Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
In your zeppelin notebook you have scala code that loads parquet data from two folders that is compressed with snappy. You use SparkSQL to register one table named shutdown and another named census. You then use the SQLContext to join the two tables in a query and show the output. Below is the zeppelin notebook and code.

import org.apache.spark.sql._
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val dfshutdown = sqlContext.load("wasb://data@eastuswcarrollstorage.blob.core.windows.net/parquet/abnormal_shutdown_2_parquet_tbl/", "parquet")
val dfcensus = sqlContext.load("wasb://data@eastuswcarrollstorage.blob.core.windows.net/parquet/census_fact_parquet_tbl/dt=2015-07-22-02-04/", "parquet")
dfshutdown.registerTempTable("shutdown")
dfcensus.registerTempTable("census")
val q1 = sqlContext.sql("SELECT c.osskuid, s.deviceclass, COUNT(DISTINCT c.sqmid) as Cnt FROM shutdown s LEFT OUTER JOIN census c on s.sqmid = c.sqmid GROUP BY s.deviceclass, c.osskuid")
q1.show()
However, during the execution, exceptions are raised in the Spark Dashboard and returned to the zeppelin notebook and eventually after retries the job fails. What is going on?
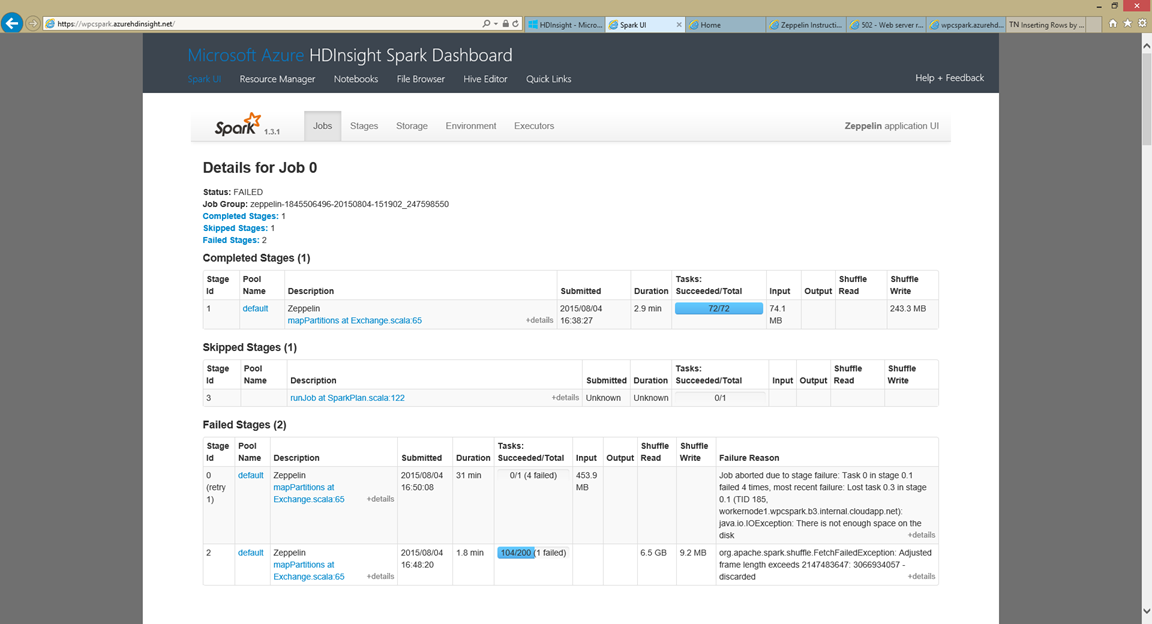


Exceptions:
org.apache.spark.shuffle.FetchFailedException: Adjusted frame length exceeds 2147483647: 3066934057 - discarded
at org.apache.spark.shuffle.hash.BlockStoreShuffleFetcher$.org$apache$spark$shuffle$hash$BlockStoreShuffleFetcher$$unpackBlock$1(BlockStoreShuffleFetcher.scala:67)
at org.apache.spark.shuffle.hash.BlockStoreShuffleFetcher$$anonfun$3.apply(BlockStoreShuffleFetcher.scala:83)
at org.apache.spark.shuffle.hash.BlockStoreShuffleFetcher$$anonfun$3.apply(BlockStoreShuffleFetcher.scala:83)
at scala.collection.Iterator$$anon$13.hasNext(Iterator.scala:371)
at org.apache.spark.util.CompletionIterator.hasNext(CompletionIterator.scala:32)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:39)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:327)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:327)
at scala.collection.Iterator$$anon$13.hasNext(Iterator.scala:371)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:327)
at org.apache.spark.sql.execution.Aggregate$$anonfun$execute$1$$anonfun$7.apply(Aggregate.scala:154)
at org.apache.spark.sql.execution.Aggregate$$anonfun$execute$1$$anonfun$7.apply(Aggregate.scala:149)
at org.apache.spark.rdd.RDD$$anonfun$14.apply(RDD.scala:634)
at org.apache.spark.rdd.RDD$$anonfun$14.apply(RDD.scala:634)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:277)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:244)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:277)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:244)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:68)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:41)
at org.apache.spark.scheduler.Task.run(Task.scala:64)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:203)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: io.netty.handler.codec.TooLongFrameException: Adjusted frame length exceeds 2147483647: 3066934057 - discarded
at io.netty.handler.codec.LengthFieldBasedFrameDecoder.fail(LengthFieldBasedFrameDecoder.java:501)
at io.netty.handler.codec.LengthFieldBasedFrameDecoder.failIfNecessary(LengthFieldBasedFrameDecoder.java:477)
at io.netty.handler.codec.LengthFieldBasedFrameDecoder.decode(LengthFieldBasedFrameDecoder.java:403)
at io.netty.handler.codec.LengthFieldBasedFrameDecoder.decode(LengthFieldBasedFrameDecoder.java:343)
at io.netty.handler.codec.ByteToMessageDecoder.callDecode(ByteToMessageDecoder.java:249)
at io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:149)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:333)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:319)
at io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:787)
at io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:130)
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:511)
at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:468)
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:382)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:354)
at io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:116)
... 1 more
java.io.IOException: There is not enough space on the disk
at sun.nio.ch.FileDispatcherImpl.write0(Native Method)
at sun.nio.ch.FileDispatcherImpl.write(FileDispatcherImpl.java:74)
at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93)
at sun.nio.ch.IOUtil.write(IOUtil.java:51)
at sun.nio.ch.FileChannelImpl.write(FileChannelImpl.java:205)
at sun.nio.ch.FileChannelImpl.transferToTrustedChannel(FileChannelImpl.java:473)
at sun.nio.ch.FileChannelImpl.transferTo(FileChannelImpl.java:569)
at org.apache.spark.util.Utils$.copyStream(Utils.scala:326)
at org.apache.spark.util.collection.ExternalSorter$$anonfun$writePartitionedFile$1.apply$mcVI$sp(ExternalSorter.scala:736)
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:141)
at org.apache.spark.util.collection.ExternalSorter.writePartitionedFile(ExternalSorter.scala:734)
at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:71)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:68)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:41)
at org.apache.spark.scheduler.Task.run(Task.scala:64)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:203)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
What's going on?
First let's review some background information. The chart below describes attributes of different compression formats. Notice that Snappy is not splitable. In the example the parquet files are compressed with snappy. When a file is loaded from disk it will try to split the file into blocks in order to distribute across the cluster's worker nodes. Because Snappy and Gzip is not splitable, there is no marker within the file to show where the file can be broken up into blocks, therefore the whole file is in one split.
| Compression Format | Tool | Algorithm | File Extension | Splitable |
| Gzip | Gzip | DEFLATE | .gz | No |
| Bzip2 | Bizp2 | Bzip2 | .bz2 | Yes |
| LZO | Lzop | LZO | .lzo | Yes, if indexed |
| Snappy | n/a | Snappy | .snappy | No |
When the load method of the SQLContext is executed a resilient distributed dataset (RDD) is created. A RDD is a collection of objects that are distributed across the cluster and partitioned. Because the snappy file is not splitable a RDD is created with only one partition. If the file was splitable the RDD would be created with multiple partitions.
So what is going on? When the shuffle sort operation occurs. Shuffle data is written to local disk on the worker nodes. The size of the data file to be sorted exceeds the available disk space on the worker node. You can see the first exception where the fetch for the shuffle exceed 2g. Then the next exception where there is not enough disk space. If the RDD had more partitions the shuffle operations would be done against smaller datasets that are under 2g.
So how do we resolve the problem? Fortunately we can repartition the RDD to create more partitions after the load method and before the shuffle operation. You can do tests to increase the number of partitions to find the right number for your cluster and data. So we can add the code .repartition(100), which creates a RDD with 100 partitions and allows the shuffle sort to succeed for this workload.
The new code looks like:
import org.apache.spark.sql._
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val dfshutdown = sqlContext.load("wasb://data@eastuswcarrollstorage.blob.core.windows.net/parquet/abnormal_shutdown_2_parquet_tbl/", "parquet")
dfshutdown.repartition(100)
val dfcensus = sqlContext.load("wasb://data@eastuswcarrollstorage.blob.core.windows.net/parquet/census_fact_parquet_tbl/dt=2015-07-22-02-04/", "parquet")
dfcensus.repartition(100)
dfshutdown.registerTempTable("shutdown")
dfcensus.registerTempTable("census")
val q1 = sqlContext.sql("SELECT c.osskuid, s.deviceclass, COUNT(DISTINCT c.sqmid) as Cnt FROM shutdown s LEFT OUTER JOIN census c on s.sqmid = c.sqmid GROUP BY s.deviceclass, c.osskuid")
q1.show()
More Information: https://forums.databricks.com/questions/111/why-am-i-seeing-fetchfailedexception-adjusted-fram.html
I hope this helps your Spark on HDInsight experience,
Bill