HDFS gets full in Azure HDInsight with many Hive temporary files
Sometimes when Hive is using temporary files, and a VM is restarted in an HDInsight cluster in Microsoft Azure, then those files can become orphaned and consume space.
In Azure HDInsight, those temp files live in the HDFS file system, which is distributed across the local disks in the worker nodes. This is a different location than where user data is stored in HDInsight, since user data will be kept in Azure Blob Storage or Azure Data Lake Store when using HDInsight. The local disk and HDFS is not used for user data files by default and only the temporary files for Hive are kept there.
In the Hive-site.xml, this is the property that controls the location of the temporary files:
<property>
<name>hive.exec.scratchdir</name>
<value>hdfs://mycluster/tmp/hive</value>
</property>
Step 1. Checking Disk space
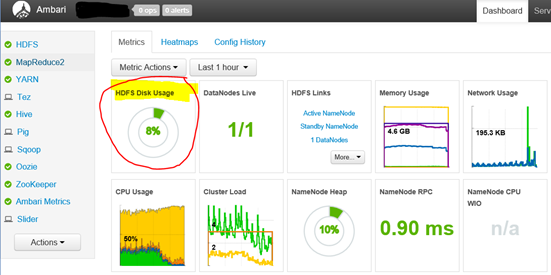
A> Ambari dashboard shows an HDFS usage percentage in the dashboard.
This is the HDFS file system spread across a number of worker nodes on local disk.
From the Azure portal, it should direct you to the URL such as https://yourhdinsightname.azurehdinsight.net/
Ambari should log this kind of text in its metrics collector "/var/log/ambari-metrics-collector/ambari-metrics-collector.log"
- 2016-08-15 20:01:44,739 [WARNING] [HDFS] [namenode_hdfs_capacity_utilization] (HDFS Capacity Utilization) Capacity Used:[82%, 301787316224], Capacity Remaining:[68437065728]
- 2016-08-15 20:01:47,317 [WARNING] [HDFS] [datanode_storage] (DataNode Storage) Remaining Capacity:[29831340032], Total Capacity:[86% Used, 210168897536]
B> To see how much local disk space on each worker node and headnode, you could run these kind of commands.
You may ssh into each worker node to run it manually.
> Get free disk space to see if any disk is nearly full.
df -h
Filesystem Size Used Avail Use% Mounted on
udev 3.4G 12K 3.4G 1% /dev
tmpfs 697M 744K 697M 1% /run
/dev/sda1 985G 15G 931G 2% /
none 4.0K 0 4.0K 0% /sys/fs/cgroup
none 5.0M 0 5.0M 0% /run/lock
none 3.5G 12K 3.5G 1% /run/shm
none 100M 0 100M 0% /run/user
none 64K 0 64K 0% /etc/network/interfaces.dynamic.d
/dev/sdb1 281G 7.3G 259G 3% /mnt
> List all detailed file sizes starting from the root directory
sudo du / -ch
> See only the total file size from the root directory
sudo du / -ch |grep total
22G total
> Find files that are larger than 1000 MB
sudo find / -size +1000M -print0 | xargs -0 ls -l
These are system files in Linux we can ignore
-rw------- 1 root root 7516192768 Aug 15 18:08 /mnt/resource/swap
-r-------- 1 root root 140737477881856 Aug 15 19:17 /proc/kcore
> Find files that are larger than 500 MB
sudo find / -size +500M -print0 | xargs -0 ls -l
Usually the larger files on the local disks are log files from one of the various Hadoop services can use local significant space. You could delete old log files if you don't need them, or edit the log4j.properties for the service to lower the logging level, such as lowering DEBUG to WARN level or something along those lines. https://logging.apache.org/log4j/1.2/manual.html
Step 2: To see if there are many hive temporary files, you can check HDFS to list the temp folder like this:
> List HDFS files under the hive temp scratch directory
hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive
Notice when the temp files are in use there is a inuse.lck file that Hive maintains to show the folder is in use.

Normally once the temp folder is done, Hive will automatically clean it up. In the case Hive crashes, or the server is taken offline abruptly, the files may become dangling / orphaned.
Step 3. Cleaning Up dangling orphaned hive directories in HDFS as needed
A. There is a hive command cleardanglingscratchdir to automate this cleanup safely.
Quoting the docs:
The tool cleardanglingscratchdir can be run to clean up any dangling scratch directories that might be left over from improper shutdowns of Hive, such as when a virtual machine restarts and leaves no chance for Hive to run the shutdown hook.
hive --service cleardanglingscratchdir [-r] [-v] [-s scratchdir]
-r dry-run mode, which produces a list on console
-v verbose mode, which prints extra debugging information
-s if you are using non-standard scratch directory
The tool tests if a scratch directory is in use, and if not, will remove it. This relies on HDFS write locks to detect if a scratch directory is in use. An HDFS client opens an HDFS file ($scratchdir/inuse.lck) for writing and only closes it at the time that the session is closed. cleardanglingscratchdir will try to open $scratchdir/inuse.lck for writing to test if the corresponding HiveCli/HiveServer2 is still running. If the lock is in use, the scratch directory will not be cleared. If the lock is available, the scratch directory will be cleared. Note that it might take NameNode up to 10 minutes to reclaim the lease on scratch file locks from a dead HiveCli/HiveServer2, at which point cleardanglingscratchdir will be able to remove it if run again.
1. Dry Run
So you can run this command from the head node to get a dry run list of any files that need to be cleaned up:
hive --service cleardanglingscratchdir -r
-or-
hive --service cleardanglingscratchdir -r -s hdfs://mycluster/tmp/hive/hive
2. Real Run
If that list looks reasonable, and the dates look old and orphaned, then run it for real without the -r dry run.
hive --service cleardanglingscratchdir
-or-
hive --service cleardanglingscratchdir -s hdfs://mycluster/tmp/hive/hive
Note, if you get the error "Cannot find any scratch directory to clear" then it is likely that there is no dangling orphan folder to clean up.
B. If the tool doesn't work, or you are on an older build that doesn't have the cleanup, then you could manually remove the old files
To be very sure none of the files are in use, you should stop Hive services (using Ambari) before running any command, or selectively run the command only on old directories that are not currently in use.
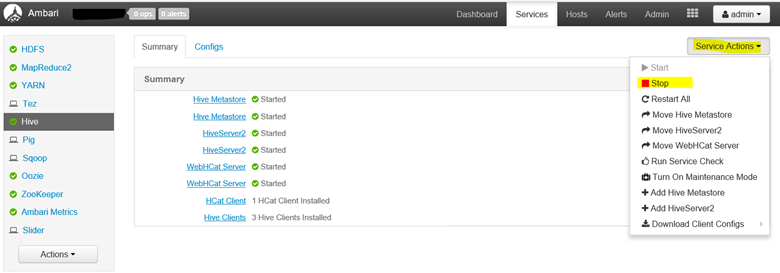
Manual Step 1. Stop Hive – I'm using Ambari to do that
Manual Step 2. Remove the temporary files in HDFS
Option A: All folders at once:
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/hive/
Option B: Remove only the folders you are worried about. The date of the hive job is typically listed in the directory name:
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/hive/7178b22b-186d-4284-a5a5-6092f165db37/hive_2016-04-14_22-35-31_149_2691354643150374266-1/
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/hive/7178b22b-186d-4284-a5a5-6092f165db37/hive_2016-04-14_22-36-56_659_7340036377865464119-4/
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/hive/7178b22b-186d-4284-a5a5-6092f165db37/hive_2016-04-14_22-47-26_179_2802662959127515918-4/
Manual Step 3. Now Start Hive again in Ambari using the same menu, then check that it made a fresh scratch file directory.
hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive
That's it for now. Let us know if you run into this problem, how you solve it, and any quirks you faced along the way.
Thanks! Jason Howell