Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
I had a recent need to parse JSON files using Hive. There were a couple of options that I could use. One is using native Hive JSON function such as get_json_object and the other is to use a JSON Serde to parse JSON objects containing nested elements with lesser code. I decided to go with the second approach for ease of use when parsing nested elements. Just a note here that this blog post just lists some of the ideas to make the custom JSON Serde with HDInsight, but this is not officially supported by the HDInsight Support team. So, please feel free to test this approach for your use case to see if it fits.
For this exercise, we will be using the custom JSON Serde https://github.com/rcongiu/Hive-JSON-Serde as referenced in this Hortonworks blog.
Step 1: Download Hive-JSON-Serde from GitHub and build the target JARs
The first step is to download the ZIP from GitHub project here. The screenshot below shows the downloaded file on my Windows machine.

The screenshot below shows the extracted contents from the zip file.
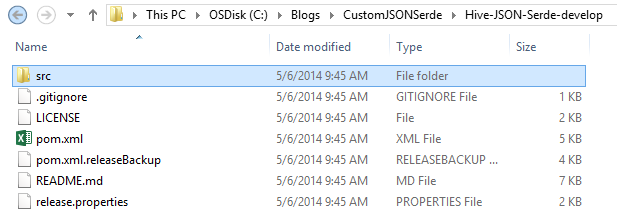
So, we have a pom.xml file that basically defines the project and Config details needed by Maven to build this project. There is also a src folder here that contains all the source files. So, now we need to download a tool like Maven to build this project and create target JARs.
The current version of Maven can be downloaded from here in Binary ZIP format. The screen shot below shows the contents of the Maven zip file extracted it into C:\Tools\Maven folder on my Windows machine.

It is a good idea to point the environment path variable to this folder so mvn can be executed from anywhere in the system. The article here describes how the environment variable path can be set. A tool like Curl can be used on Windows machines to download a dependency for this JSON Serde project. The latest version of Curl can be downloaded from here. The screen clip below shows the commands that need to be executed to build this package as outlined in this Hortonworks blog here 
So, the command line on a Windows machine with Curl and mvn looks like this now. We need to execute this from the folder that contains the src folder (source files) for the JSON Serde project – in our case - C:\Blogs\CustomJSONSerde\Hive-JSON-Serde-develop



Once the build is successful, you will notice that there is a new target folder created that contains the JAR files.

NOTE: Please see the special note here on some concepts on pom.xml, and also a section on the changes needed to make this Serde work with Hive 0.13.
Step 2: Upload these JAR files to WASB and create a customized HDInsight cluster
For this example, we will create an HDInsight cluster by name MyHDI30 with two storage accounts myhdi30primary, and myhdi30libs. We will create a container by name install within the myhdi30primary storage account, and container by name libs within the myhdi30libs account. Here is a screen clip of the storage account layout using the Server explorer on Visual Studio.
We can go ahead and upload the target JAR files into the libs container in the myhdi31libs storage account using the Server explorer.

Now using a PowerShell script as shown below, you can create an Azure HDInsight cluster pointing to these storage accounts, and with a default metastore for simplicity. Please note that if we go with the default metastore, when the cluster is dropped the metastore is also deleted. You would need to provision a custom metastore if you need to retain the metastore post HDInsight cluster deletion.
The PS Script below creates a new HDInsight cluster with a default metastore, pointing to the storage accounts created above.
Now, that we have a customized HDInsight cluster with the external JARs added in to the aux jars path, we are ready to see our JSON files getting parsed in action!
Step 3: See the JSON Serde in action!
So, for this demo, I am just going to use the example script complex_test.sql that comes along with the JSON Serde. This can be found in the folder where the Serde ZIP file has been extracted to. The screenshot below shows the path on my machine.

So, now we can make a slight change to the complex_test.sql to make it work with Azure HDInsight.
We no longer need the add jar command , since we have already provisioned the HDInsight cluster with the JAR. We also need to modify the LOAD DATA LOCAL INPATH command on that file such that we load from the WASB account, instead of the local file system. A copy of complex_test.sql with these changes is available here. This file can be uploaded to the default container on the primary storage account. In our case, it is the container install on the primary storage account: myhdi30primary. The complexdata.txt file is found with the Serde files, or it can also be downloaded from here and can be uploaded to the default container on the primary storage account.
Next we can use PowerShell to test the JSON parsing with Hive. The PowerShell script is below:
We can go ahead and invoke the complex_test.sql script that creates a Hive table with JSON Serde as the row format, and loads data and does a few selects to output the results form the data.
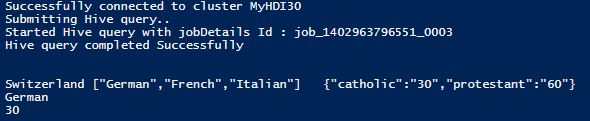
So, with a very simple test we have seen how easy it is to load an external custom Serde JAR into Azure HDInsight! Hope you found this helpful.
Happy Customizing!
Dharshana (@dharshb)
Thanks to Gregory Suarez for reviewing this article!
 A note on HDInsight 3.1 Clusters (Hive 0.13 versions and up)
A note on HDInsight 3.1 Clusters (Hive 0.13 versions and up)
Please note that due to some API changes in Hive 0.13, you may run into build errors when trying to build the project to work with Hive 0.13. One such error when I tried to use this Serde with Hive 0.13 was:
Caused by: java.lang.NoSuchMethodError:
org.apache.hadoop.hive.serde2.objectinspector.primitive.AbstractPrimitiveJavaObjectInspector.
<init>(Lorg/apache/hadoop/hive/serde2/objectinspector/primitive/PrimitiveObjectInspectorUtils$PrimitiveTypeEntry;)V
at org.openx.data.jsonserde.objectinspector.primitive.JavaStringByteObjectInspector.<init>(JavaStringByteObjectInspector.java:28)
at org.openx.data.jsonserde.objectinspector.JsonObjectInspectorFactory.<clinit>(JsonObjectInspectorFactory.java:174)
There are a couple of concepts that I would like to illustrate below, which in turn, will give some ideas for adapting this Serde for any future versions of Hive.
a. Pom.xml
Pom.xml defines the version of Hive that is used by Maven. We can change the version to pull from Hortonworks Hive version – modification the file is outlined below -
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <cdh.version>0.13.0.2.1.2.0-402</cdh.version> </properties>
You can find the different versions in greater detail here - https://repo.hortonworks.com/content/repositories/releases/org/apache/hive/hive-serde/maven-metadata.xml
Next, the dependency of Hadoop-core can be changed to point to the right version. You can see the different versions from here - https://repo.hortonworks.com/content/repositories/releases/org/apache/hadoop/hadoop-core/maven-metadata.xml <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-core</artifactId> <version>1.2.0.23</version> <scope>provided</scope> </dependency>
Finally, the repository can be modified to point to Hortonworks Maven Repo.
<repository> <id>Hortonworks</id> <name>Hortonworks Maven Repo</name> <url>https://repo.hortonworks.com/content/repositories/releases/</url> </repository>
Note: The modified pom.xml for Hive 0.13 can be found here
b. Source
Now, on the source code files, there needs to be a few changes to make it work with Hive 0.13. This specific issue is being tracked here - https://github.com/rcongiu/Hive-JSON-Serde/pull/64 . The pull request outlines some source code changes that can be done to make it work with Hive 0.13. Once those source code changes are complete, the source builds without any errors! NOTE: the JARs that are built from this version of the source will not be compatible with the older versions of Hive (Hive 0.12 and before).
Note: The overall source changes that would need to be done are outlined in the pull request here - https://github.com/rcongiu/Hive-JSON-Serde/pull/64/files. Thanks to this pull request, I was able to build the source to make it work with Hive 0.13.
Comments
- Anonymous
July 21, 2014
Hi,Can you please publish the jar you used to make it work with hive 0.13 ?Thanks - Anonymous
July 22, 2014
Hi Dave, I have attached the zip file that contains the JARs. Please test it on your environment to see if it fits. Thanks. - Anonymous
July 24, 2014
The comment has been removed - Anonymous
March 01, 2016
Hi, Thank you for a great post. Do you know the exact HIVE version and Hadoop-Core for HDinsight version 3.2 and 3.3 as I cannot find that information. Thanks