Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
執筆者: Yossi Yossifon (Senior Program Manager, Application Insights)
このポストは、4 月 11 日に投稿された Near Real Time Proactive Diagnostics alerts on abnormal failure rates の翻訳です。
Near Real Time Proactive Diagnostics に、Web アプリが突然中断した場合やパフォーマンスが急激に低下した場合にそのことを通知する自動アラートが追加されました。たとえば、要求の失敗率が異常に上昇した場合は数分以内に通知されるため、多くのユーザーに影響が及ぶ前に問題を調査することができます。
最大の利点としては、アプリに Visual Studio Application Insights をセットアップし、最小限の要求テレメトリを送信していれば、何も行わなくてもアラートが設定されるという点です。この機能は皆様の .NET アプリや Java Web アプリがクラウドでホストされていても、独自のサーバーでホストされていても使用することが可能で、アプリの失敗率の正常なパターンを自動的に学習し、異常な上昇が発生した場合にアラートを送信します。詳細についてはこちらのページをご覧ください。
診断の詳細情報を提示
このメール アラートの機能は、問題の警告だけではありません。詳細な診断情報が含まれ、応答コード、操作名、アプリケーションのバージョンなど、失敗した要求に共通するプロパティが明確に提示されます。また、問題に関連する場合は、例外、トレース、依存関係の呼び出しの情報も含まれます。メールのリンクをクリックすると、失敗した特定の要求を Application Insights ポータルで直接確認できるほか、このページから依存関係エラー、例外、コール スタックなどの関連するテレメトリを表示できます。
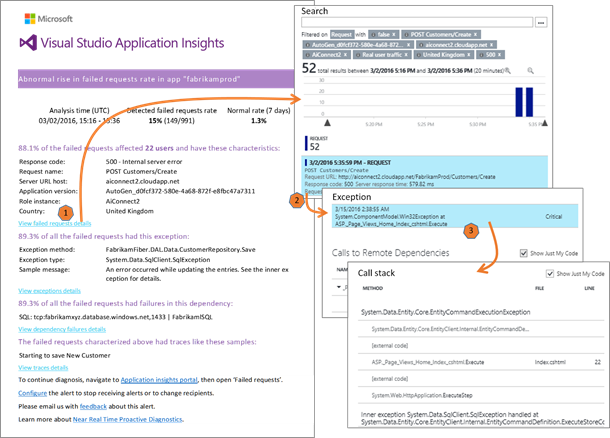
アラートのメリット
このアラートには 2 つの大きなメリットがあります。1 つはアプリの動作への自動適応、もう 1 つは適切な診断情報の提供です。
皆様もご存知のとおり、これまでも任意のメトリックのしきい値を選択してアラートを設定することが可能でした。しかし、この方法では各メトリックの適切なしきい値を特定することが困難だという問題がありました。システムがどのような状態であれば正常であるかを正しく把握できるようになるまでには、ある程度時間がかかります。しかも、理想的なしきい値はというのは、ケースバイケースで異なります。たとえば、負荷が発生すると失敗率は変化しますし、失敗率は要求ごとに異なります。このように、理想的なしきい値はさまざまな要因の影響を受けます。こうした経験を経ることで、異常な動作とは何かを徐々に理解していき、誤検知の件数を抑えながら異常を検出できる最適なしきい値を特定するしかありません。一方、新たな機能が追加された Proactive Diagnostics では、皆様に代わってこのような学習を自動的に行い、さまざまな要因を考慮して想定外の上昇が発生した場合にアラートが送信されます。
異常を検出し、問題を把握できたとしても、トリアージを行うためにはさらに多くの情報が必要になります。問題の規模と緊急度はどの程度か、どれだけのユーザーが影響を受けているかなど、一部の情報はダッシュボードから確認できる場合もありますが、多くの情報を正確に把握するにはテレメトリの分析を実行する必要があります。
問題の原因は、コードのバグ、構成、ストレージ、そのアプリで使用している他の外部サービス (データベース、REST サービスなど) など多岐にわたるため、問題の診断は困難な場合もあります。しかし、Proactive Diagnostics のアラートでは、異常に関する情報が自動的に収集され、原因である可能性が高い要因がわかりやすく提示されます。
Near Real Time Proactive Diagnostics のアラートを利用すると、サービスの中断やパフォーマンスの低下を数分で検出することができ、根本原因の簡単かつ短時間で診断するための補足情報を手に入れられます。
新たに追加してほしい機能や機能強化のご要望がありましたら Application Insights の UserVoice ページ (英語) までお寄せください。またご不明な点は Application Insights フォーラム (英語) までお問い合わせください。