Virtual Clusters: A Tamagotchi for Your Network!
First of all, if you missed out on the whole digital pet revolution, a Tamagotchi is a virtual pet. It comes in a small computer (usually attached to a keychain) and requires attention to keep it from dying. It needs to be fed, played with, and cleaned up after, all accomplished via buttons on the computer. In exchange, it provides hours of entertainment for its owner (as much entertainment as a tiny little LCD screen utilizing block animation could provide). Now, I will be the first to tell you that a failover cluster probably isn't going to provide "hours of entertainment" (unless, of course, you're clustering your Call of Duty server). But, with some care and maintenance, it is going to ensure high availability of your clustered servers, allowing you to concentrate your attention somewhere else (like on your Tamagotchi, for instance). I gave you an overview of clustering and virtualization in my last post, but I want to delve deeper into how virtualization and clustering can work together to provide you with an easy-to-use, effective solution.
One of the concerns around creating a failover cluster in Windows is the need to use similar hardware for all of the nodes within the cluster. (This is the Microsoft recommended method of creating a failover cluster.) As my friend Jamie pointed out (after reading my last post -- he happened to be on vacation in the Dominican Republic at the time. That's a pretty dedicated blog reader right there!), one of the biggest advantages of using clustering with virtualization is that virtual machines, by default, are "similar." In fact, all of the machines created in Hyper-V have the same virtual hardware specs, regardless of what physical hardware the host OS is running on. Thus, planning a virtual cluster eliminates the "similar hardware" requirement.
One of the main concerns when building a failover cluster is, "Where do I store my files?" Since a virtual machine is really just a file stored on a hard drive, it becomes important to consider not only where you will store data used by the machine, but where you will store the machine file itself.
There are a couple different ways to create virtual clusters, depending on your needs. You can cluster virtual machines together to create a cluster of virtual machines or you can cluster physical hosts together to make a single virtual machine highly available. Let's take a look at some diagrams to understand exactly what the differences are.
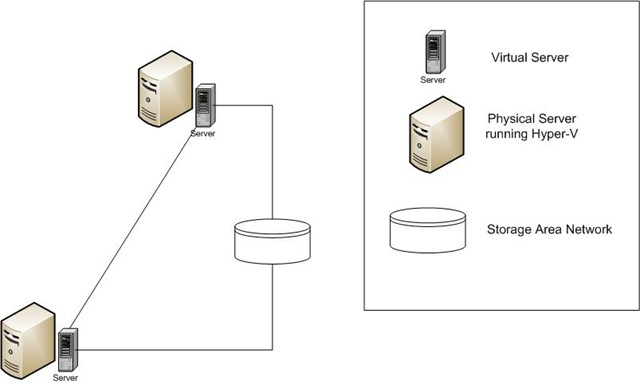
In this picture, we can see that two virtual machines are connected to a SAN (Storage Area Network). The virtual machine files are stored locally on each of their respective physical hosts. The data being used by the virtual machines (the data for applications running on the machines, for instance) is hosted on the shared SAN. The two virtual machines are clustered together. When one of the virtual machines fails, the other takes over, leveraging the data stored on the shared drive. In this way, the applications running on the virtual machines are highly available.
The second way to handle this scenario is shown in the following diagram.

In last week's post, I implied that clustering two physical machines together could potentially cause a problem, as the physical machines are monitored by the cluster, but not the virtual machines. (Actually, I may have come out and said it, rather than implied it.) The truth is, that's only partly true. My goal was to help you understand the basics of clustering before getting down into the details. It is possible to have a workable solution using clustered physical machines and virtual machine failover, as shown in the diagram above. In this case, two physical servers are clustered together and are both connected to the SAN. The virtual machine, in this case, is stored on the SAN, rather than on one of the physical machines' local drives. The virtual machine is set, in the cluster management tool, to be a highly available "application." Thus, if one of the physical machines fail, the other machine will automatically launch the shared virtual machine.
In a manual failover (such as for planned maintenance on the physical machines), the virtual machine will actually be saved, shut down, transferred, and started again -- all with one click in the cluster management console. It is a quick process (the time it takes is dependent upon factors such as amount of virtual memory to be saved to disk) and allows the state of the virtual machine to be transferred from one host to the other. In the event of an actual disaster (and an automated failover), the state would not be saved (as the physical hardware would've failed at this point) and the virtual machine would start clean (as if it had been rebooted) from the files on the shared SAN device.
Each of these scenarios has its benefits. They are semi-interchangeable (they have functionality overlap), but as we dive further, you can see where one is more appropriate for certain situations. Think, for instance, of licensing. Which of the following scenarios do you think involves more Windows licenses?
Diagram A

Diagram B

In both scenarios, we have 6 highly available machines. We are using virtualization to create the machines. But as you can see, the results are completely different. In Diagram A, we're looking at 8 instances of Windows Server and one cluster to manage. In Diagram B, we have 14 instances of Windows Server running and 6 individual clusters to manage! Clearly, Diagram A is the superior solution, right? Not always. Imagine, for instance, that we have two servers which have been removed from production duty as part of our virtualization consolidation. These two servers are not remotely similar. One is an AMD machine and the other is an Intel machine. Both are capable of running Server 2008 and Hyper-V, but that's where the similarities end. Are they going to be acceptable for solution A? Maybe. Remember, though, that similar hardware is important in a cluster. Will it work anyway? Maybe. Is it supported? Maybe not. But, in the solution in Diagram B, we don't need them to be similar. Those machines can be anything capable of running Server 2008 and Hyper-V. As long as they each have enough memory and processing power for the virtual machines which will be hosted on them, they will work for scenario B.
But, you mentioned licensing earlier. Certainly, Diagram A represents the less expensive route from a licensing standpoint.
Ah.... you were paying attention! Good. I did mention licensing. But, is Diagram A really less expensive? Consider, for instance, that you really did free up two servers during your server consolidation to virtualization. And suppose each of those servers is running Windows Server 2008 Datacenter edition... that allows for unlimited virtual instances to be hosted. Under those circumstances, licensing wouldn't enter into the picture at all. Now, scenario A may be the costlier, as you may need to purchase a server to match one you have in order to create a supported cluster.
This is like a philosophical question - there is no "one truth." In this case, several factors will dictate which of these solutions best meets your needs, taking all considerations into account.
Stay tuned for the next exciting episode!
Technorati Tags: virtualization,hyper-v,Microsoft,Windows,Server 2008,clustering,failover
Comments
Anonymous
January 01, 2003
While iSCSI might have the little "i" so common in Apple's naming schemes, it has nothing toAnonymous
July 30, 2015
very nice post
http://www.whatsapprank.com/2015/06/new-best-whatsapp-status-quotes-messages.htmlAnonymous
August 02, 2015
http://www.whatsapprank.com/Anonymous
October 01, 2015
thanks for the nice post
http://www.easypnrstatus.inAnonymous
November 12, 2015
http://serc.nc.hcc.edu.tw/xoops2/userinfo.php?uid=1587999
http://tinychat.com/fast9te9ch
http://wsap.edu.pl/osrodkikariery/forumdyskusyjne/profile.php?mode=viewprofile&u=19886
http://volunteer.cs.und.edu/csg/view_profile.php?userid=102442
http://visual.ly/users/fast9te9ch
http://www.acne-treatment-skin-care.info/author/fast9te9ch
http://weheartit.com/fast9te9ch
http://forums.cat.com/t5/user/viewprofilepage/user-id/38068