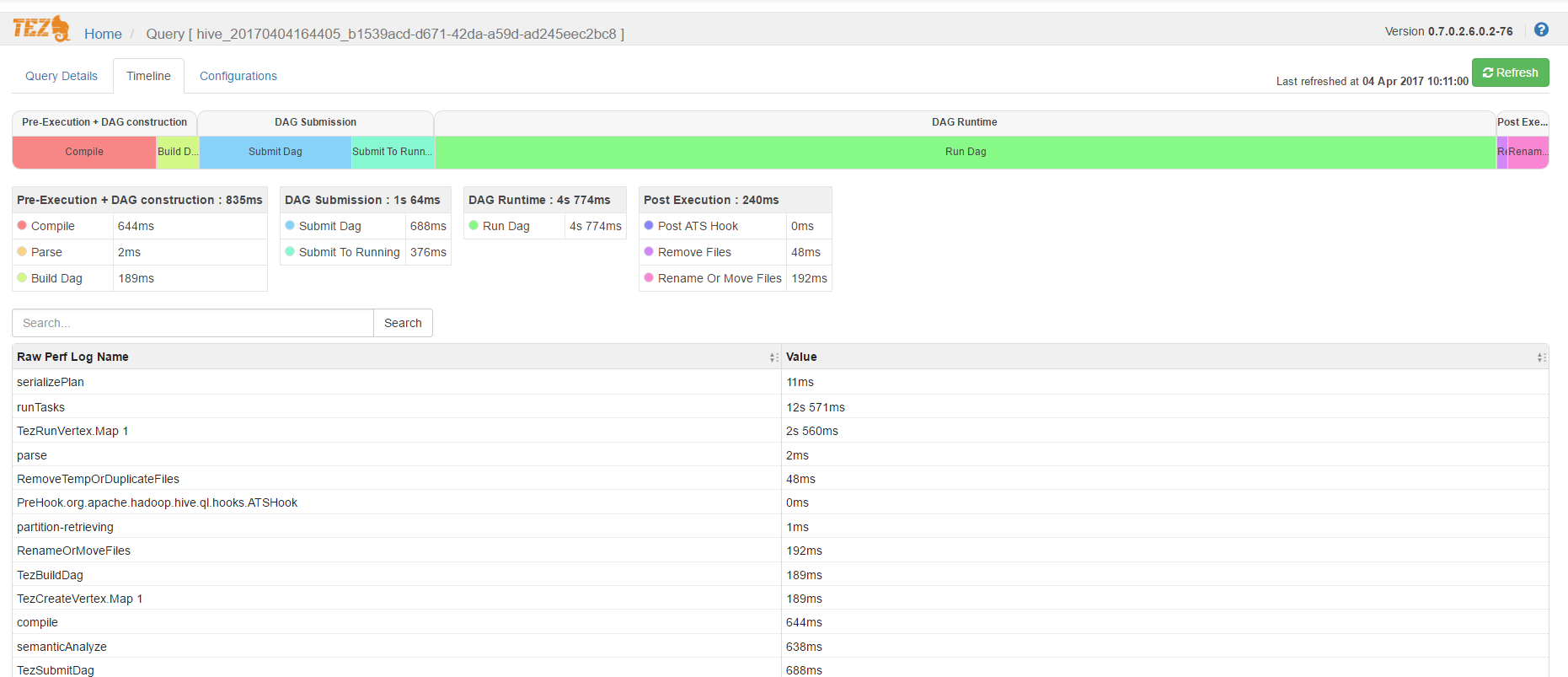
These features greatly enhance the productivity of a Data Developer /Engineer.