Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Both the serializable and snapshot isolation levels provide a read consistent view of the database to all transactions. In either of these isolation levels, a transaction can only read data that has been committed. Moreover, a transaction can read the same data multiple times without ever observing any concurrent transactions making changes to this data. The unexpected read committed and repeatable read results that I demonstrated in my prior few posts are not possible in serializable or snapshot isolation level.
Notice that I used the phrase "without ever observingany ... changes." This choice of words is deliberate. In serializable isolation level, SQL Server acquires key range locks and holds them until the end of the transaction. A key range lock ensures that, once a transaction reads data, no other transaction can alter that data - not even to insert phantom rows - until the transaction holding the lock completes. In snapshot isolation level, SQL Server does not acquire any locks. Thus, it is possible for a concurrent transaction to modify data that a second transaction has already read. The second transaction simply does not observe the changes and continues to read an old copy of the data.
Serializable isolation level relies on pessimistic concurrency control. It guarantees consistency by assuming that two transactions might try to update the same data and uses locks to ensure that they do not but at a cost of reduced concurrency - one transaction must wait for the other to complete and two transactions can deadlock. Snapshot isolation level relies on optimistic concurrency control. It allows transactions to proceed without locks and with maximum concurrency, but may need to fail and rollback a transaction if two transactions attempt to modify the same data at the same time.
It is clear there are differences in the level of concurrency that can be achieved and in the failures (deadlocks vs. update conflicts) that are possible with the serializable and snapshot isolation levels.
How about transaction isolation? How do serializable and snapshot differ in terms of the transaction isolation that they confer? It is simple to understand serializable. For the outcome of two transactions to be considered serializable, it must be possible to achieve this outcome by running one transaction at a time in some order.
Snapshot does not guarantee this level of isolation. A few years ago, Jim Gray shared with me the following excellent example of the difference. Imagine that we have a bag containing a mixture of white and black marbles. Suppose that we want to run two transactions. One transaction turns each of the white marbles into black marbles. The second transaction turns each of the black marbles into white marbles. If we run these transactions under serializable isolation, we must run them one at a time. The first transaction will leave a bag with marbles of only one color. After that, the second transaction will change all of these marbles to the other color. There are only two possible outcomes: a bag with only white marbles or a bag with only black marbles.
If we run these transactions under snapshot isolation, there is a third outcome that is not possible under serializable isolation. Each transaction can simultaneously take a snapshot of the bag of marbles as it exists before we make any changes. Now one transaction finds the white marbles and turns them into black marbles. At the same time, the other transactions finds the black marbles - but only those marbles that where black when we took the snapshot - not those marbles that the first transaction changed to black - and turns them into white marbles. In the end, we still have a mixed bag of marbles with some white and some black. In fact, we have precisely switched each marble.
The following graphic illustrates the difference:
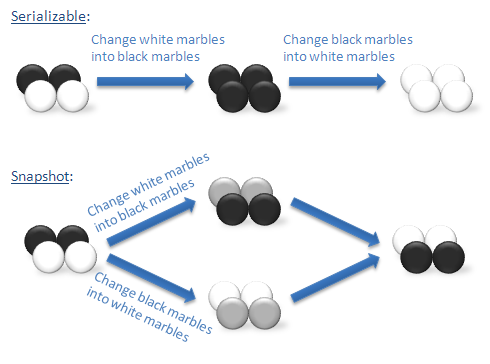
We can demonstrate this outcome using SQL Server. Note that snapshot isolation is only available in SQL Server 2005 and must be explicitly enabled on your database:
alter database database_name set allow_snapshot_isolation on
Begin by creating a simple table with two rows representing two marbles:
create table marbles (id int primary key, color char(5))
insert marbles values(1, 'Black')
insert marbles values(2, 'White')
Next, in session 1 begin a snaphot transaction:
set transaction isolation level snapshot
begin tran
update marbles set color = 'White' where color = 'Black'
Now, before committing the changes, run the following in session 2:
set transaction isolation level snapshot
begin tran
update marbles set color = 'Black' where color = 'White'
commit tran
Finally, commit the transaction in session 1 and check the data in the table:
commit tran
select * from marbles
Here are the results:
id color
----------- -----
1 White
2 Black
As you can see marble 1 which started out black is now white and marble 2 which started out white is now black. If you try this same experiment with serializable isolation, one transaction will wait for the other to complete and, depending on the order, both marbles will end up either white or black.
Comments
Anonymous
May 20, 2007
Interesting. I found the example very illustrative!Anonymous
December 03, 2007
В этом посте я собрал, перевел и адаптировал под Microsoft SQL Server 2005 (гдеAnonymous
January 23, 2008
Can you tell me if the application of these isolation levels is affected by compatibility levels ?I have a DB in SQL 2005 running at level 80. Will it be able to support snapshot isolation ?Anonymous
January 28, 2008
Snapshot isolation is available at compatibility level 80, but you do need to enable it for the database using the ALTER DATABASE database_name SET ALLOW_SNAPSHOT_ISOLATION ON statement.Anonymous
October 27, 2011
You lost me in the second sentance: "In either of these isolation levels, a transaction can only read data that has been committed.". I assume you mean that another transaction (i.e. not my transaction which is operating on the Serializable level) cannot read data that my transaction has not committed. Why do I find that EVERY article I read on this subject fails to make this distinction in perspective? You might think that the meaning is obvious, but in my experience newcomers are confused about who is applying the locks and how isolation levels actually work.Anonymous
October 27, 2011
Hi Tom, What I meant is that a transaction X running at either serializable or snapshot isolation level cannot read data written by another transaction Y that has not yet committed. Whether transaction Y can read data written by transaction X depends solely on the isolation level of transaction Y. If transaction Y is running at the read uncommitted isolation level it can read uncommitted data; if it is running at any other isolation level, it cannot. I'm sorry that you found my post confusing. Thanks for the feedback. CraigAnonymous
January 16, 2012
so... can txn X read data wrtten by itself before commit ?Anonymous
January 17, 2012
Yes, a snapshot transaction can always read its own changes before commit.Anonymous
September 16, 2012
Absolutly perfect article! Thank you!Anonymous
August 29, 2013
Hello Craig, Either i did not understand or you did not explained how values changed in result.If you can do that ,it would make your article excellent oneAnonymous
August 29, 2013
The comment has been removedAnonymous
August 30, 2013
Re: how values changed in the result. The marbles table started with two rows (id, color) = { (1, 'Black'), (2, 'White') } and (in the snapshot example) ended with { (1, 'White'), (2, 'Black') }. This result is possible with snapshot isolation but is NOT possible with serializable. Re: "a transaction can read the same data multiple times without ever observing any concurrent transactions making changes to this data." This statement is true for both snapshot and serializable. HTH, CraigAnonymous
December 04, 2013
Hi Craig, great article. I wanted more explanation on the snapshot sequence of events --- let me know if I have this right. (1) The first transaction that is not committed until the end (tran 1) updates black marbles to white marbles. (2) I think it is an important step here to mention that a snapshot isolation read after this transaction in another session will read these marbles as black still since we are under snapshot isolation and the row version will be black. (3) Another session (tran 2) updates (in snapshot isolation) the white marbles to black marbles. Again, I think it's helpful here to state that the update first finds all white marbles and according to the row version from tran 1, the black marbles are still black. So, tran 2 updates white marbles to black marbles and commits. (4) At this point, I should note that another snapshot isolation read, say in session 3 would read all black marbles. It would find the black marbles from the row version in tran 1 and it would find the black marbles from the committed tran 2 update where white turned to black. So reads at this point have all marbles as black. (5) When the tran 1 is finally committed, it means the row version of black goes away and those marbles would now read as white. So alas, we now have 2 white marbles and 2 black marbles.Anonymous
December 04, 2013
In the last step above (5), I meant 1 white marble and 1 black marble. Looking at the picture I saw 2 but in the example only 1 of each were inserted.Anonymous
December 04, 2013
Just confirmed the steps 1-5 in testingAnonymous
December 08, 2013
Thank you for that nice example. It got me thinking about how the serializable isolation level is actually implemented and I'm a bit puzzled. I wrote a question on stack overflow about it here: stackoverflow.com/.../how-are-serializable-transactions-implemented I used your example and I also linked to this blog post there.Anonymous
July 29, 2014
there is a question regarding the illustration. Say the bag had 2 white , 2 black and 2 orage marbels. Transaction 1 converts white to black and orange to green marbles. transaction 2 converts black to white and orange to red marbles. What would be the outcome in case these two transactions were run under the snapshot isolation level and cimmitted at precisely the same time?Anonymous
July 31, 2014
The comment has been removedAnonymous
October 30, 2014
Very nice article. Cheers.Anonymous
December 09, 2014
Hello Craig, I ran the code example that you posted but I'm not getting the same results as you. I'm using MS SQL 2012 if that makes a difference. This is the code that I ran. USE [MS-70-461_TEST]; GO -- SNAPSHOT ISOLATION must be explicitly enabled on your database: ALTER DATABASE [MS-70-461_TEST] SET ALLOW_SNAPSHOT_ISOLATION ON -- Begin by creating a simple table with two rows representing two marbles: IF OBJECT_ID('Marbles', 'U') IS NOT NULL DROP TABLE Marbles; GO CREATE TABLE Marbles ( id int primary key ,color char(5) ); GO INSERT INTO Marbles VALUES (1, 'BLACK') ,(2, 'WHITE'); GO -- Next, in session 1 begin a snapshot transaction: SET TRANSACTION ISOLATION LEVEL SNAPSHOT BEGIN TRAN UPDATE Marbles SET color = 'WHITE' WHERE color = 'BLACK'; GO -- Now, before committing the changes, run the following in session 2: SET TRANSACTION ISOLATION LEVEL SNAPSHOT BEGIN TRAN UPDATE Marbles SET color = 'BLACK' WHERE color = 'WHITE' COMMIT TRAN; GO -- Finally, commit the transaction in session 1 and check the data in the table: COMMIT TRAN SELECT * FROM MarblesAnonymous
December 09, 2014
What result do you get? Did you remember to run the two update transactions in two different sessions? For example, using Management Studio, open two connections in separate tabs and run one update transaction in each tab. HTH CraigAnonymous
February 27, 2015
Simple, clear, concise and very instructive. This article should be elected "Best SQL Server Article" for ever Thank you Graig