Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This blog is part 3 of a series that covers relevant Azure fundamentals - concepts/terminology that you need to know, in the context of Hadoop. Some of the content is a copy of Azure documentation (full credit to the Azure documentation team). I have attempted to compile relevant information into a single post, along with my commentary, to create a one stop shop for those new to Azure and thinking Hadoop.
In blog 1, I covered Azure networking, in blog 2, Azure storage including managed disks. Here's what's covered in the post:
Section 09. Azure Resource Manager
Section 10: CLIs for Azure
Section 11: Availability sets and Availability zones
Section 12: Azure compute - Linux VMs
Here are links to the rest of the blog series: Just enough Azure for Hadoop - Part 1 | Focuses on networking
Just enough Azure for Hadoop - Part 2 | Focuses on storage
Just enough Azure for Hadoop - Part 4 | Focuses on select Azure Data Services (PaaS)
9. Azure Resource Manager (ARM)
When you provision infrastructure in Azure, there are a number of resources created that can be logically grouped. There are times when you need to operate on them as a single entity, as a transaction while provisioning for example. Azure Resource Manager enables you to work with the resources in your solution as a group. You can deploy, update, or delete all the resources for your solution in a single, coordinated operation. You use an ARM template for deployment and that template can work for different environments such as testing, staging, and production. Resource Manager provides security, auditing, and tagging features to help you manage your resources after deployment.
Some terminology..
- Resource - A manageable item that is available through Azure. Some common resources are a virtual machine, storage account, web app, database, and virtual network, but there are many more.
- Resource group - A container that holds related resources for an Azure solution. The resource group can include all the resources for the solution, or only those resources that you want to manage as a group. You decide how you want to allocate resources to resource groups based on what makes the most sense for your organization.
E.g. If you are using Cloudbreak for deploying Hortonworks Hadoop clusters on Azure, you may want a resource group for Cloudbreak deployer, one for each cluster (default), and one for your networking resources. - ARM template - A JavaScript Object Notation (JSON) file that defines one or more resources to deploy to a resource group. It also defines the dependencies between the deployed resources. The template can be used to deploy the resources consistently and repeatedly. See Template deployment.
If you take Hortonworks Cloudbreak and Cloudera's Director - cloud provisioning tools, under the hood they generate ARM templates.
To summarize benefits of ARM:
- Idempotency: You can repeatedly deploy your solution throughout the development lifecycle and have confidence your resources are deployed in a consistent state.
- You can manage your infrastructure through declarative templates rather than scripts.
- You can define the dependencies between resources so they are deployed in the correct order.
- You can apply access control to all services in your resource group because Role-Based Access Control (RBAC) is natively integrated into the management platform.
- You can apply tags to resources to logically organize all the resources in your subscription.
- You can clarify your organization's billing by viewing costs for a group of resources sharing the same tag.
10. CLI for Azure
In this section, only Linux compatible CLI is covered.
10.1. Azure CLI 2.0
Azure CLI 2.0 is Azure's new command-line experience for managing Azure resources. You can use it in your browser with Azure Cloud Shell, or you can install it on macOS or Linux and run it from the command line.
Azure CLI 2.0 is optimized for managing and administering Azure resources from the command line, and for building automation scripts that work against the Azure Resource Manager.
Using the Azure CLI 2.0, you can create VMs within Azure as easily as typing the following command:
 Documentation
Documentation
10.2. Azure Cloud Shell
Azure Cloud Shell is an interactive, browser-accessible shell for managing Azure resources. It gives you the flexibility of choosing the shell experience that best suits the way you work. Linux users can opt for a Bash experience.
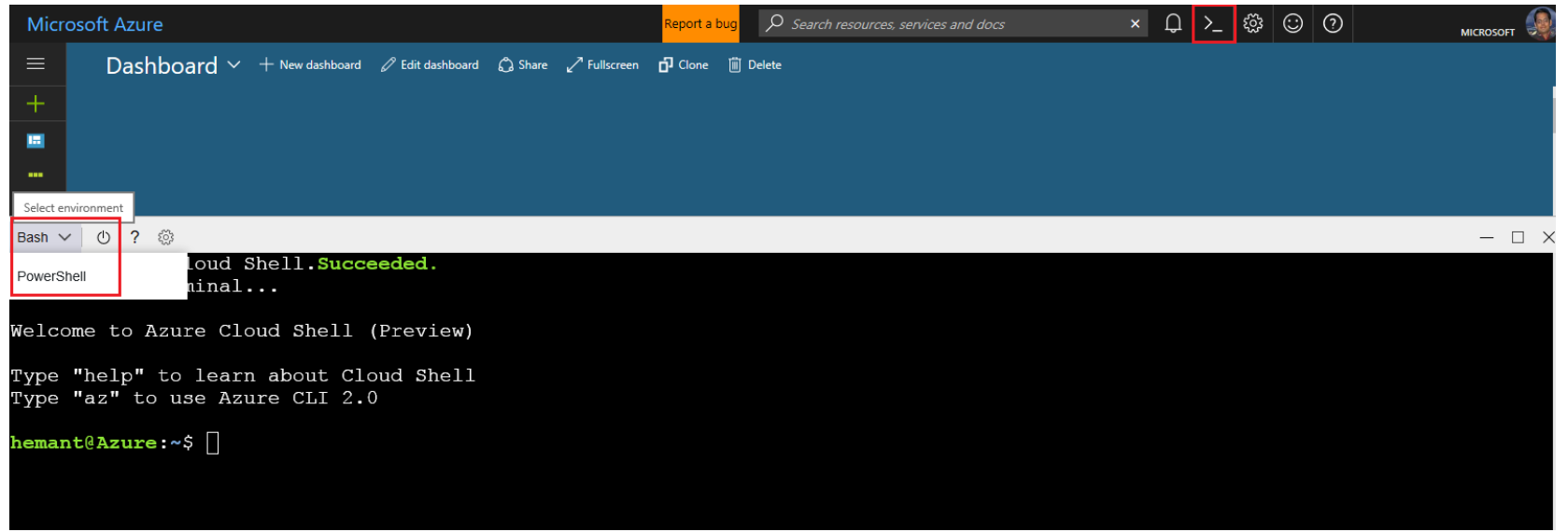 Documentation
Documentation
11. Availability Sets & Availability Zones
11.1. Availability sets
An availability set is a logical grouping of VMs within a datacenter that allows Azure to understand how your application is built to provide for redundancy and availability.
An availability set is composed of two groupings that protect against hardware failures and allow updates to safely be applied - fault domains (FDs) and update domains (UDs). You can read more about how to manage the availability of Linux VMs.
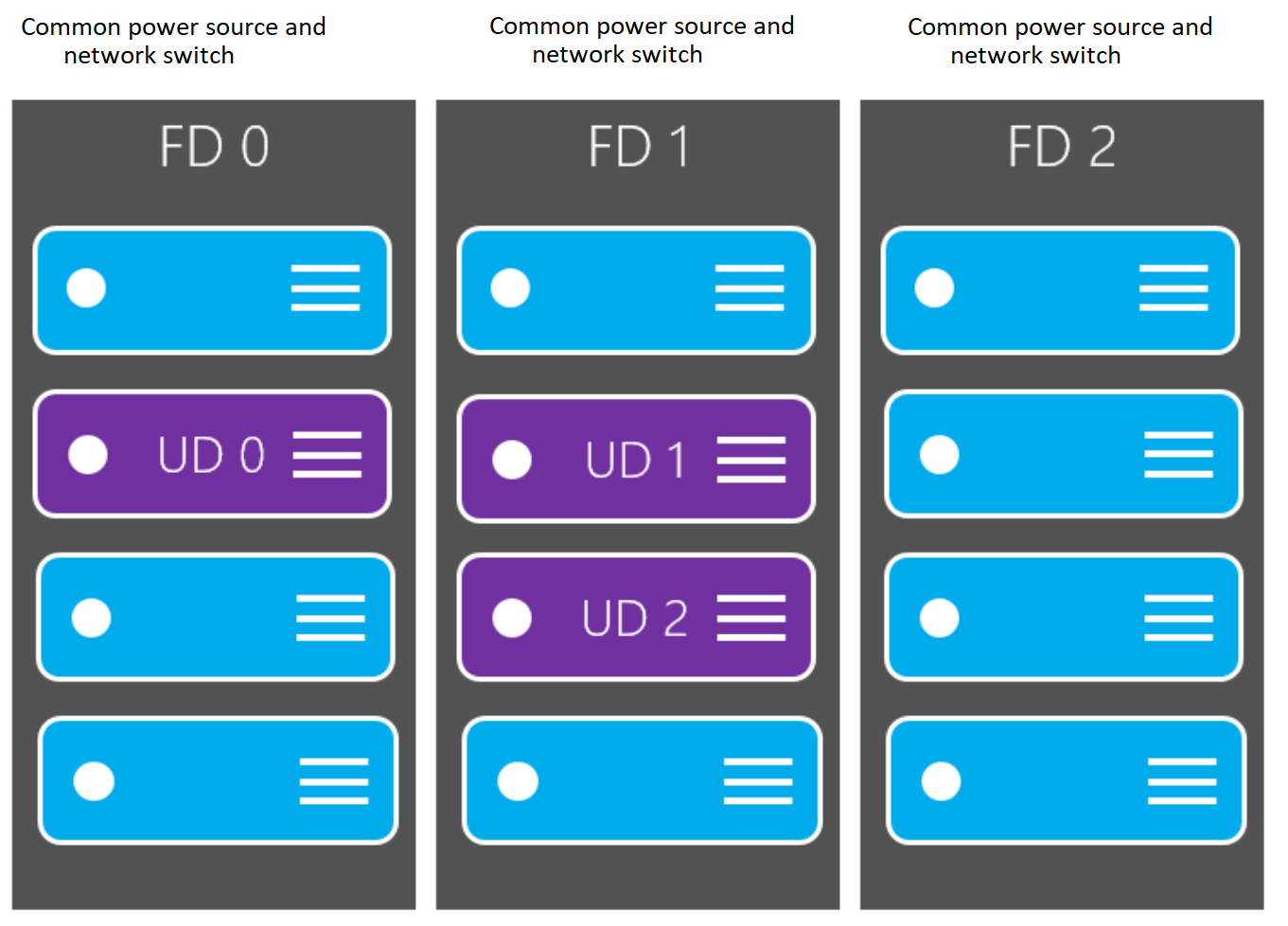
Fault domainsA fault domain is a logical group of underlying hardware that share a common power source and network switch, similar to a rack within an on-premises datacenter. As you create VMs within an availability set, the Azure platform automatically distributes your VMs across these fault domains. This approach limits the impact of potential physical hardware failures, network outages, or power interruptions.
By default, the virtual machines configured within your availability set are separated across up to three fault domains for Resource Manager deployments. This link shows number of fault domains available per region.
Update domainsAn update domain is a logical group of underlying hardware that can undergo maintenance or be rebooted at the same time. As you create VMs within an availability set, the Azure platform automatically distributes your VMs across these update domains. This approach ensures that at least one instance of your application always remains running as the Azure platform undergoes periodic maintenance. The order of update domains being rebooted may not proceed sequentially during planned maintenance, but only one update domain is rebooted at a time.
For a given availability set, by default, five non-user-configurable update domains are assigned (Resource Manager deployments can then be increased to provide up to 20 update domains) to indicate groups of virtual machines and underlying physical hardware that can be rebooted at the same time. When more than five virtual machines are configured within a single availability set, the sixth virtual machine is placed into the same update domain as the first virtual machine, the seventh in the same update domain as the second virtual machine, and so on. The order of update domains being rebooted may not proceed sequentially during planned maintenance, but only one update domain is rebooted at a time. A rebooted update domain is given 30 minutes to recover before maintenance is initiated on a different update domain.
How do fault domains and update domains overlap?
Here is an example, from Azure documentation..
Managed Disk fault domainsFor VMs using managed disks, VMs are aligned with managed disk fault domains when using a managed availability set. This alignment ensures that all the managed disks attached to a VM are within the same managed disk fault domain. Only VMs with managed disks can be created in a managed availability set. The number of managed disk fault domains varies by region - either two or three managed disk fault domains per region. You can read more about these managed disk fault domains for Linux VMs.
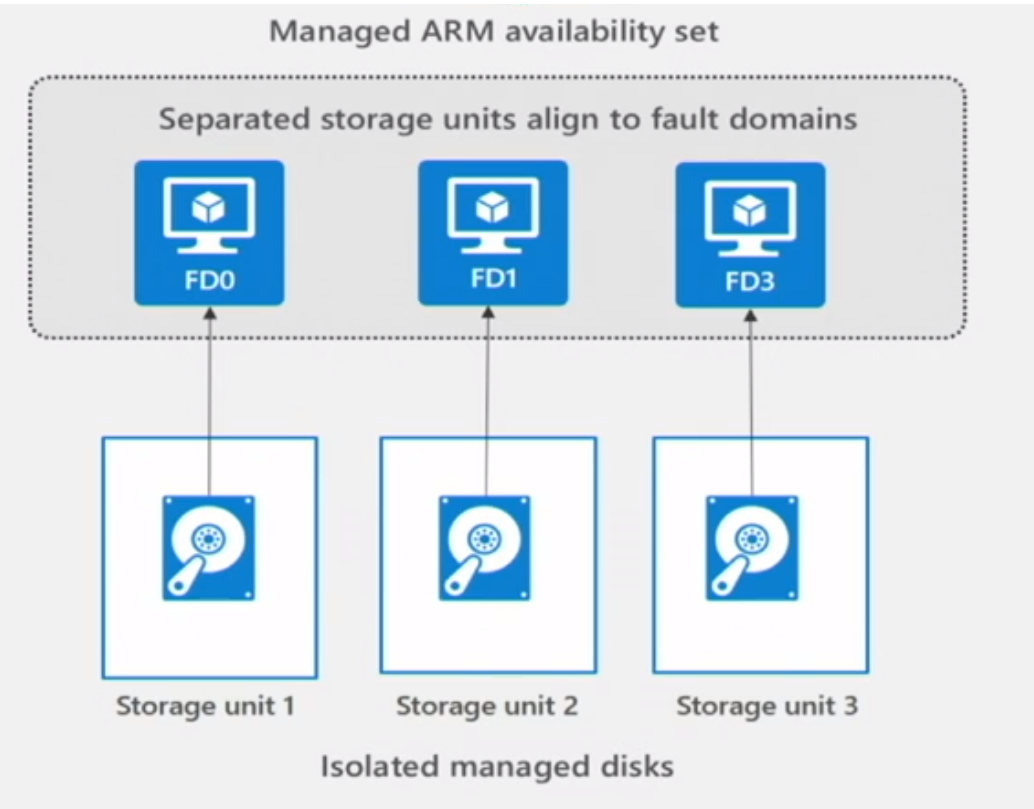
The above is a good example of how you could place your Hadoop master nodes.
Similarly, you could place your slave nodes in an availability set, as you could your edge nodes if you have more than 1.
Single VMs and availability sets
Avoid leaving a single instance virtual machine in an availability set by itself. VMs in this configuration do not qualify for a SLA guarantee and face downtime during Azure planned maintenance events, except when a single VM is using Azure Premium Storage. For single VMs using premium storage, the Azure SLA applies.
In the context of Hadoop, you would put all your masters in one availability set, all your workers in one, your edge nodes if more than one, into an availability set.
11.2. Availability Zones
In the Azure blog storage section above, you read about ZRS - Zone Redundant Storage.
You data is backed to three separate zones within the same Azure region to provide the most fault tolerant solution.
Every supported region has 3 availability zones. Each availability zone in an Azure region is physically and logically separate from its counterparts - has a distinct power source, network, and cooling. For your most mission critical applications, if you architect leveraging this feature, if one zone is compromised, then replicated apps and data are instantly available in another zone.
This feature is in review at the time of writing this blog post.
12. Azure Compute - Linux Virtual Machines
Hadoop runs on Linux, so the focus of this section is exclusively Linux virtual machines.
12.1. Anatomy of a VM
The following is a pictorial representation of what you get when you provision a VM.
Diagram 1: Here is an example of a Cloudbreak deployer VM I provisioned.
Diagram 2: When you click on the VM..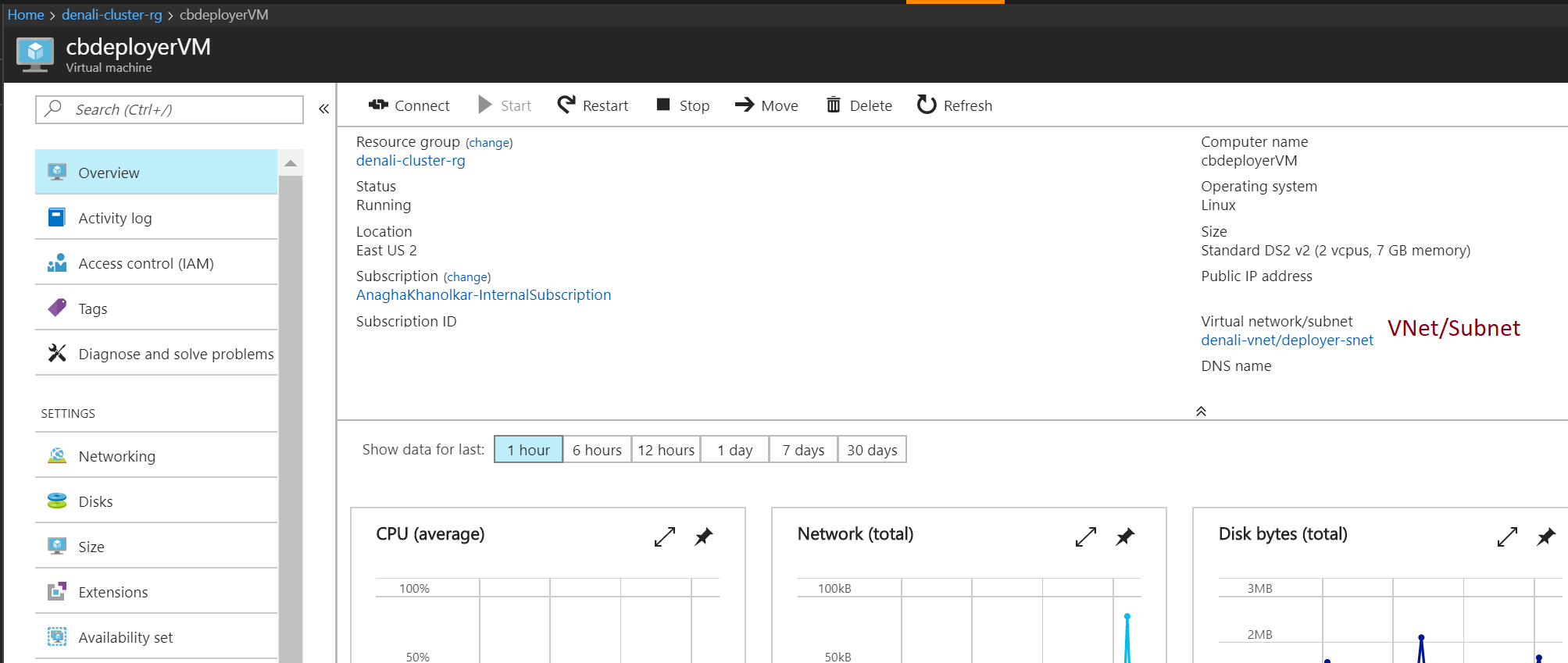
Diagram 3: When you click on the NSG resource..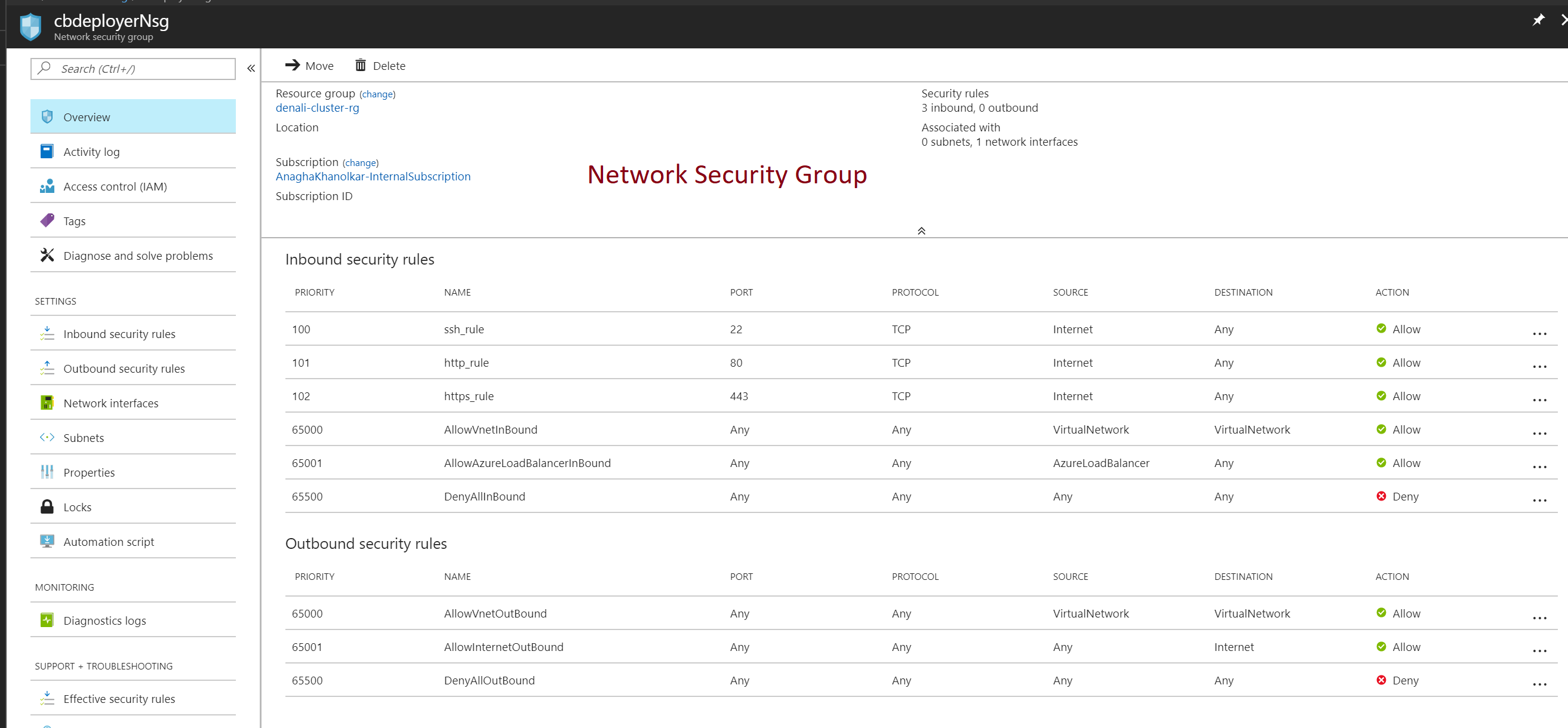
Diagram 4: When you click on the VM, and then on Networking...
Diagram 5: When you click on the VM and then disks..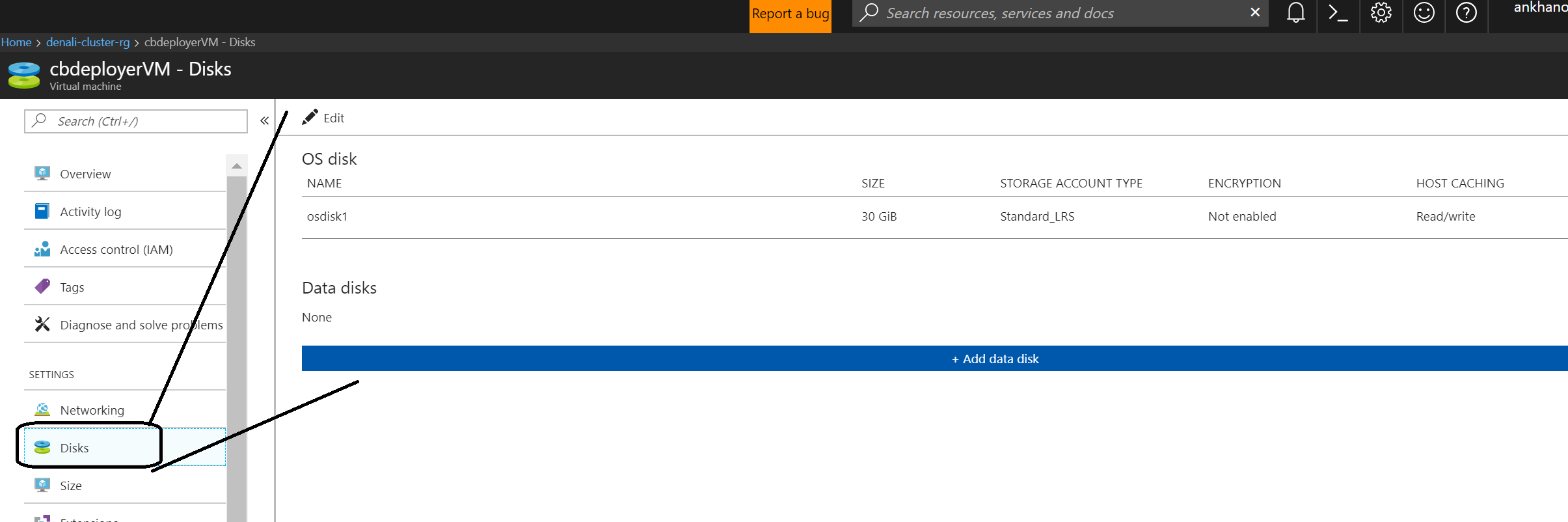
Diagram 6: Here's the VNet...
Diagram 7: And the subnet..
Diagram 8: DNS..

Diagram 9: ARM template..
12.2. VM SLAs
https://azure.microsoft.com/en-us/support/legal/sla/virtual-machines/v1\_6/
12.3. Endorsed OS distributions
Partners publish images into the marketplace. E.g. we have RHEL "Pay as you go" image where you pay licensing fee per hour over and above the licensing cost. If you don't find one that you prefer, you can create and publish to the market place.
Documentation
Cloudera has a centos 7.3 image available in the marketplace that is pre-configured and reduced amount of configuration needed for Hadoop.
12.4. Categorization of VMs
The following images describes categorization at the time of writing this blog post.

Documentation links:
General Purpose
Compute Optimized
Memory Optimized
Storage Optimized GPU
High Performance Compute
Typically, we see use of DSv2, supports premium and standard disks if you need to switch at some point till they hit the max SKU, then we see GS series used.
12.5. What's in an Azure VM SKU?
Lets take the VM SKU from diagram 2, in 12.1 - DS2v2.
(1) On the surface..

The diagram shows that the VM has:
DSv2 VM: 2 vCPUs, RAM of 7 GB, 14 GB of temporary disk space, and drive type is SSD.
(2) What about OS disk?
In diagram 5 above, we saw that the OS disk was 30 GB.
So, lets look at what it looks like with lsblk..

(3) Is hyper-threading enabled? What's the CPU model?
Here's some more information - hyper threading is not enabled (dv3 series do)...
(4) How many disks can I attach to my VM?
(5) What is the max disk throughput (cap for VM)
(6) What's the network performance I can expect?
(7) What's the max number of NICs I can attach?
Link 
So, to summarize, for DSv2:
2 vCPUs, RAM of 7 GB, 14 GB of temporary disk space - SSD, 30 GB of OS disk - SSD.
Max data disks = 4 | Disk throughput = 96 MBps | Network performance = 1500 Mbps | Max NICs = 2
Now, lets look at bigger VMs that are typically used for Hadoop workloads for some perspective..

12.6. VM max disk throughput, premium managed disk throughput and optimal number of premium managed disks to attach 
So, lets say, we go with DS15v2 as an example, and we want to attach P20 disks -
Max disk throughput is 960 MB/sec
Max number of disks is 40
P20 provides 150 MB/sec throughput
P30 provides 200 MB/sec throughput
The optimal number of disks we can attach - ~ 7 P20 disks or ~5 P30 disks
Beyond that - even if you attach more disks, the max disk throughput stays the cap for the VM, in fact throttling could occur resulting in degradation of performance.
The above is particularly important when you are sizing your cluster, especially your higher environments.
Note that the premium managed disk limits factored in the above are for disk traffic only. These limits don't include cache hits and network traffic. A separate bandwidth is available for VM network traffic. Bandwidth for network traffic is different from the dedicated bandwidth used by premium storage disks.
12.7. Caching in VMs that support premium storage
VMs that support Premium Storage have a unique caching capability for high levels of throughput and latency. The caching capability exceeds underlying premium storage disk performance.
- You can set the disk caching policy on premium storage disks to ReadOnly, ReadWrite, or None.
- The default disk caching policy is ReadOnly for all premium data disks and ReadWrite for operating system disks.
- For read-heavy or read-only data disks, set the disk caching policy to ReadOnly.
- For write-heavy or write-only data disks, set the disk caching policy to None.
To achieve scalability targets in Premium Storage, for all premium storage disks with cache set to ReadOnly or None, you must disable "barriers" when you mount the file system.
- For reiserFS, to disable barriers, use the
barrier=nonemount option. (To enable barriers, usebarrier=flush.) - For ext3/ext4, to disable barriers, use the
barrier=0mount option. (To enable barriers, usebarrier=1.) - For XFS, to disable barriers, use the
nobarriermount option. (To enable barriers, usebarrier.) - For premium storage disks with cache set to ReadWrite, enable barriers for write durability.
- For volume labels to persist after you restart the VM, you must update /etc/fstab with the universally unique identifier
- (UUID) references to the disks.
For Hadoop, ext4 or xfs are applicable.
Reference architecture for Azure, from Cloudera does not reference disk caching policy - have reached out, will post an update when I get a response back.
12.8. Disk striping with premium disks
When a high scale VM (DS14v2 and above, GS* series) is attached with several premium storage persistent disks, the disks can be striped together to aggregate their IOPs, bandwidth, and storage capacity.
Reference architecture for Azure, from Cloudera does not reference disk striping - have reached out, will post an update when I get a response back.
12.9. Throttling
Azure Premium Storage provisions specified number of IOPS and Throughput depending on the VM sizes and disk sizes you choose. Anytime your application tries to drive IOPS or Throughput above these limits of what the VM or disk can handle, Premium Storage will throttle it. This manifests in the form of degraded performance in your application. This can mean higher latency, lower Throughput or lower IOPS. If Premium Storage would not throttle, your application would completely fail by exceeding what its resources are capable of achieving. So, to avoid performance issues due to throttling, always provision sufficient resources for your application.
12.10. IP addresses for your VMs
You can configure static or dynamic as covered in the networking section. You can choose to have a pubic IP if needed.
12.11. Scaling VMs vertically
You can scale a virtual machine vertically from one SKU to another.
Here is the catch, you need to de-allocate the VM, if the desired size is not available on the hardware cluster that is hosting the VM; This can be verified using commands detailed in the link below for resizing. Note: De-allocating the VM releases any dynamic IP addresses assigned to the VM. The OS and data disks are not affected.
In general, resizing results in a restart of the VM, and all disks are remapped.
Documentation
Here is where you could potentially use this - lets say you provisioned your Hadoop cluster, and in the course of your Spark development if you find that you need more RAM, you can resize your VMs.
12.12. Move VMs
VMs can be moved between resource groups and subscriptions.
This is helpful if you ever need to move from one subscription to another, post provisioning. /en-us/azure/virtual-machines/linux/move-vm
12.13. Tag a VM
You may want to tag your VMs for grouping. Helpful if you want to, say tag a VM as worker, master, edge etc
/en-us/azure/virtual-machines/linux/tag
12.14. VM script extensions
The Custom Script Extension downloads and executes scripts on Azure virtual machines. This extension is useful for post deployment configuration, software installation, or any other configuration / management task. Scripts can be downloaded from Azure storage or other accessible internet location, or provided to the extension run time. The Custom Script extension integrates with Azure Resource Manager templates, and can also be run using the Azure CLI, PowerShell, Azure portal, or the Azure Virtual Machine REST API.
/en-us/azure/virtual-machines/linux/extensions-customscript
Any configuration changes you want done post provisioning can be done leveraging this feature.
E.g. lets say, you want to domain join your VM, post provisioning, you would leverage a VM script extension.
12.15. Domain join your VM
This is helpful if you want to enable kerberos authentication of your VM.
Documentation
12.16. Azure Instance Metadata service
The Azure Instance Metadata Service provides information about running virtual machine instances that can be used to manage and configure your virtual machines. This includes information such as SKU, network configuration, and upcoming maintenance events. For more information on what type of information is available, see metadata categories.
Azure's Instance Metadata Service is a REST Endpoint accessible to all IaaS VMs created via the Azure Resource Manager. The endpoint is available at a well-known non-routable IP address (169.254.169.254) that can be accessed only from within the VM.
Documentation
Super important to keep track of maintenance events on your VMs and schedule the same.
12.17. Planned maintenance
Azure periodically performs updates to improve the reliability, performance, and security of the host infrastructure for virtual machines. These updates range from patching software components in the hosting environment (like operating system, hypervisor, and various agents deployed on the host), upgrading networking components, to hardware decommissioning. The majority of these updates are performed without any impact to the hosted virtual machines. However, there are cases where updates do have an impact:
- If the maintenance does not require a reboot, Azure uses in-place migration to pause the VM while the host is updated.
- If maintenance requires a reboot, you get a notice of when the maintenance is planned. In these cases, you'll also be given a time window where you can start the maintenance yourself, at a time that works for you.
Documentation Maintenance versus Downtime - the difference
Super important to keep track of maintenance events on your VMs and schedule the same.
12.18. Scheduled events
Scheduled Events is one of the subservices under the Azure Metadata Service. It is responsible for surfacing information regarding upcoming events (for example, reboot) so your application can prepare for them and limit disruption. It is available for all Azure Virtual Machine types including PaaS and IaaS. Scheduled Events gives your Virtual Machine time to perform preventive tasks to minimize the effect of an event. With Scheduled Events, you can take steps to limit the impact of platform-intiated maintenance or user-initiated actions on your service. Documentation
Super important to keep track of maintenance events on your VMs and schedule the same.
12.19. Secure your VM
The following are links related to security:
Disk encryption - details and tutorial
RBAC
On your Hadoop cluster, to prevent unauthorized access leaked into logs, you can encrypt all your OS and data disks with Azure Disk Encryption. You can prevent your data engineers from deleting VMs by leveraging RBAC.
12.20. Capture VM image
In my blog post 2, of the series, I covered, managed disks and touched on capturing VM images.
Here is a great tutorial that shows you how to capture a VM image.
12.21. Convert VM managed disks between standard and premium
You easily switch between the two options with minimal downtime based on your performance needs.
This is helpful in your lower environments - for e.g. when your engineers are doing development, maybe use standard disks and when its time to tune performance, switch to premium and then back.
Documentation
I just had a customer ask me today, if they can go with standard managed disks, validate the performance, and if they are dissatisfied, convert to premium tier. Totally do-able within single-digit minutes, irrespective of disk size.
12.22. Other useful links
Optimize network bandwidth in Linux VMs
Network bandwidth testing
High performance premium storage for VM disks
Optimizing application performance
Design for high performance
VM sizes
In conclusion...
This blog post covered Azure compute - and with the series, you have learned what you need to know from networking, storage and compute perspective for Hadoop on Azure, to get started. I plan to update the post to cover a couple other topics - backup and monitoring as time permits.
In my next blog, I cover Azure PaaS data services relevant to Hadoop.
Blog series:
Just enough Azure for Hadoop - Part 1 | Focuses on networking, other basics
Just enough Azure for Hadoop - Part 2 | Focuses on storage
Just enough Azure for Hadoop - Part 3 | Focuses on compute
Just enough Azure for Hadoop - Part 4 | Focuses on select Azure Data Services (PaaS)
Thanks to fellow Azure Data Solution Architect, Ryan Murphy for his review and feedback.