Building advanced analytical solutions faster using Dataiku DSS on HDInsight
The Azure HDInsight Application Platform allows users to use applications that span a variety of use cases like data ingestion, data preparation, data processing, building analytical solutions and data visualization. In this post we will see how DSS (Data Science Studio) from Dataiku can help a user build a predictive machine learning model to analyze movie sentiment on twitter.
To know more about DSS integration with HDInsight, register for the webinar featuring Jed Dougherty from Dataiku and Pranav Rastogi from Microsoft.
DSS on HDInsight
By installing the DSS application on a HDInsight cluster (Hadoop or Spark), the user has the ability to:
- Automate data flows
DSS has the ability to integrate with multiple data connectors. Users can connect to their existing infrastructure to consume their data. Data can be cleaned, merged and enriched by creating reusable workflows.
- Use a collaborative platform
One of the highlights in DSS is to be able to collaboratively work on building an analytics solution. Data Scientists/Analysts can interact with developers to build solutions and improve results. DSS supports a wide variety of technologies like R, MapReduce, Spark etc.
- Build prediction models
Another key feature in DSS is the ability to build predictive models leveraging the latest machine learning technologies. The models can be trained using various algorithms and applied existing flows to predict or cluster information.
- Work using an integrated UI
DSS offers an integrated UI where you can visualize all the data transforms. Users can create interactive dashboards and share it with other members in the team.
Leverage the power of Azure HDInsight
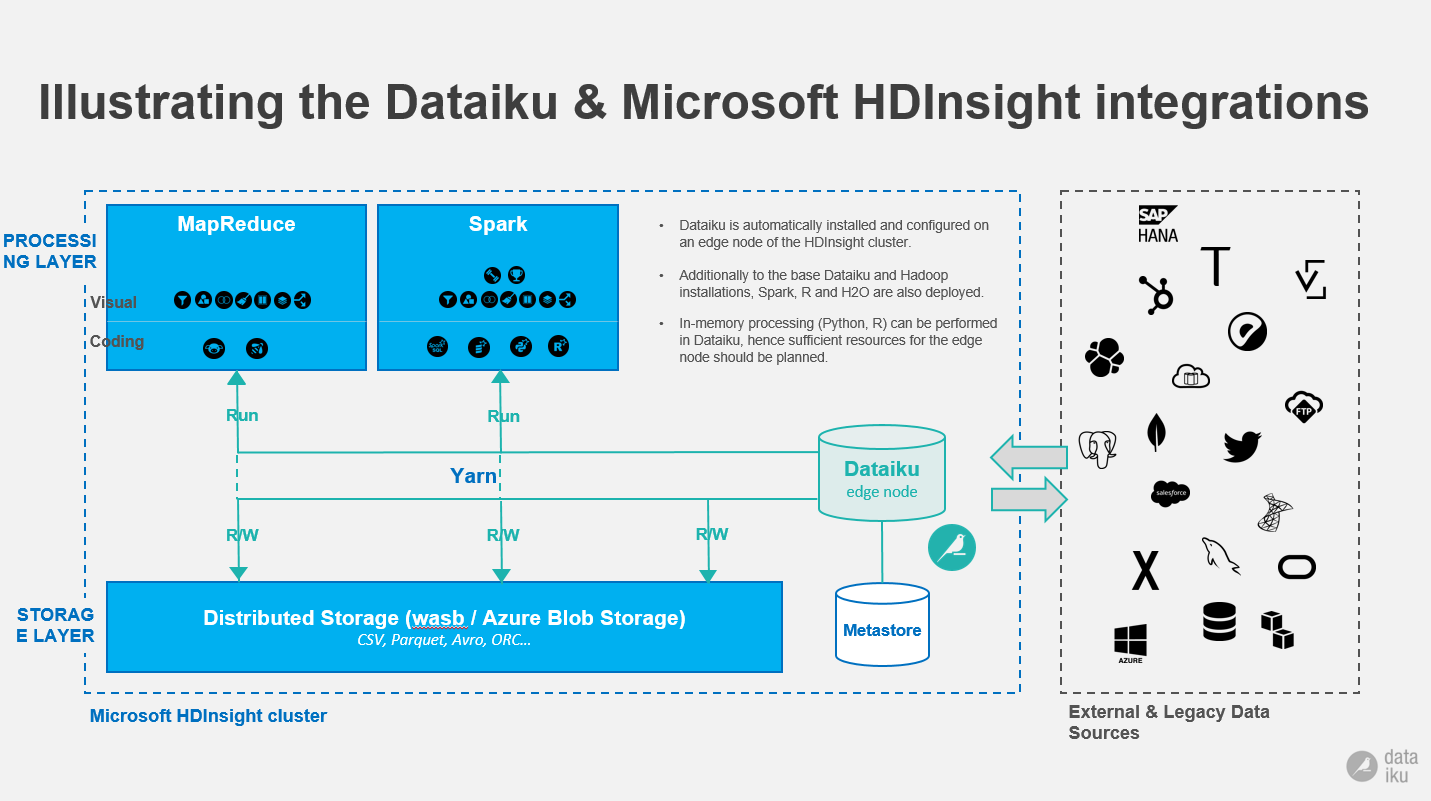
DSS can leverage the benefits of the HDInsight platform like enterprise security, monitoring, SLA and more. DSS users can leverage the power of MapReduce and Spark to perform advanced analytics on their data. DSS offers various mechanisms to train the in-built ML algorithms when the data is stored in HDInsight. The below diagram illustrates how the HDInsight cluster is utilized by DSS (Note: Integration with Azure blob storage is available in DSS 4.0) :
How to install DSS on an HDInsight cluster?
DSS is an application available to install on Linux clusters of Spark or Hadoop type with HDI Versions starting from 3.4. The application can be configured to install during cluster create or added onto an existing compatible cluster.
Install DSS on a new HDInsight cluster:
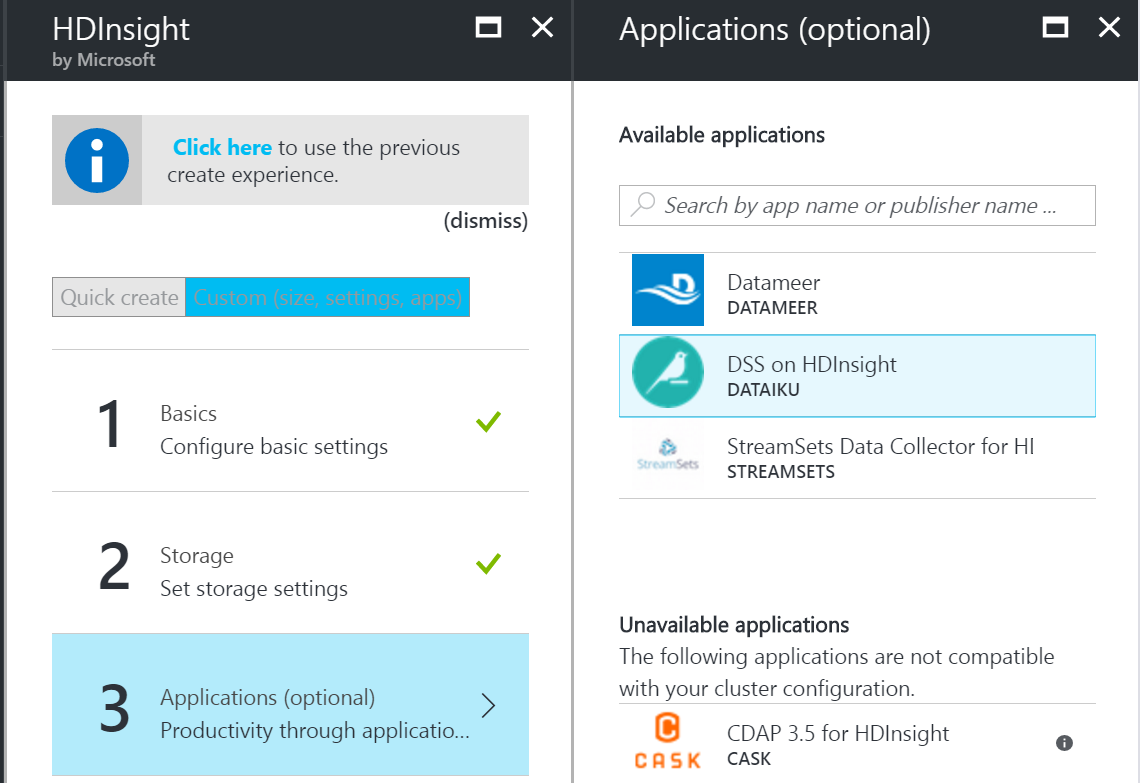
- Navigate to the Azure management portal and choose the option to create a new HDInsight cluster using the Custom Create option. Choose the Operating System to be ‘Linux’, Cluster type to be 'Hadoop' or 'Spark' , and HDI Version to be ‘3.4’ or '3.5' .
- On the step to install applications select ‘DSS‘ from the list and accept the legal terms.
Install DSS on an existing cluster:
- Navigate to your existing Hadoop/Spark cluster on the azure portal and click on ‘Applications’ pane.
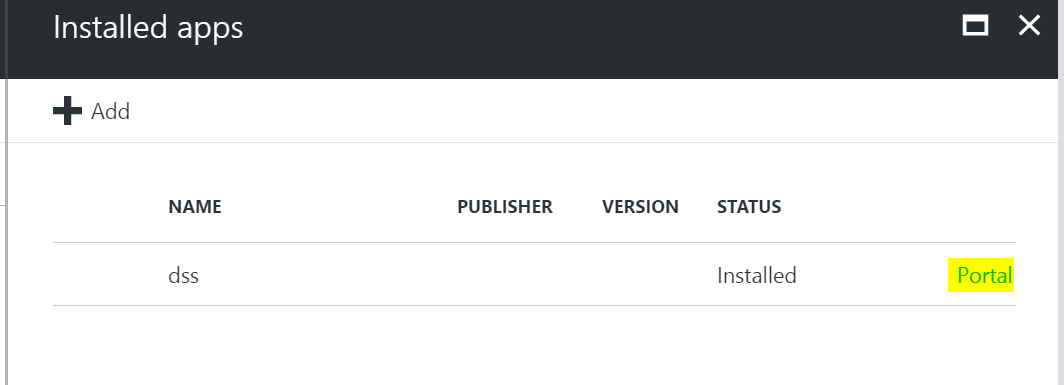
2. You will see the applications pane open which shows a list of installed applications on the cluster. Click on the ‘Add’ button to show a list of applications which can be installed on this cluster. Select DSS and accept the legal terms.
Using the DSS application
- Once the application has been installed successfully using the above steps, click on the ‘Portal’ link that appears next to DSS in the applications pane to bring up the DSS portal.
2. You will be navigated to the DSS site and prompted to enter credentials. Enter the cluster login username and password that you had configured while creating the cluster.
3. In the DSS website, you will see the Dataiku login page. You can sign up for the Enterprise edition (which is free for 15 days) or use the Community Edition to get started. (The default login username and password is 'admin' until you change it)

Analyze movie sentiment on twitter using DSS
This tutorial shows you how you can easily build an analytics solution to determine the sentiment of a movie based on its tweets. You can follow this to create a DSS flow which has the following components:
- A Twitter data streamer to stream and store relevant tweets in real-time
- An analysis model which is trained using an existing twitter corpus dataset to predict sentiment
- A sentiment predictor which can be applied on the incoming tweets
Let us examine how we can build the above components.
- To start off, create a new project in your DSS portal
- Setup the twitter data streamer:
- In your project, navigate to the datasets icon (top left) and create a new twitter dataset.
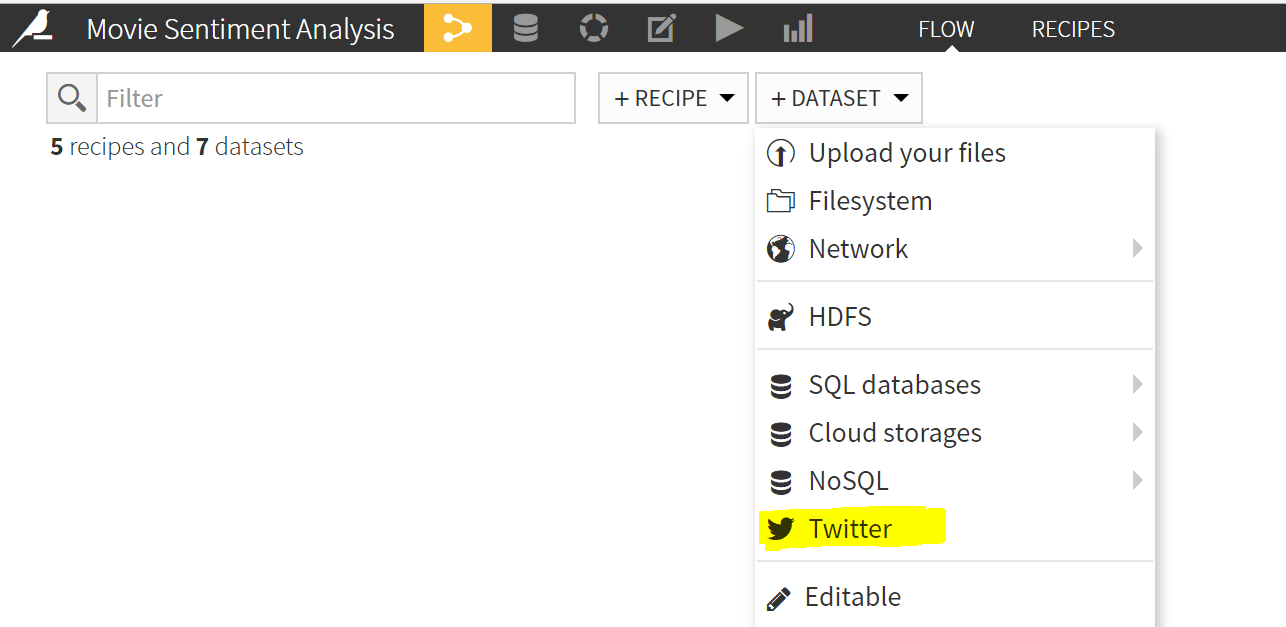
- Setup a twitter connection by inputting the Consumer Key/Secret along with the Access token/secret obtained from your twitter application (https://apps.twitter.com). Create and save this connection.
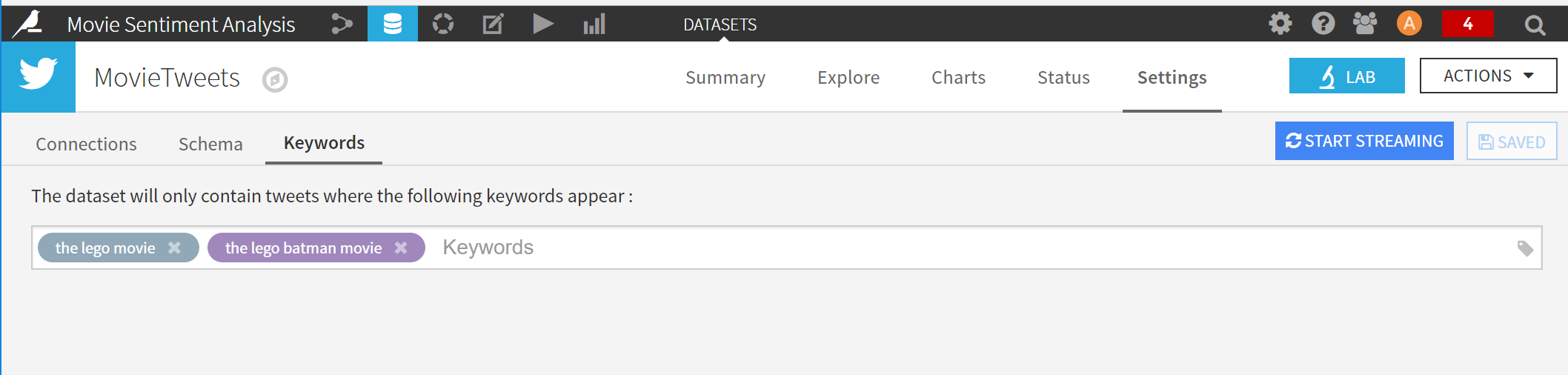
- Choose the above Connection from your twitter dataset. Navigate to the ‘Keywords’ tab and add the required keywords here. In this tutorial, we're going to filter all the tweets for the 'The Lego Batman movie' and find out how folks on twitter are talking about this movie. Click on the “START STREAMING” button on the top right to stream related tweets.
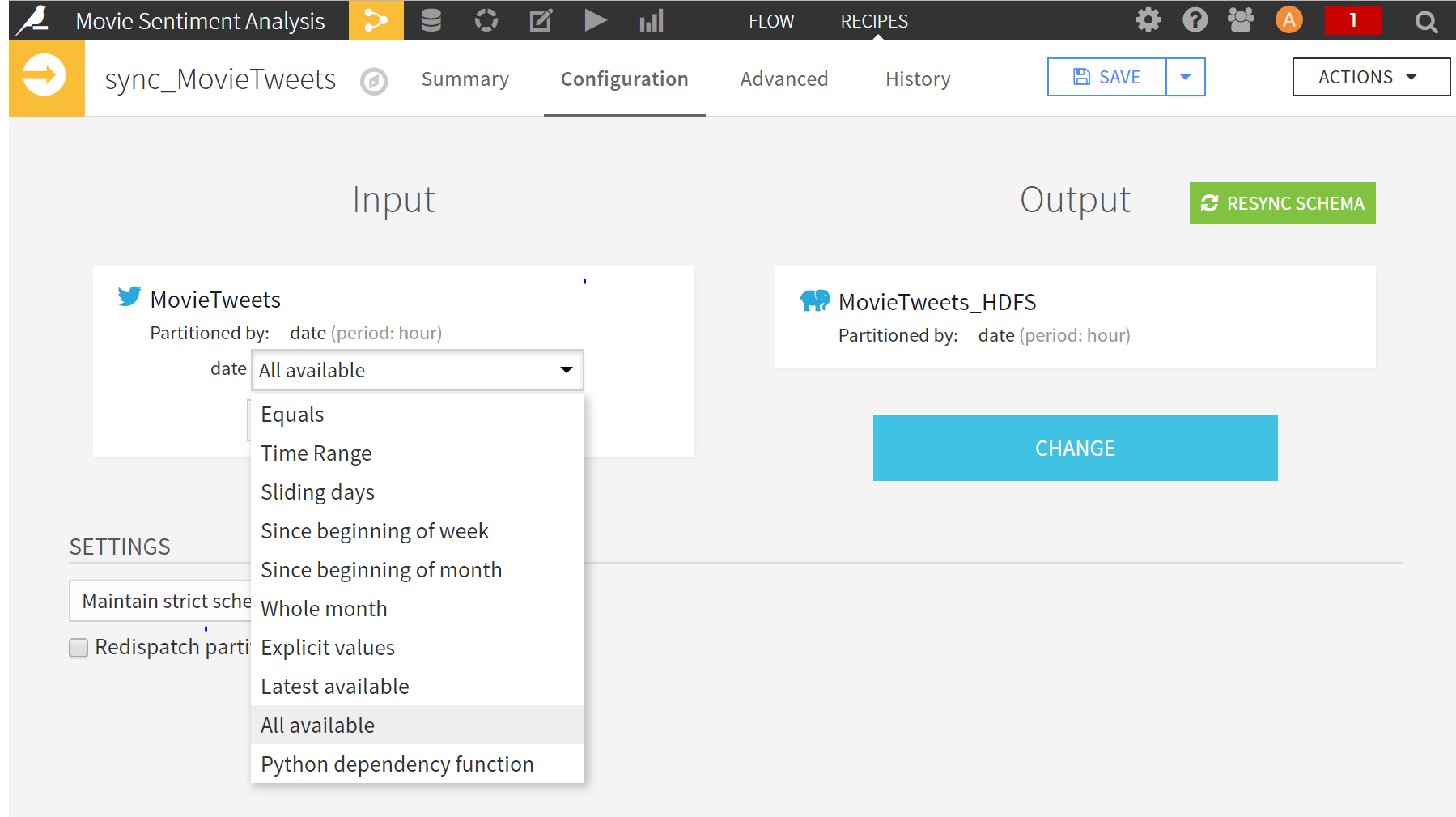
- The incoming tweets will be stored into the default file system. Next, add a Sync recipe to the twitter dataset to store the streamed tweets in HDFS which will enable us to use Map-Reduce/Spark functionality later on. Choose the job to output data into HDFS. Once you create the recipe, change the partitioning scheme to be partitioned by “All Available”.
{kind=link}
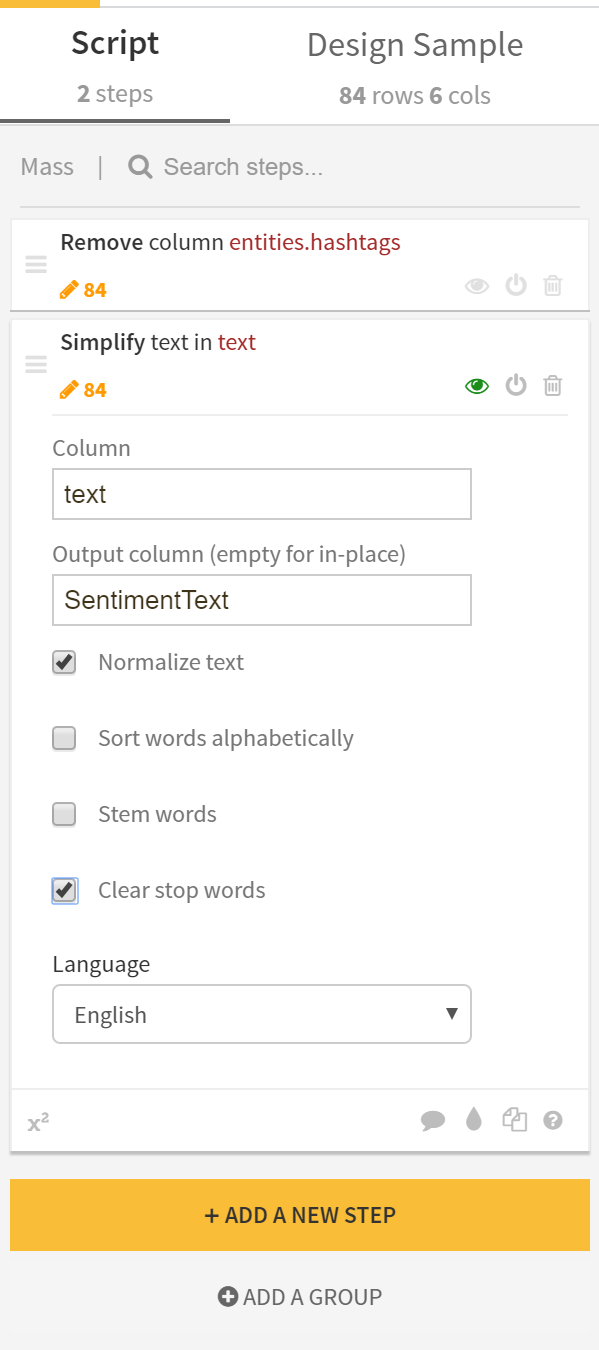
- Add a data preparation recipe to clean out redundant information and convert the tweets into a format which is makes it easy to analyze their sentiment. For the purposes of this tutorial, the cleansing steps include the process to normalize tweets and store them in a different column called SentimentText (which is to be used as input for the Sentiment Analyser). There are a wide variety of processor steps present in the preparation tool including data cleaning, geo-enrichment, mathematical transformations etc. Here you can also write python code to filter or transform output, if required.
- The next series of steps describe how you can build an analysis model to predict the sentiment of the tweets.
- First you would need to import a Twitter corpus that has a large number of tweets along with their corresponding sentiment which can be used to train the prediction model. For the purpose of this tutorial, the Twitter Sentiment Analysis Dataset was used.
- Once you have imported the data, click on the LAB icon on the top-right in the dataset window to create a Visual Analysis of the data. In this mode, you can also additionally prepare the data, if required, by removing unnecessary columns.
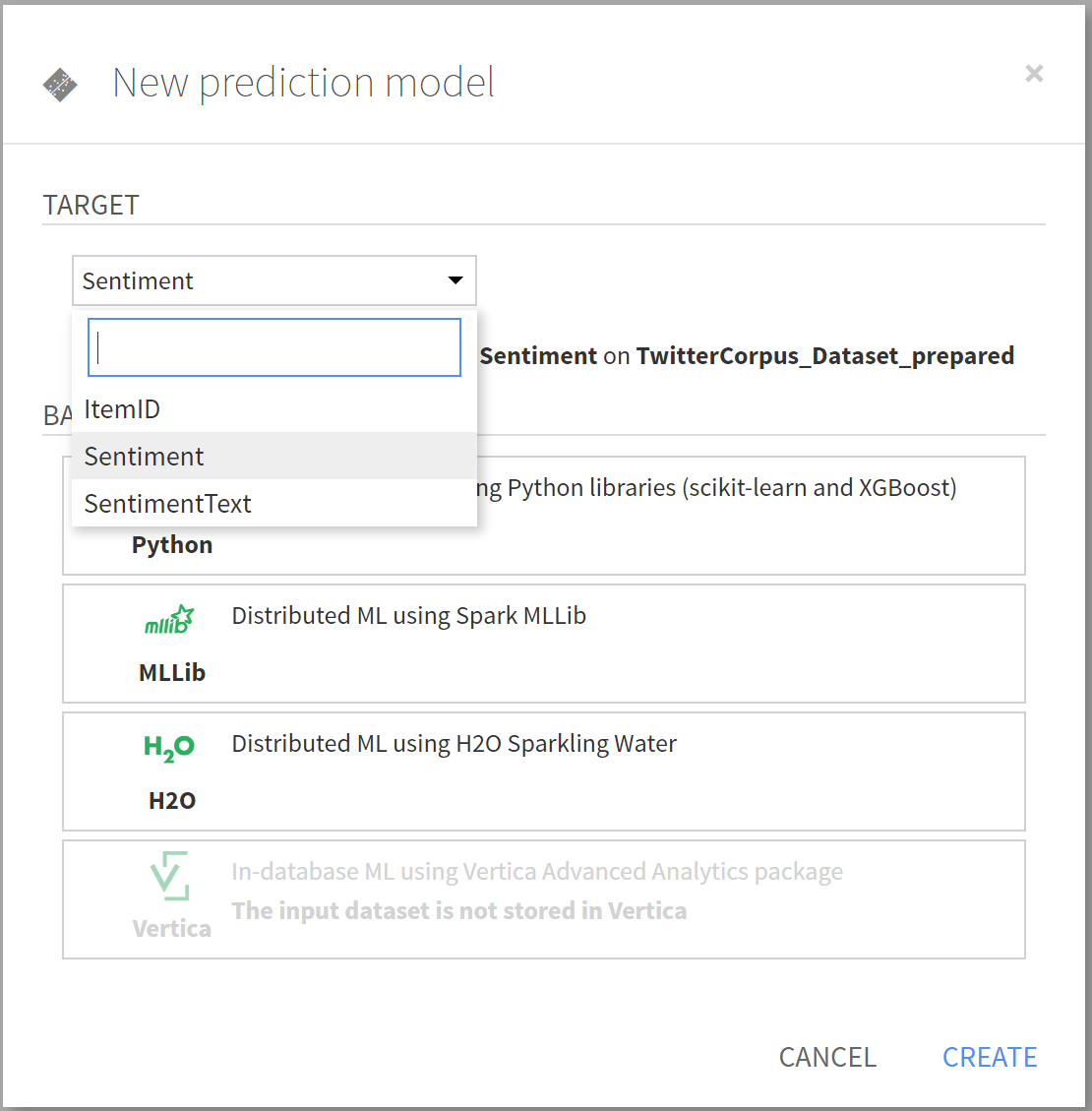
- After that click on the Models tab and create a new prediction model. You need to train the model to predict sentiment based on the sentiment text. Choose the target as Sentiment and the back-end prediction technology to be Python (You also have the option to choose MLLib and H2O here but the data might need additional preparation).
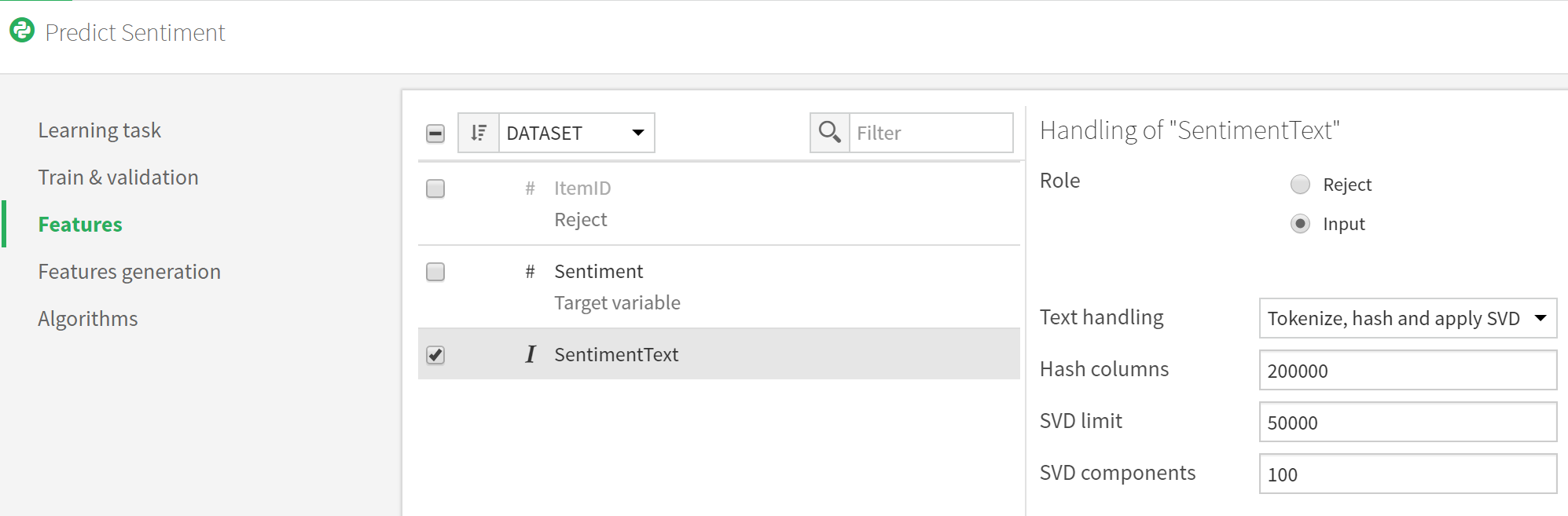
- Once the model is created, before clicking on TRAIN, go to its settings and change the role of SentimentText to be Input (DSS ignores text by default). You can also change other aspects of the algorithm here and choose the ML algorithms that are used for the training (Logistic Regression, Random Forest, etc)
- Once you get the results of the training for each of the algorithm, evaluate each of them to see which one has the best performance. You can tweak the individual aspects of each algorithm and re-train to get a better performance.
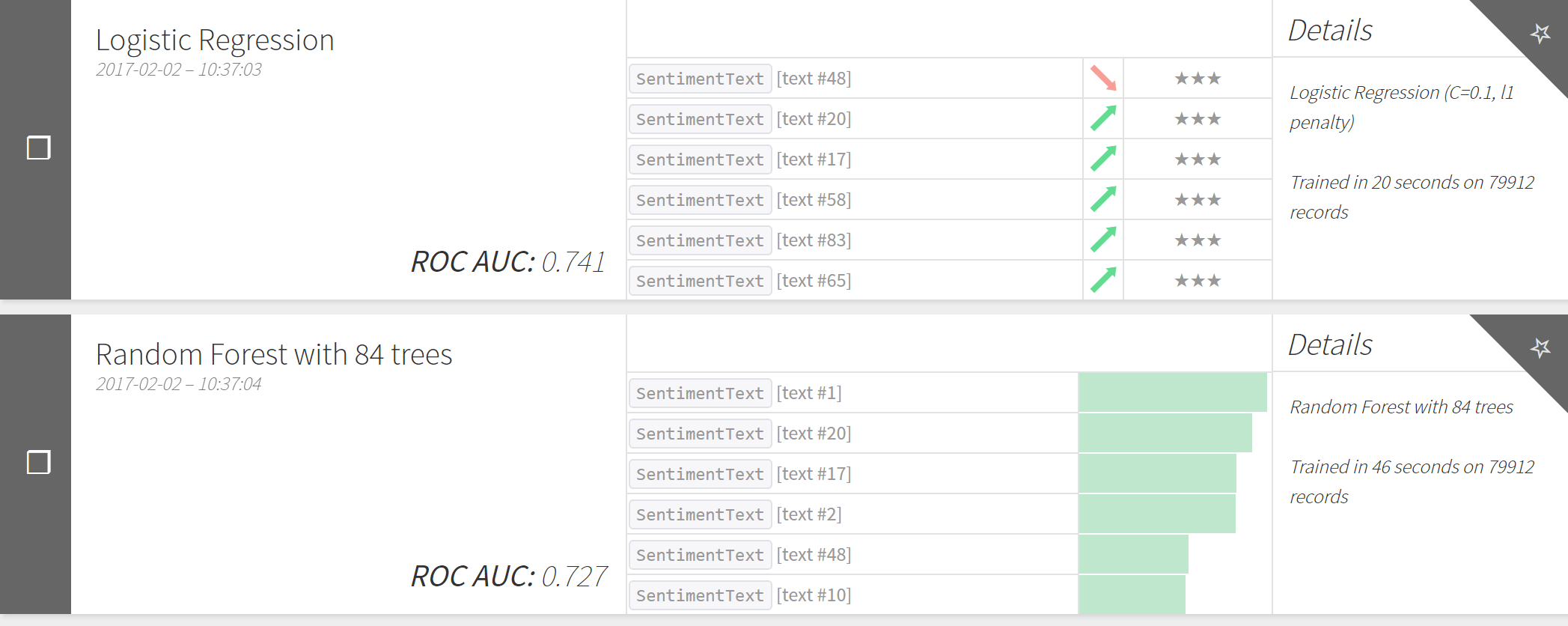
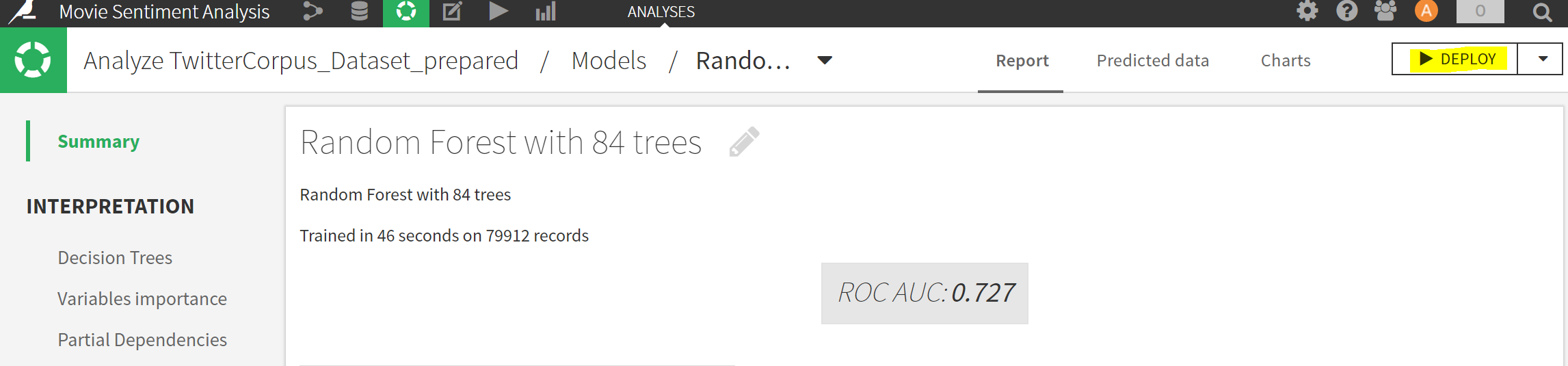
7. Deploy the algorithm with the best performance by clicking on the DEPLOY button on the top-right in the selected algorithm.
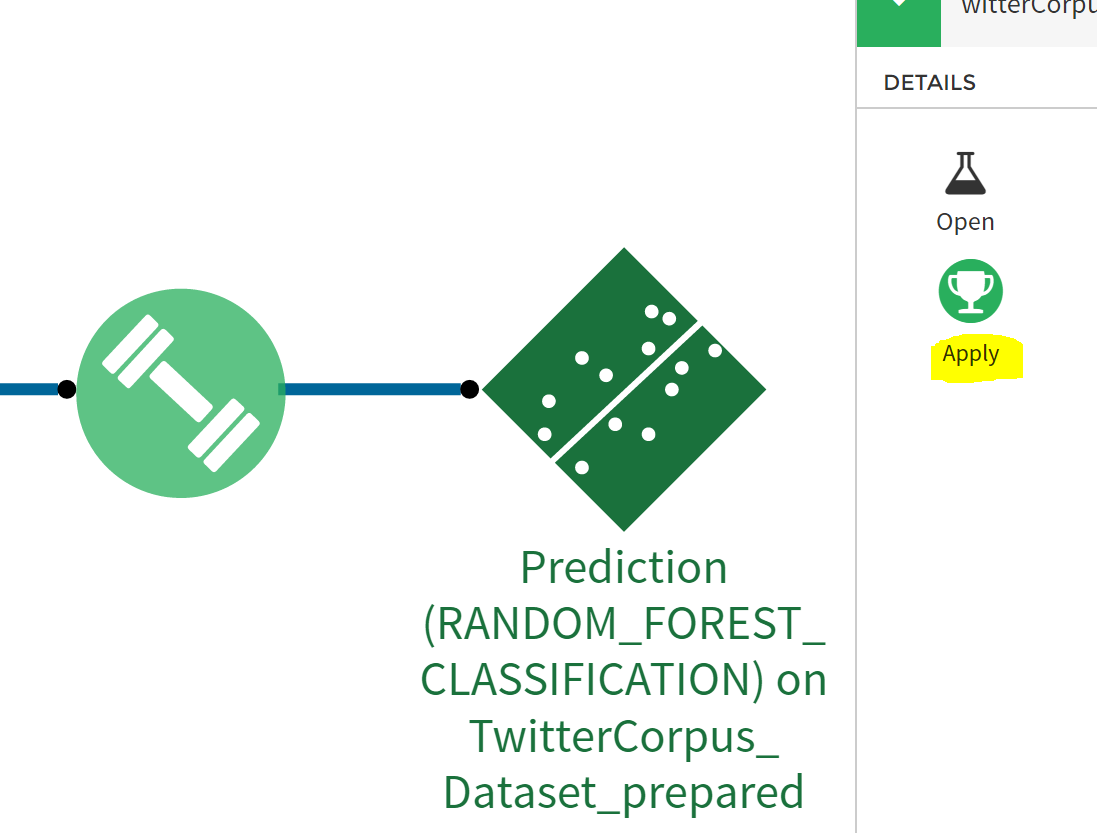
- Once the model is deployed, it can be applied to the twitter dataset to predict the sentiment of the tweets. Click on the model in the flow and choose APPLY on the right pane.
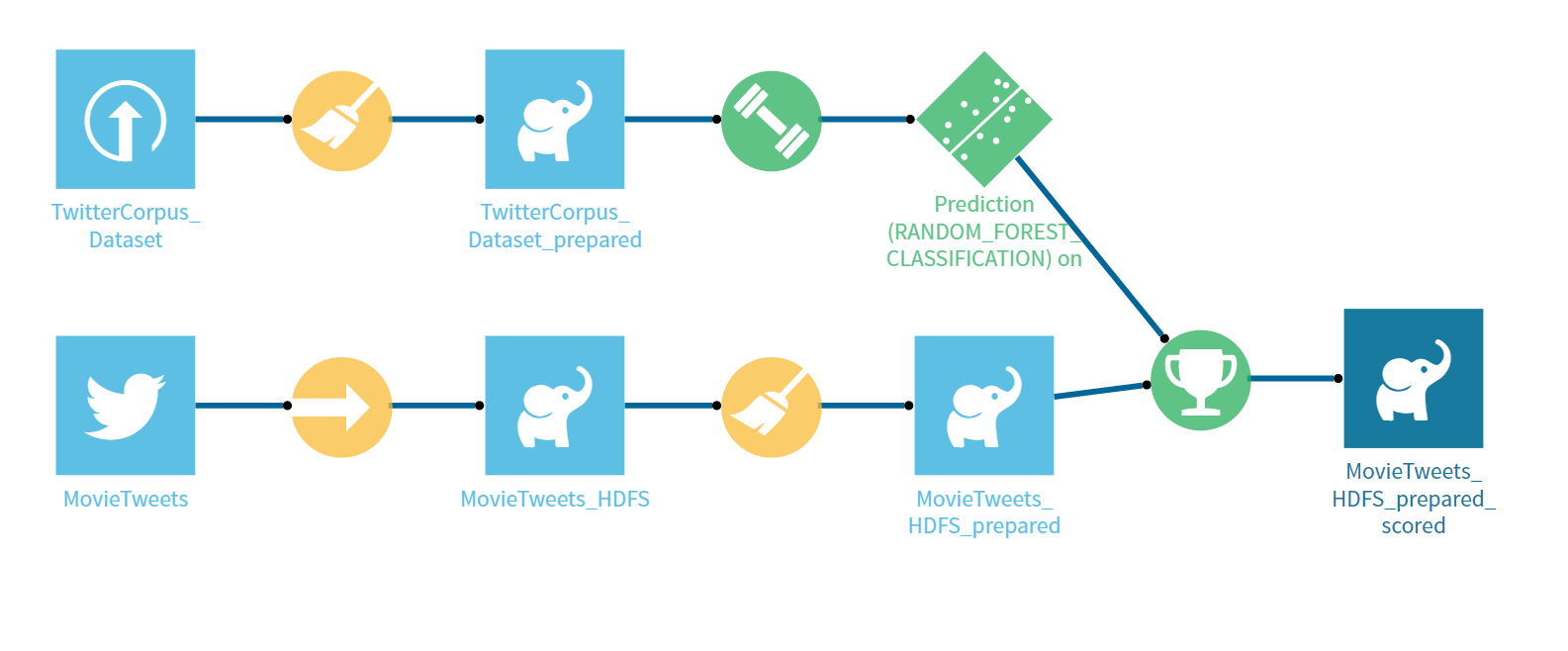
9. Choose the prepared twitter dataset as the input and create a new recipe. Run this model to generate the prediction for the twitter dataset. In the end, your entire flow would look something like below. Run the recipe and generate the scored results.
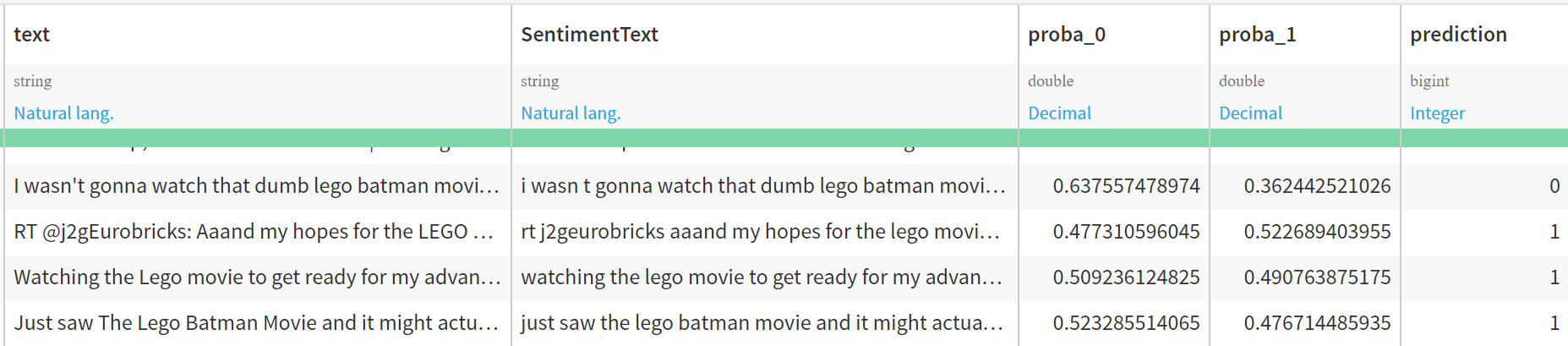
- Explore the scored results after building all the datasets. In this example, we can see that the Lego movie has an overwhelmingly positive sentiment and is likely to be a boxoffice hit! (Note that the corpus chosen here is slightly biased towards the positive side and neutral-seeming tweets are likely to be categorized as ones with a positive sentiment). Create dashboards to represent this data. You can pivot by different parameters here and generate different views.
As you learnt in this tutorial, it is quite simple to build a solution for predicting movie sentiment using DSS on HDInsight. DSS offers many more capabilities which would make building advanced analytical solutions a lot easier. Check out this integration here.
To know more about DSS integration with HDInsight, register for the webinar featuring Jed Dougherty from Dataiku and Pranav Rastogi from Microsoft.