Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Gregory Suarez – 03/18/2014
(This blog posting assumes some basic knowledge of Apache Flume)
Overview
When asked if Apache Flume can be used with HDInsight, the response is typically no. We do not currently include Flume in our HDInsight service offering or in the HDInsight Server platform ( which is a single node deployment that can be used as a local development environment for HDInsight service) . In addition, a vast majority of Flume consumers will land their streaming data into HDFS – and HDFS is not the default file system used with HDInsight. Even if it were - we do not expose public facing Name Node or HDFS endpoints so the Flume agent would have a terrible time reaching the cluster! So, for these reasons and a few others , the answer is typically "no. …it won't work or its not supported "
While Flume is not supported by Microsoft, there is no reason why it can't be used to stream your data to Azure Blob storage – thus making your data available to your HDInsight Cluster. If support is needed specifically for Flume, the forums and discussion groups associated with your Hadoop distribution can be used to answer questions related to Flume.
How can Flume be used with HDInsight ? Considering the default (and recommended) file system used with HDInsight is an Azure Blob storage container , we can use techniques introduced in my earlier blog to create a local drive mapping to your Azure blob container from a Windows machine and then configure a Flume agent to use a file_roll sink which points to the newly created Windows drive. This will allow your flume agent to essentially land your data into Azure blob storage. The techniques introduced today can be used with existing Flume installations running Windows or Linux based Hadoop distributions - including Hortonworks, Cloudera, Mapr and others.
Why would someone that has an existing localized Hadoop distribution want to send their streaming data to HDInsight verses streaming it locally to their HDFS cluster? Perhaps the local cluster is reaching its limits and provisioning additional machines is becoming less cost effective. Perhaps the idea of provisioning a cluster "on-demand" to process your data (which is growing everyday- compliments of Flume) is starting to become very appealing. Data can continue to be ingested – even if you have decomissioned your HDInsight cluster. Perhaps, you are learning Hadoop from an existing sandbox (that includes Flume-NG) and using it to collect events from various server logs in your environment. The data has grown beyond the capabilities of the sandbox and you've been considering HDInsight service. Making a simple flume agent configuration change to an existing sink would land your data in the blob storage container which makes it available to your HDInsight cluster.
Flume Overview
Flume is all about data ingestion (ingres) into your cluster. In particular, log files that are accumulating on a few machines or even thousands of machines can be collected, aggregated, and streamed to a single entry point within your cluster. Below describes some Flume components and concepts:
- Event: The basic payload of data transported by Flume. It represent the unit of data that Flume can transport from its point of origination to its final destination. Optional headers are chained together via Interceptors and are typically used to inspect and alter events.
- Client: An interface implementation that operates at the point of origin of events and delivers them to a Flume agent. Clients typically operate in the process space of the application they are consuming data from.
- Agent: Core element in Flume's data path. Hosts flume components such as sources, channels and sinks, and has the ability to receive, store and forward events to their next-hop destination.
- Source: Consumes events delivered to it via a client. When a source receives an event, it hands it over to one or more channels.
- Channel: A transient store for events. It's the glue between the source and sink. Channels play an important role in ensuring durability of the flows.
- Sink: Remove events from a channel and transmit them to the next agent in the flow, or to the event's final destination. Sinks that transmit the event to its final destination are also known as terminal sinks.
Events flow from the client to the source. The source writes events to one or more channels. The channel is the holding area of events in flight and can be configured durable (file backed) or non-durable (memory backed). The events will wait in the channel until the consuming sink can drain it and send the data off to its final destination.
Below depicts a simple Flume agent configured with an HDFS terminal sink:
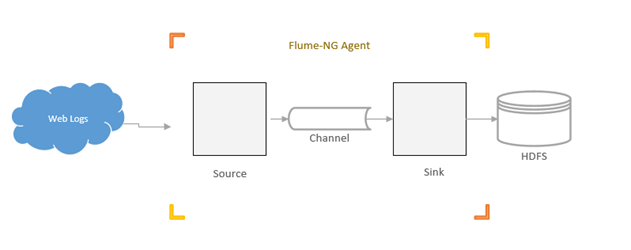
For additional details and configuration options available for Flume, please visit the Apache Flume website.
Flume & Azure Blob Storage
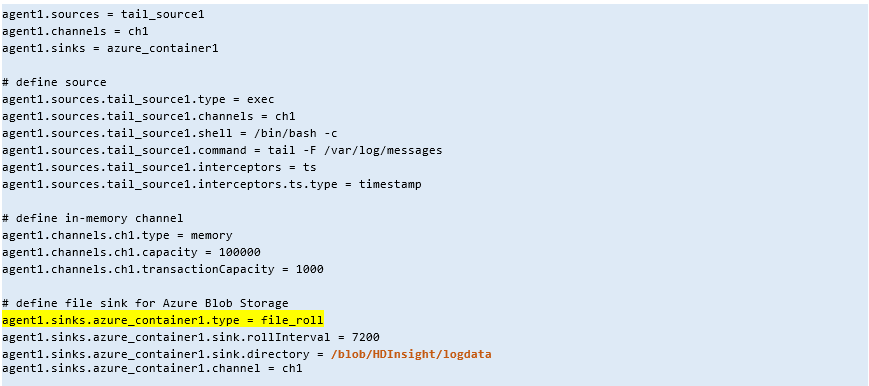
To allow Flume to send event data to an HDInsight cluster, a File Roll Sink will need to be configured within the Flume configuration. The sink directory (the directory where the agent will send events) must point to a Windows drive that is mapped to the Azure Blob storage container. Below is a diagram depicting the flow.

Here's a sample Flume configuration that defines a file_roll sink connected to Azure Blob storage:
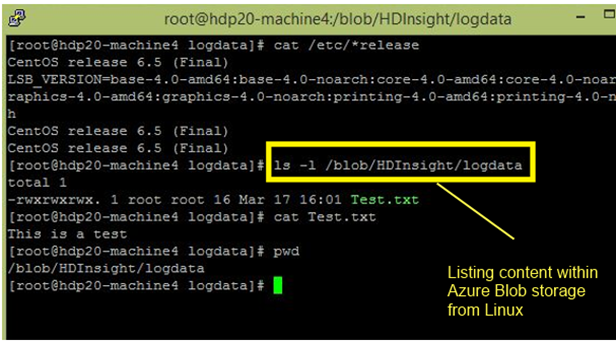
To further illustrate the connectivity concept, below I issue an –ls command from the same Linux machine hosting the above Flume configuration to demonstrate the Azure connectivity. Earlier, I placed a file called Test.txt in the logdata directory.
Connect Flume file_roll sink to Azure Blob storage
This section provides high level configuration details to connect a Flume file_roll sink to Azure blob storage. Although all possible scenarios cannot be covered, the information below should be enough to get you started.
Install CloudBerry Drive on a Windows machine. The Cloudberry drive will provide the central glue connecting the local file system to Azure blob storage endpoint. Note, Cloudberry Drive comes in two different flavors. If you plan on exposing the drive via a network share – perhaps to allow Flume agent running on Linux to access ) you'll need to install the server flavor of Cloudberry drive. If you install CloudBerry drive on a machine hosting virtual machines, the guests OS's should be able to access the drive via Shared Folders (depending on the VM technology you are using). Conifguration of the software is fairly trivial. I've included some screen shots showing my configuration:
Supply Azure Storage account name and key
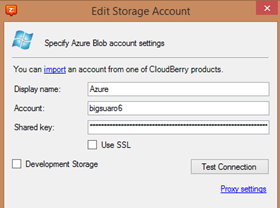
Select the Storage account and specify the container used for HDInsight. In my configuration, I'm using CloudBerry Desktop. Be sure Network Mapped Drive is selected. Note for CloudBerry Server version, and additional option will be presented indicating whether this drive should be exposed via network share

In my configuration, my Flume agent is installed on an edge node within my Hortonworks HDP 2.0.6 Linux cluster. The node is a VM inserted into the cluster via Ambari. I used VMWare Shared Folders to expose the CloudBerry drive to the guest OS running Centos 6.5

I installed VMWare tools and mounted the shared folder to the following directory on the local system -> /blob using the following command:
mount -t vmhgfs .host:/ /blob
Next I verified the drive was successfully mounted by issuing an -ls /blob
Finally, I tested a few Flume sources (exec, Twitter, etc…) against a directory contained in my Azure blob

Having fun with Twitter and Flume
I downloaded the SentimentFiles.zip files associated with Hortonworks Tutorial 13: How to Refine and Visualize Sentiment Data and unzipped the files into a directory on a node within my local HDP 2.0 Linux cluster. I wanted to stream Twitter data directly from the Flume agent directly to my HDInsight cluster. I modified the flumetwitter.conf file and changed the HDFS sink to a file_roll sink which points to the Azure blob container. (see partial configuration changes below)
flumetwitter.conf

Next I launched the Flume agent using the command below and collected data for about 2 weeks
root@hdp20-machine4 logdata]# flume-ng agent -c /root/SentimentFiles/SentimentFiles/flume/conf/ -f /root/SentimentFiles/SentimentFiles/flume/conf/flumetwitter.conf -Dflume.root.logger=DEBUG,console -n TwitterAgent
Below charts the sink roll intervals over a timespan of about 2 weeks with some additional notes in the image below.

During this time span, I collected a little over 32 GB of Tweets pertaining to the keywords I defined in flumetwitter.conf file above.
I wrote a very simple .NET stream based mapper and reducer to count over the source token within each tweet.
Here's my mapper and reducer code:
After running the job, I imported the results into PowerView and answered some basic questions - "What are the top sources?" , "What application on Android or Windows mobile devices are the most common?"
Here's the top 20 by source.
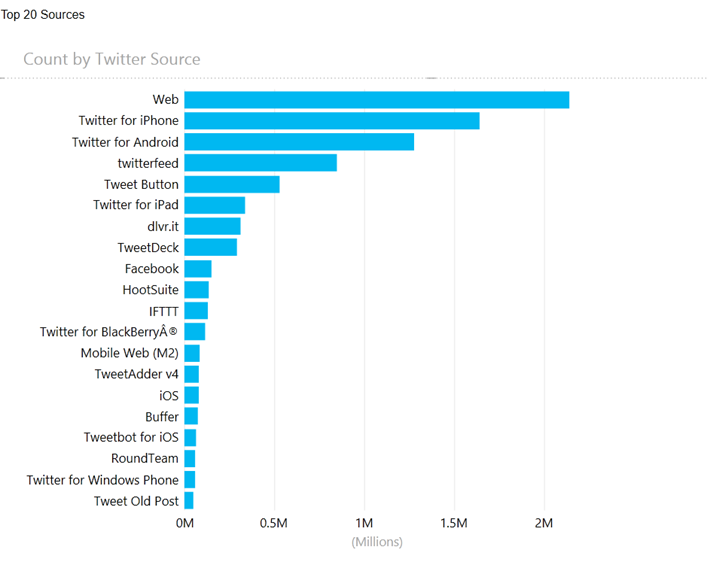
Admintently, better analytics can be performed given the content and subject matter of the data collected but today I wanted a very simple test job to extract some basic information.
Conclusion
Over the last few weeks, I've collected over 130 GB of streaming data ranging from log files, to Azure Datamarket content, to Twitter feeds. This is hardly "big data", but it could be … over time .
Next time, Bill Carroll and I will analyze the data collected using Hive and the .NET SDK for Hadoop- Map/Reduce incubator api's.
Comments
- Anonymous
March 19, 2014
Great blog, thanks Gregory. Very helpful - Anonymous
March 01, 2015
Can i done this without Installing CloudBerry Drive on a Windows machine ?