Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This blog is part 4 of a series that covers relevant Azure fundamentals - concepts/terminology you need to know, in the context of Hadoop. While the first three touched on Azure infrastructure aspects, this one covers Azure PaaS Data Services. There are a number of them - I have touched on the ones relevant. In some cases, the content is a copy-paste of Azure documentation (credit to our fine documentation team) - this blog post series hopefully serves as a one stop shop for those new to Azure and are thinking Hadoop.
This blog covers:
Section 13: HDFS compatible storage PaaS options - Azure Data Lake Store and Azure Blob Storage
Section 14: Hadoop offerings on Azure
Section 15: RDBMS PaaS
Section 16: Data copy/replication utilities
Here are links to the rest of the blog series: Just enough Azure for Hadoop - Part 1 | Focuses on networking
Just enough Azure for Hadoop - Part 2 | Focuses on storage
Just enough Azure for Hadoop - Part 3 | Focuses on compute
13. HDFS compatible storage PaaS
Azure offers two cost-effective options for secondary HDFS, both PaaS - Azure Blob Storage and Azure Data Lake Store
13.1. Azure Blob Storage - block blobs
Covered this in part 2 of the blog series.
13.2. Azure Data Lake Store (ADLS)
ADLS is like a server-less HDFS - there is no compute capability that comes with it - just like disks without a VM.
Think of it as a cost optimized solution for disks. It is Azure's massively scalable HDFS compatible PaaS. It is supported by Cloudera and Hortonworks as auxiliary HDFS, and is primary HDFS in HDInsight (see section below) in regions where available.
Use:
Secondary HDFS
Warm/cool/cold tier for cost optimization
Features:- Petabyte-scalable
- HDFS compatible data store
- Optimized for the cloud
- 99.99% availability SLA
- 24x7 support
Support:- Fully managed service with Microsoft support
Provisioning:- Portal and scripts
Security:
- Authentication: Azure Active Directory integration (oauth, no Kerberos support)
- Authorization: POSIX Role-Based Access Control
- Data Protection: Transparent Data Encryption (MSFT keys or BYOK)
- Auditability: Fine-grained
Integration into Apache Hadoop core:Hadoop 3.0
Hadoop distribution support for HDFS:Cloudera support with CDH 5.11.x and higher – secondary file system - specific workloads ONLY - MR, Spark, Hive, Impala
Hortonworks supported – secondary file system
HDInsight support for HDFS:
Primary HDFS
Note:
Not available in all data centers
How to use in IaaS clusters:
Refer Paige Liu's blog
Challenge:
For RBAC at ADLS level, lets say, with Apache Sentry or Apache Ranger - it would not work.
Hadoop supports only Kerberos for strong authentication, ADLS supports oauth.
So, currently there is no 1:1 mapping between a Hadoop Kerberos user principal to ADLS user principal.
All Hadoop user principals would read/write as a generic user principal (the ADLS service principal) to HDFS.
HDInsight has solved this problem.
14. Hadoop offerings on Azure
We have 4 offerings on Azure -
14.1. Cloudera
(1) Cloudera - for long running clusters
IaaS, Cloudera Director for provisioning
(2) Cloudera Altus - for transient workloads based data-engineering clusters
IaaS, in beta
Provision, run your jobs, decommission
Azure blog storage not supported - just managed disks and ADLS
Documentation
14.2. Hortonworks
(1) Hortonworks Data Platform Enterprise - long running clusters
IaaS, Cloudbreak for provisioning
(2) HDInsight - workload based clusters
Microsoft PaaS
14.3. MapR
IaaS
15. RDBMS PaaS
Azure has three flavors of true RDBMS PaaS. Azure SQL Database, MySQL and PostgreSQL.
Since all the major Hadoop distributions support MySQL and PostgreSQL, this section will cover only the same.
15.1 Azure database for PostgreSQL
Azure Database for PostgreSQL is a relational database service based on the open source PostgreSQL database engine. It is a fully managed database as a service offering capable of handling mission-critical workloads with predictable performance, security, high availability, and dynamic scalability.
There is a concept of logical database server at provision time. It is the same database server construct like in the on-premises world and exposes access and features at the server-level.
An Azure Database for PostgreSQL server:
- Is created within an Azure subscription.
- Is the parent resource for databases.
- Provides a namespace for databases.
- Is a container with strong lifetime semantics - delete a server and it deletes the contained databases.
- Collocates resources in a region.
- Provides a connection endpoint for server and database access (.postgresql.database.azure.com).
- Provides the scope for management policies that apply to its databases: login, firewall, users, roles, configurations, etc.
- Is available in multiple versions. For more information, see Supported PostgreSQL database versions.
- Is extensible by users. For more information, see PostgreSQL extensions.
Authentication:
| Authentication and authorization | Azure Database for PostgreSQL server supports native PostgreSQL authentication. You can connect and authenticate to server with the server's admin login. |
| Protocol | The service supports a message-based protocol used by PostgreSQL. |
| TCP/IP | The protocol is supported over TCP/IP, and over Unix-domain sockets. |
| Firewall | To help protect your data, a firewall rule prevents all access to your database server and to its databases, until you specify which computers have permission. See Azure Database for PostgreSQL Server firewall rules. |
Encryption:
At rest: AES 256 bit with Microsoft managed keys secured in Azure Key Vault
In transit: Allowed only over SSL
Versions, patching and upgrades:
Documentation
PostgreSQL extensions:
Provide the ability to extend the functionality of your database using extensions. Extensions allow for bundling multiple related SQL objects together in a single package that can be loaded or removed from your database with a single command. After being loaded in the database, extensions can function as do built-in features.
Documentation
High-Availability:
At a data level, 3 replicas are maintained and served up seamlessly.
At a compute level, if a node-level interruption occurs, the database server automatically creates a new node and attaches data storage to the new node. Any active connections are dropped and any inflight transactions are not committed.
Documentation
Scale up/down:
When an Azure Database for PostgreSQL is scaled up or down, a new server instance with the specified size is created. The existing data storage is detached from the original instance, and attached to the new instance.
During the scale operation, an interruption to the database connections occurs. The client applications are disconnected, and open uncommitted transactions are canceled. Once the client application retries the connection, or makes a new connection, the gateway directs the connection to the newly sized instance.
Documentation
Pricing tiers Compute units - A Compute Unit is a blended measure of CPU and memory resources available for a database
Limits
15.2. Azure Database for MySQL
Azure Database for MySQL is a relational database service in the Microsoft cloud based on the MySQL Community Edition database engine. This service is in public preview. Azure Database for MySQL delivers:+
- Built-in high availability with no additional cost.
- Predictable performance, using inclusive pay-as-you-go pricing.
- Scale on the fly within seconds.
- Secured to protect sensitive data at-rest and in-motion.
- Automatic backups and point-in-time-restore for up to 35 days.
- Enterprise-grade security and compliance.
Azure Database for MySQL Database Server:
It is the same MySQL server construct that you may be familiar with in the on-premises world
- Is created within an Azure subscription.
- Is the parent resource for databases.
- Provides a namespace for databases.
- Is a container with strong lifetime semantics - delete a server and it deletes the contained databases.
- Collocates resources in a region.
- Provides a connection endpoint for server and database access.
- Provides the scope for management policies that apply to its databases: login, firewall, users, roles, configurations, etc.
- Is available in multiple versions. For more information, see Supported Azure Database for MySQL database versions.
Authentication:
| Authentication and authorization | Azure Database for MySQL server supports native MySQL authentication. You can connect and authenticate to a server with the server's admin login. |
| Protocol | The service supports a message-based protocol used by MySQL. |
| TCP/IP | The protocol is supported over TCP/IP and over Unix-domain sockets. |
| Firewall | To help protect your data, a firewall rule prevents all access to your database server, or to its databases, until you specify which computers have permission. See Azure Database for MySQL Server firewall rules. |
| SSL | The service supports enforcing SSL connections between your applications and your database server. See Configure SSL connectivity in your application to securely connect to Azure Database for MySQL. |
Encryption:
At rest: AES 256 bit with Microsoft managed keys secured in Azure Key Vault
In transit: Allowed only over SSL
Supported versions and upgrades: Documentation
High-Availability:
At a data level, 3 replicas are maintained and served up seamlessly.
At a compute level, if a node-level interruption occurs, the database server automatically creates a new node and attaches data storage to the new node. Any active connections are dropped and any inflight transactions are not committed.
Documentation
Scale up/down:
When an Azure Database for MySQL is scaled up or down, a new server instance with the specified size is created. The existing data storage is detached from the original instance, and attached to the new instance.
During the scale operation, an interruption to the database connections occurs. The client applications are disconnected, and open uncommitted transactions are canceled. Once the client application retries the connection, or makes a new connection, the gateway directs the connection to the newly sized instance.
Documentation
Firewall rules and configuring SSL: Firewall rules | Configuring SSL
16. Data copy/Replication utilities - on-prem to Azure
16.1. azCopy
azCopy on Linux is a command-line utility designed for copying data to and from Azure Blob and File storage using simple commands with optimal performance. You can copy data from one object to another within your storage account, or between storage accounts. You can use this for copying one-off small files to Azure from on-premise, or between your storage account and your Linux VMs.
Documentation
16.2. Azure Import/Export
Consider using Azure Import/Export service when uploading or downloading data over the network is too slow, or getting additional network bandwidth is cost-prohibitive. You have to use BitLocker Drive Encryption to protect your data on the disks.
You can use this service in scenarios such as:
- Migrating data to the cloud: Move large amounts of data to Azure quickly and cost effectively.
- Content distribution: Quickly send data to your customer sites.
- Backup: Take backups of your on-premises data to store in Azure blob storage.
- Data recovery: Recover large amount of data stored in storage and have it delivered to your on-premises location.
Inside an import job
At a high level, an import job involves the following steps:
- Determine the data to be imported, and the number of drives you will need.
- Identify the destination blob or file location for your data in Azure storage.
- Use the WAImportExport Tool to copy your data to one or more hard disk drives and encrypt them with BitLocker.
- Create an import job in your target storage account using the Azure portal or the Import/Export REST API. If using the Azure portal, upload the drive journal files.
- Provide the return address and carrier account number to be used for shipping the drives back to you.
- Ship the hard disk drives to the shipping address provided during job creation.
- Update the delivery tracking number in the import job details and submit the import job.
- Drives are received and processed at the Azure data center.
- Drives are shipped using your carrier account to the return address provided in the import job.
Here is a pictorial overview of the import process from Azure documentation-
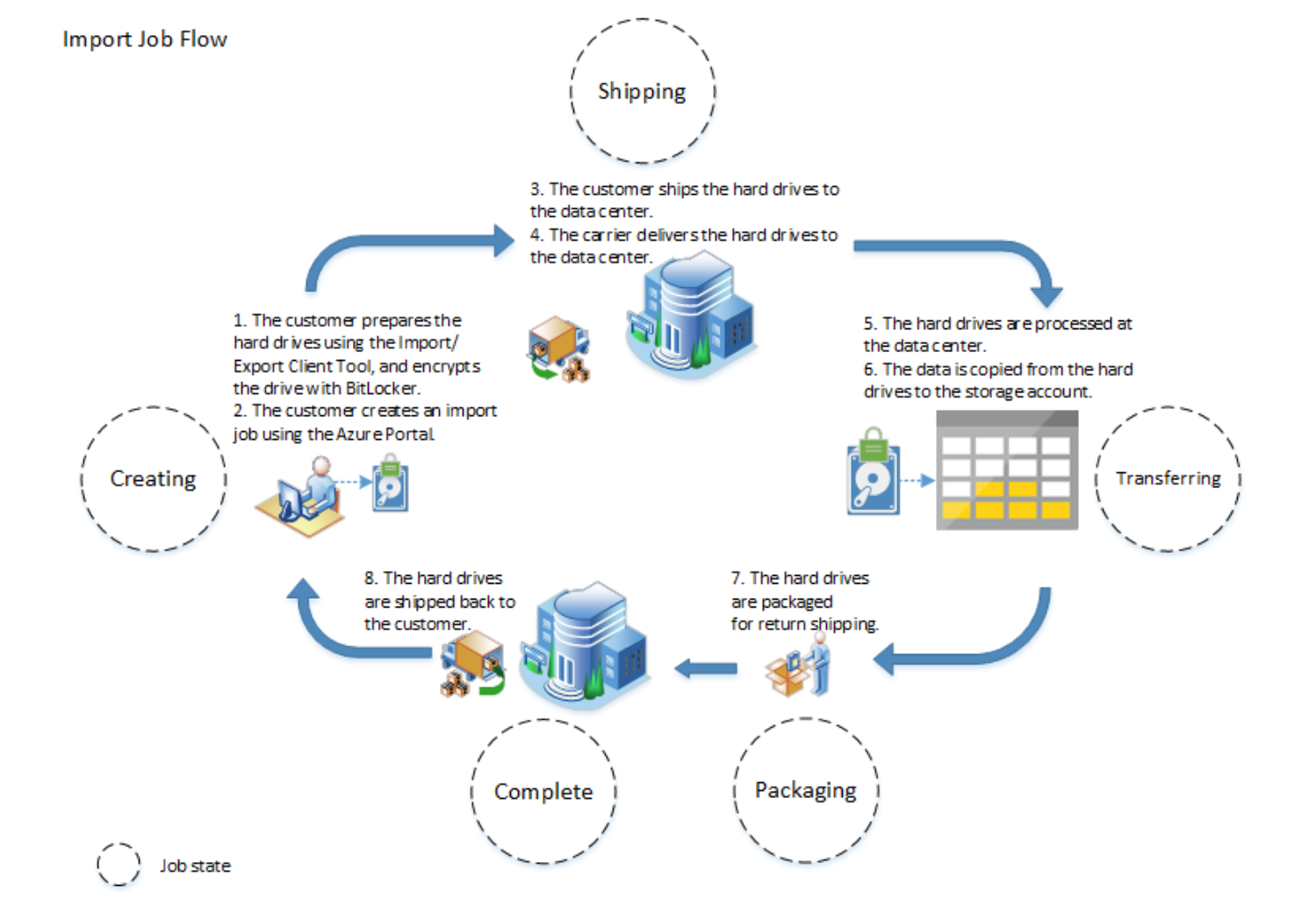
To learn more - read the Azure Import/Export documentation.
16,3. Azure Data Box
The Azure Data Box provides a secure, tamper-resistant method for quick and simple transfer, TBs to PBs of your data to Azure. You can order the Data Box through the Azure portal. Easily connect it to your existing network, then load your data onto the Data Box using standard NAS protocols (SMB/CIFS). Your data is automatically protected using 256-AES encryption. The Data Box is returned to the Azure Data Center to be uploaded to Azure, then the device is securely erased.
This is in preview.
Documentation
16.4. Third party services
There are several third party services that help replicate data between on-premise and Azure. E.g. Attunity, WANDisco
In summary..
We have a rich offering in the networking, storage and compute space to stand up secure Hadoop Iaas clusters on Azure, in minutes, and with the ability to scale up/down as needed, quickly as well. I hope this blog series makes your Hadoop on Azure journey a little less cumbersome.
Blog series:
Just enough Azure for Hadoop - Part 1 | Focuses on networking, other basics
Just enough Azure for Hadoop - Part 2 | Focuses on storage
Just enough Azure for Hadoop - Part 3 | Focuses on compute
Just enough Azure for Hadoop - Part 4 | Focuses on select Azure Data Services (PaaS)
Thanks to fellow Azure Data Solution Architect, Ryan Murphy for his review and feedback.